







abinet
半监督!
ABINet的三个主要特点就是自治性(Autonomous)、双向性(Bidirectional)以及迭代性(Iterative)。
总体上的思想就是从NLP字符级别拼写矫正的语言建模角度来思考场景文字识别问题,尤其是针对图像质量退化的这种场景文字识别。
参考
https://zhuanlan.zhihu.com/p/356745766
CRNN
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。
master
基于注意力的场景文本识别器存在注意力漂移问题,因为在基于 RNN 的局部注意力机制下,编码特征之间的高度相似性会导致注意力混乱。此外,基于RNN的方法由于并行性差而效率低。为了克服这些问题,我们提出了 MASTER,这是一种基于自注意力的场景文本识别器,它 (1) 不仅对输入-输出注意力进行编码,而且还学习自注意力,它在编码器内部编码特征-特征和目标-目标关系,以及解码器和 (2) 学习更强大和鲁棒的空间失真中间表示,(3) 训练并行度高,训练效率高,内存缓存机制高效,推理速度快。在各种基准上进行的大量实验证明了我们的 MASTER 在规则和不规则场景文本上的卓越性能。
NRTR
NRTR:用于场景文本识别的无重复序列到序列模型
RobustScanner
基于注意力的编码器-解码器框架最近在场景文本识别方面取得了令人瞩目的成果,并且随着识别质量的提高,出现了许多变体。然而,它在无上下文文本(例如,随机字符序列)上表现不佳,这在大多数实际应用场景中是不可接受的。在本文中,我们首先深入研究了解码器的解码过程。我们凭经验发现,具有代表性的字符级序列解码器不仅利用上下文信息,还利用位置信息。现有方法严重依赖的上下文信息会导致注意力漂移问题。为了抑制这种副作用,我们提出了一种新的位置增强分支,并将其输出与解码器注意模块的输出动态融合以进行场景文本识别。具体来说,它包含一个位置感知模块,使编码器能够输出编码它们自己的空间位置的特征向量,以及一个仅使用位置线索(即当前解码时间步长)估计瞥见的注意模块。通过逐元素门机制进行动态融合以获得更强大的特征。从理论上讲,我们提出的方法,称为 {RobustScanner},以上下文和位置线索之间的动态比率解码单个字符,并在解码具有稀缺上下文的序列时利用更多位置字符,因此具有鲁棒性和实用性。根据经验,它在流行的常规和不规则文本识别基准上取得了新的最先进的结果,而在无上下文基准上的性能没有太大下降.
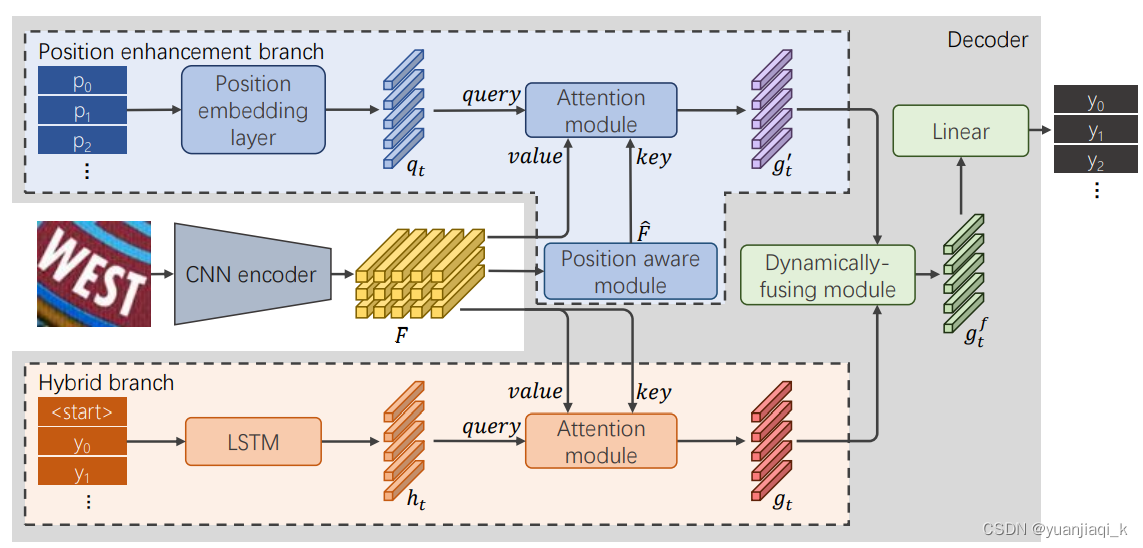
RobustScanner的体系结构。给定一个输入图像,我们首先通过CNN编码器提取它的feature map F。然后将F送入混合分支和位置增强分支,得到闪现gt和g
0 t,在预测第t个字符之前,由动态融合模块进行动态融合。
python mmocr/utils/ocr.py demo/test --det-config configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py --det-ckpt workplace/det/latest.pth --re
cog-config configs/textrecog/robust_scanner/mytest.py --recog-ckpt workplace/recog/latest.pth --print-result --imshow














 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









