










论文标题:ABINet+:Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
代码:https://github.com/FangShancheng/ABINet
链接:https://arxiv.org/abs/2103.06495
一、Abstract
However, how to effectively model linguistic rules in end-to-end deep networks remains a research challenge.
Reason:
隐式语言建模;implicitly language modeling
单向特征表示;unidirectional feature representation
有噪声输入的语言模型;language model with noise input
因此作者提出:
block gradient flow between vision and language models to enforce explicitly language modeling。 阻断视觉模型与语言模型之间的梯度流来实现显式语言建模
bidirectional cloze network (BCN) as the language model。双向网络(BCN)作为语言模型
execution manner of iterative correction。迭代修正减少噪声
二、Introductions
Autonomous:将自主原理应用于场景文本识别(STR),将识别模型解耦为视觉模型(VM)和语言模型(LM)。子模型作为独立的功能单元。LMs是否以及如何学习字符关系是不可知的。此外,这种方法对于从大规模无标签文本中直接预训练LM获取丰富的先验知识是不可行的。
Bidirectional:用双向LM模型可捕获两倍的信息量。构建双向模型的一种直接方法是合并从左到右的模型和从右到左的模型。然而,由于其语言特征是单向表征的,因此功能较弱,同时在计算和参数上都要花费两倍的成本。BERT引入了通过mask textual token modeling的深度双向表示,直接将BERT应用于STR需要mask文本中所有字符,而这是非常昂贵的,因为每次只能屏蔽一个字符。
Iterative:采用迭代执行的LMs可以从视觉和语言线索中优化预测,这是现有方法所没有探索的。为适应Transformer架构,放弃自回归,采用并行预测来提高效率。然而,在并行预测中仍然存在噪声输入,虚拟机输出的误差直接影响LM的精度。
首先,通过阻塞梯度流(BGF)在VM和LM之间探索了一种解耦方法(图1b),该方法强制LM显式地学习语言规则。此外,VM和LM都是自治单元,可以分别从图像和文本进行预训练。其次,设计了一个新的双向完形网络(BCN)作为LM,消除了两个单向模型组合的困境(图1c)。BCN同时以左右上下文为条件,通过指定注意掩码来控制两边字符的访问。此外,为了防止信息泄露,不允许跨步骤访问。第三,我们提出了一种LM迭代修正的执行方式(图1b)。通过将ABINet的输出反复输入LM,可以逐步改进预测,并在一定程度上缓解长度不对齐的问题。
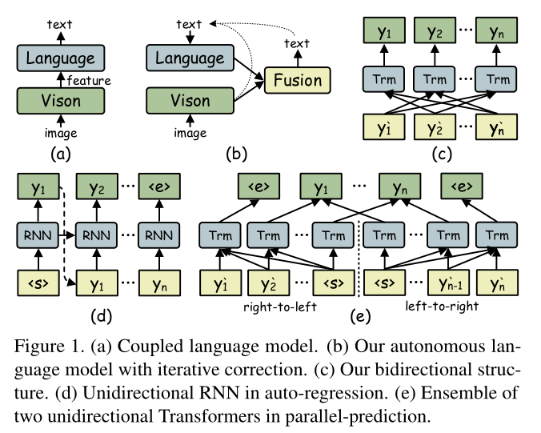
三、Proposed Method
1、 Vision Model

ResNet + position attention module 。
ResNet :总共5个残差块,在第1块和第3块之后进行下采样。
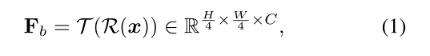
position attention module将视觉特征并行转录为字符概率。
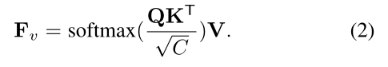
Q为字符顺序的位置编码,T是字符序列的长度,K为UNet网络,V为自映射。
2、Language Model
Autonomous Strategy
1)将LM视为一个独立的拼写纠正模型,将字符的概率向量作为期望字符的输入和输出概率分布。2)训练梯度流在输入向量处被阻塞(BGF)。3) LM可以与未标记的文本数据分开训练。
Bidirectional Representation
给定一个文本字符串y = (y1,…, yn),当文本长度为n,类号为c时,双向模型和单向模型中yi的条件概率为:
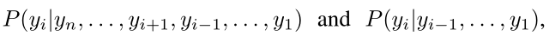
双向表示的可用熵可以量化为Hy = (n−1)log c,单向表示的可用熵为1/2 Hy
利用BERT MLM,将yi替换为[MASK]。然而每个文本实例都需要分别调用n次MLM,导致效率极低。通过指定注意掩码提出BCN,而不是mask输入字符:
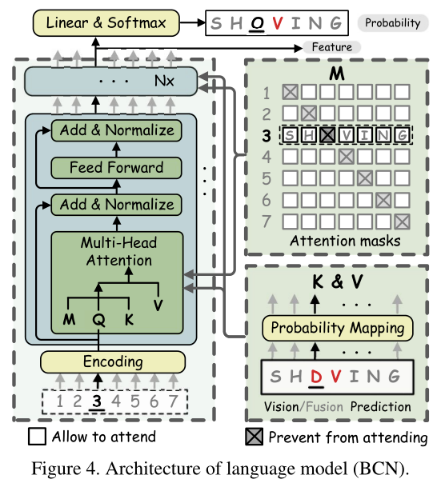
BCN是L层transformer decoder的变体。字符向量被输入到多头注意力块中,而不是网络的第一层。此外,多头注意力中的注意力mask是为了防止“看到自己”而设计的。
BCN不采用自注意,避免了信息跨时间步的泄露。多头块内部的注意操作可以形式化为:
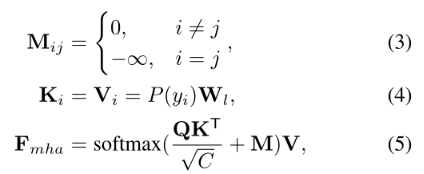
Q是第一层字符顺序的位置编码,否则是最后一层的输出。P为字符概率, Wl为线性映射矩阵。M是matrix of attention masks,它阻止了关注当前的特征。将BCN层堆叠成深层架构,确定文本y的双向表示Fl。
BCN能够优雅地学习比单向表示的集合更强大的双向表示。此外,得益于类似transformer的架构,BCN可以独立并行地进行计算。此外,它比集成模型更有效,因为只需要一半的计算和参数。
Iterative Correction
为了解决噪声输入的问题,提出了迭代LM(如图2所示)。LM重复执行M次,对y进行不同的赋值。在第一次迭代中,yi=1是VM的概率预测。对于后续迭代,yi≥2为上次迭代融合模型的概率预测。通过这种方法,LM能够对视觉预测进行迭代修正。
长度不对齐问题是由不可避免的填充掩码实现引起的,填充掩码用于过滤文本长度以外的上下文。我们的迭代LM可以通过多次融合视觉特征和语言特征来缓解这一问题,因此预测的文本长度也逐渐细化。
3、Fusion
基于图像训练的视觉模型和基于文本训练的语言模型来自不同的模态。为了对齐视觉特征和语言特征,我们简单地使用门控机制进行最终决策:
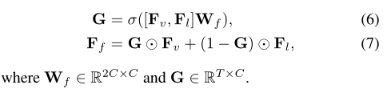
4、Supervised Training
多任务目标进行端到端训练:
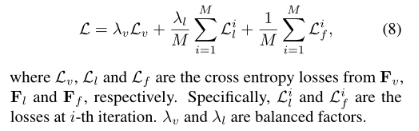
5、Semi-supervised Ensemble Self-training
自训练的基本思想是先通过模型本身生成伪标签,然后使用额外的伪标签重新训练模型。因此,关键问题在于构建高质量的伪标签。
1)选择文本实例中字符的最小置信度作为文本确定性。2)每个字符的迭代预测被视为一个集合,以平滑噪声标签的影响。filtering function:
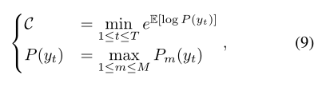
C是文本实例的最小确定性,Pm(yt)是第t个字符在第m次迭代时的概率分布。
四、Experiment
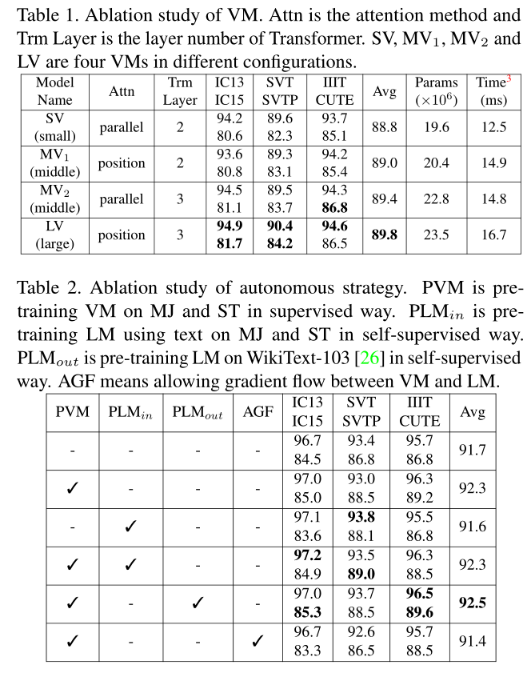
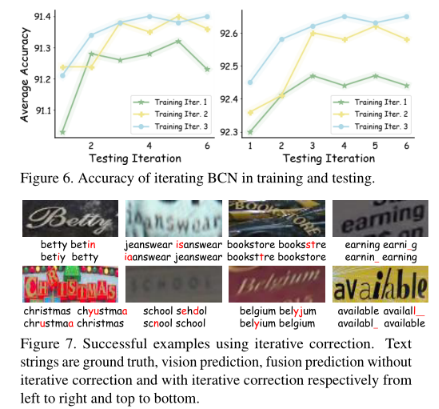
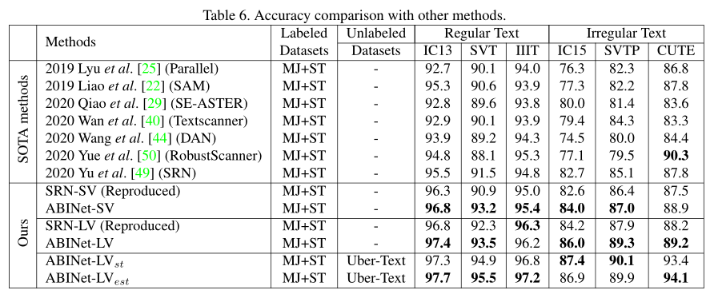


















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









