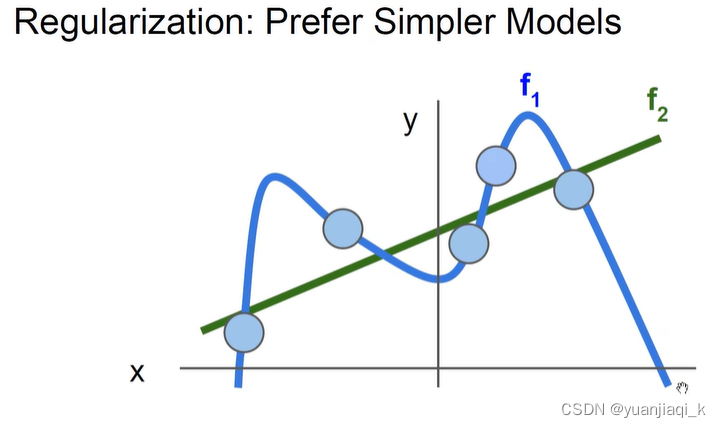
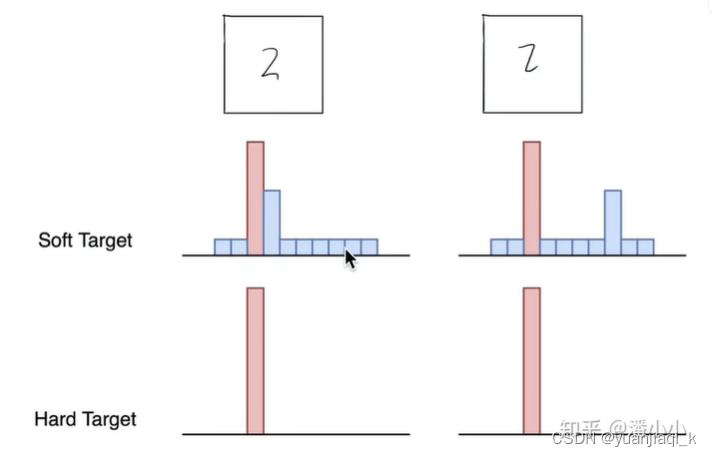
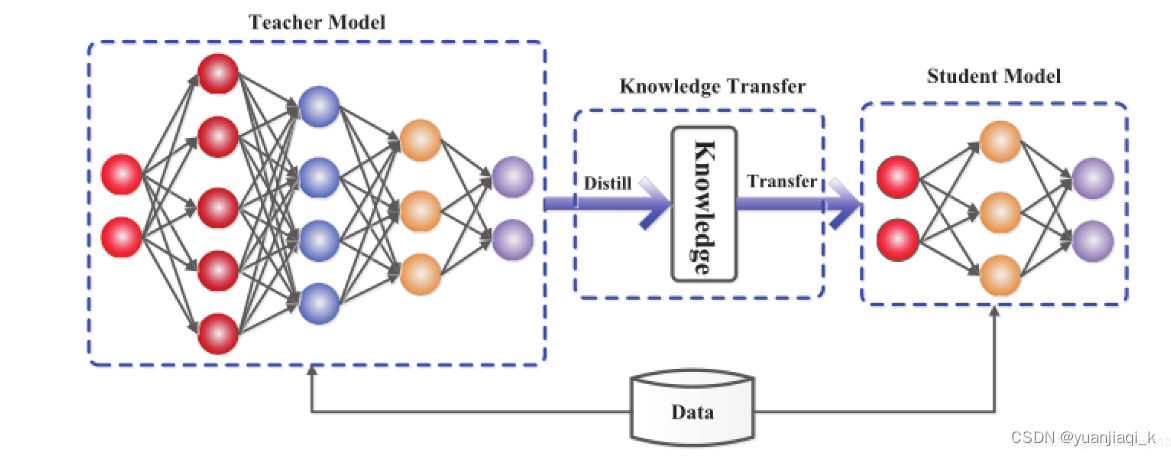
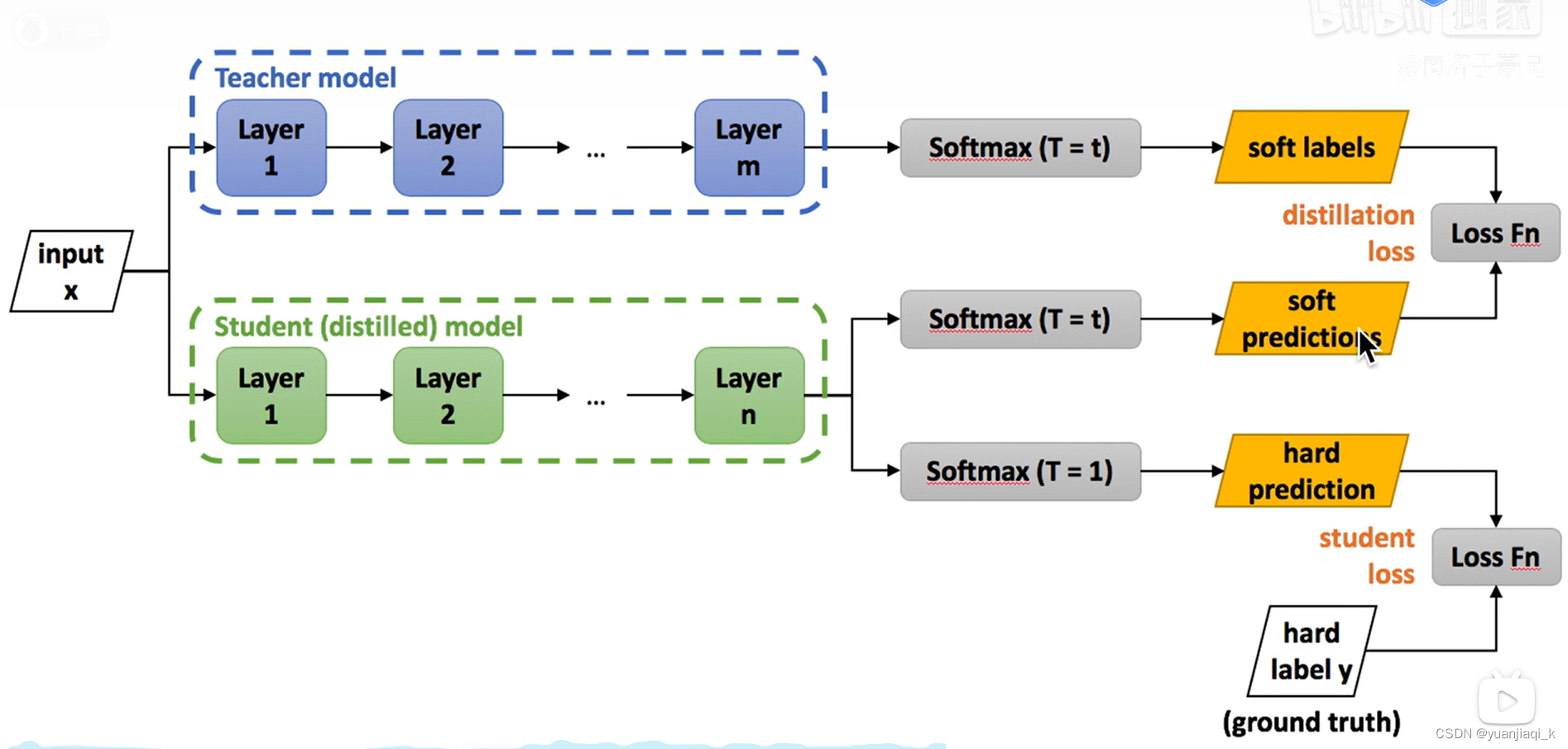
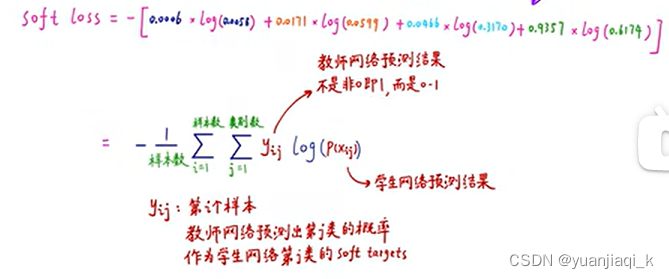
知识蒸馏 前置知识 Loss 现在分数-正确分数+1 例: 正则化 Regularization 用来防止过拟合 知识蒸馏相关 softmax 把分数转换为概率的一种方法,e的次方 hard targets 和 soft targets 蒸馏温度 T 在原来的softmax下,除以某个系数,让概率值相差不太大 知识蒸馏过程 Loss: hard loss: 传统交叉熵 distillation loss: 9 一般需要训练好的情趣额度较高的大的教师模型,和未训练的小的学生模型进行训练


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言































 4618
4618















