






目录
前言
STD的定义,来自chatGPT
Scene Text Detection(场景文本检测):也被称为文本定位。它是指从自然场景图像中自动检测和定位出存在的文本区域。场景文本检测的目标是找到图像中包含文本的矩形边界框,以便后续的文字识别或其他文本分析任务。
一般是作为STR(Scene Text Recogition 场景文本识别)的上游任务,STD负责把图中的文本区域圈出来,STR负责识别圈出来的文本内容。
STD有很多开源项目,可以参考Scene Text Detection | Papers With Code
这里选用的是当前较为流行,效果比较好,支持检测不规则文本行的DBNet++,在MMOCR框架上进行训练和推理。
环境
设备 RTX 3060 6G 独显笔记本
Windows 10
Python 3.10.9
Pytorch 1.12.1
CUDA 11.6
MMEngine 0.7.0
MMCV 2.0.0rc4
MMDet 3.0.0rc6
MMOCR 1.0.0rc6
准备环境
安装anaconda,准备python环境
conda create -n mmlab python=3.10
conda activate mmlab安装项目的python依赖,torch和torchvision建议用官网方式装,尽量用pip装,用conda直接装似乎有坑。(这里我安装的是cuda11.6下的torch1.12.1)
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116安装MMOCR环境
pip install -U openmim
mim install mmengine==0.7.0
mim install mmcv==2.0.0rc4
mim install mmdet==3.0.0rc6克隆MMOCR项目代码并安装
git clone https://github.com/open-mmlab/mmocr.git
cd mmocr
pip install -v -e .更多使用说明可以查看官方文档欢迎来到 MMOCR 的中文文档! — MMOCR 1.0.0 文档
准备数据集
这里我用的是Label Studio GitHub - heartexlabs/label-studio: Label Studio is a multi-type data labeling and annotation tool with standardized output format
按官网的教程安装即可,安装完会启动一个网页服务,在网页上进行标注。
这里建议用conda另外开一个虚拟环境,label-studio支持的python版本不能超过3.9。
conda create -n label python=3.9
conda activate label
# Requires Python >=3.7 <=3.9
pip install label-studio
# Start the server at http://localhost:8080
label-studio启动后随便注册一下,进入主页面创建一个项目。
进入项目,在Settings设置里修改下要标注的格式Labeling Interface,可以直接将以下的配置填写到code栏里。我的场景下文字是弯曲的,所以我用polygen(多边形)进行标注,如果文本行是直的,也可以直接用rectangle(矩形)进行标注。
配置如下,代表标注的内容是图片,标注的数据是多边形框和文本内容。更多配置可查看Label Studio官网。
<View>
<Image name="image"
value="$image"
zoom="true"
smoothing="true"
zoomControl="true"
negativeZoom="true"
crosshair="true"/>
<Polygon name="poly" toName="image" strokeWidth="3" smartOnly="true"/>
<TextArea name="transcription" toName="image"
editable="true"
perRegion="true"
required="true"
maxSubmissions="1"
rows="5"
placeholder="Recognized Text"
displayMode="region-list"/>
</View>配置完后,点击Import上传图片数据。
标注后的效果如图,这里我以每个字的突出点作为一个多边形的角点。
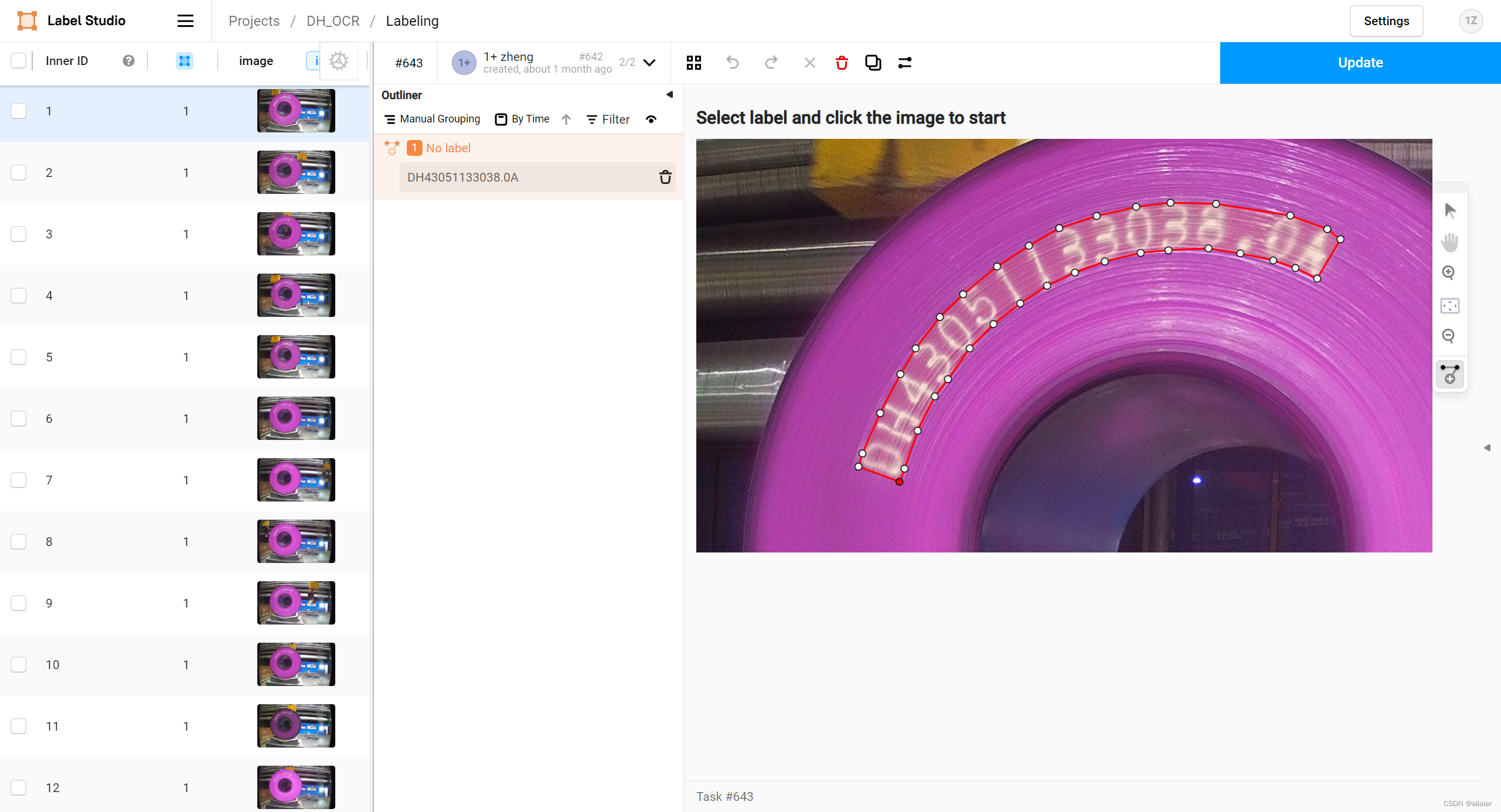
数据都标注完后点击Export导出标注数据,导出格式选JSON-MIN。这里只会导出标注数据,不会打包导出图片。
Label Studio标注的JSON-MIN数据格式和MMOCR要求的数据格式不同,需要手动转一下,并分出训练集和测试集。转换代码如下
import json
import numpy as np
import os, random, shutil
output_path = "输出的目标文件夹路径"
# 图片数据格式
image_type = "jpg"
input_img_path = f"输入图片文件夹路径"
input_anno_file = f"label studio导出的标注json文件路径"
output_img_path = f"{output_path}/textdet_imgs"
train_img_path = f"{output_img_path}/train"
test_img_path = f"{output_img_path}/test"
output_train_anno = f"{output_path}/textdet_train.json"
output_test_anno = f"{output_path}/textdet_test.json"
os.makedirs(train_img_path, exist_ok=True)
os.makedirs(test_img_path, exist_ok=True)
def convert(data_list, type):
res_json = {
"metainfo": {
"dataset_type": "TextDetDataset",
"task_name": "textdet",
"category": [{"id": 0, "name": "text"}],
},
"data_list": [],
}
# 每张图片
for res in data_list:
polys = res["poly"]
img_w = res["poly"][0]["original_width"]
img_h = res["poly"][0]["original_height"]
scale_w = img_w / 100
scale_h = img_h / 100
img_uri = res["image"]
img_path = img_uri.split("/")[-1].split("-", maxsplit=1)[1]
lines = []
# 每个poly
for index, poly in enumerate(polys):
points = poly["points"]
o_points = (
np.float32(points) * np.float32((scale_w, 1)) * np.float32((1, scale_h))
)
points = np.int0(o_points)
line = points.flatten().tolist()
x1 = int(np.min(points[:, 0]))
y1 = int(np.min(points[:, 1]))
x2 = int(np.max(points[:, 0]))
y2 = int(np.max(points[:, 1]))
lines.append(
{
"polygon": line,
"bbox": [x1, y1, x2, y2],
"bbox_label": 0,
"ignore": False,
}
)
res_json["data_list"].append(
{
"instances": lines,
"img_path": f"textdet_imgs/{type}/{img_path}",
"height": img_h,
"width": img_w,
}
)
shutil.copy(
f"{input_img_path}/{img_path.replace('_', ' ')}",
f"{output_img_path}/{type}/{img_path}",
)
if type == "train":
with open(output_train_anno, "w") as anno:
json.dump(res_json, anno)
else:
with open(output_test_anno, "w") as anno:
json.dump(res_json, anno)
with open(input_anno_file) as f:
data = json.load(f)
random.shuffle(data) # 随机打乱顺序
split_index = int(0.8 * len(data)) # 计算分割点
train_list = data[:split_index] # 取前80%作为训练集
test_list = data[split_index:] # 取后20%作为测试集
convert(train_list, "train")
convert(test_list, "test")
转完之后文件夹结构入下
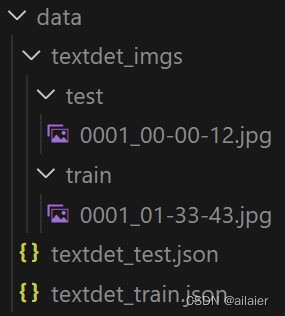
配置数据集
创建一个数据集配置文件,如命名为dataset.py
data_root = "数据集文件夹路径"
data_textdet_train = dict(
type="OCRDataset",
data_root=data_root,
ann_file="textdet_train.json",
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=None,
)
data_textdet_test = dict(
type="OCRDataset",
data_root=data_root,
ann_file="textdet_test.json",
test_mode=True,
pipeline=None,
)用MMOCR项目下的tools/analysis_tools/browse_dataset.py数据集预览工具进行验证,看数据转换及配置是否正确。
python tools/analysis_tools/browse_dataset.py 数据集配置.py如果能正常预览数据标注情况,及为配置完成。
配置模型
在MMOCR项目的configs\textdet\dbnetpp文件夹下创建一个模型配置文件,如config.py
_base_ = [
# 引用的dbnet++的模型配置
"_base_dbnetpp_resnet50-dcnv2_fpnc.py",
# 配置运行时的环境,打印方案,验证方案,可视化方案等。
"../_base_/default_runtime.py",
# 引用数据集配置
"数据集配置文件.py",
# 配置优化器方案
"../_base_/schedules/schedule_sgd_1200e.py",
]
# 加载预训练权重
load_from = "https://download.openmmlab.com/mmocr/textdet/dbnetpp/tmp_1.0_pretrain/dbnetpp_r50dcnv2_fpnc_100k_iter_synthtext-20220502-352fec8a.pth"
_base_.model.det_head = dict(
type="DBHead",
in_channels=256,
module_loss=dict(type="DBModuleLoss"),
# 配置后处理输出的结果
postprocessor=dict(
type="DBPostprocessor",
# poly为多边形,quad为预测区域的最小外接矩形
text_repr_type="poly",
# 拟合出来的多边形的平滑程度,越小越平滑
epsilon_ratio=0.002,
# 预测的结果区域往外膨胀的大小
unclip_ratio=4,
),
)
# dataset settings
data_textdet_train = _base_.data_textdet_train
data_textdet_test = _base_.data_textdet_test
test_pipeline = [
dict(
type="LoadImageFromFile",
color_type="color_ignore_orientation",
),
dict(type="Resize", scale=(1280, 1280), keep_ratio=True),
dict(type="LoadOCRAnnotations", with_polygon=True, with_bbox=True, with_label=True),
dict(
type="PackTextDetInputs",
meta_keys=("img_path", "ori_shape", "img_shape", "scale_factor", "instances"),
),
]
# pipeline settings
data_textdet_train.pipeline = _base_.train_pipeline
data_textdet_test.pipeline = test_pipeline
train_dataloader = dict(
batch_size=8,
num_workers=1,
persistent_workers=False,
sampler=dict(type="DefaultSampler", shuffle=True),
dataset=data_textdet_train,
)
val_dataloader = dict(
batch_size=8,
num_workers=1,
persistent_workers=False,
sampler=dict(type="DefaultSampler", shuffle=False),
dataset=data_textdet_test,
)
test_dataloader = val_dataloader
# 学习率
_base_.optim_wrapper.optimizer.lr = 0.002
# 训练多少轮在测试集上验证一次
_base_.train_cfg.val_interval = 1
# 训练多少轮保存一次权重
_base_.default_hooks.checkpoint.interval = 2
auto_scale_lr = dict(base_batch_size=8)
param_scheduler = [
dict(type="LinearLR", end=200, start_factor=0.001),
dict(type="PolyLR", power=0.9, eta_min=1e-7, begin=200, end=1200),
]
其他配置详将官方文档。
训练
执行MMOCR项目下的tools/train.py脚本
# amp 混合精度训练,减少显存暂用,提升速度。需要显卡支持
python tools/train.py 模型配置.py --amp训练到打印信息显示在测试集已经达到hmean达到1.0000或者接近即可。
默认模型输出路径在work_dirs/模型配置文件名/训练时间 下。
测试验证效果
选择一个打印信息里,测试集效果最好的模型,用项目下的python tools\test.py脚本验证。对比标注的和预测的结果是否一致。
python tools\test.py 模型配置文件.py 模型权重.pth --show效果如下
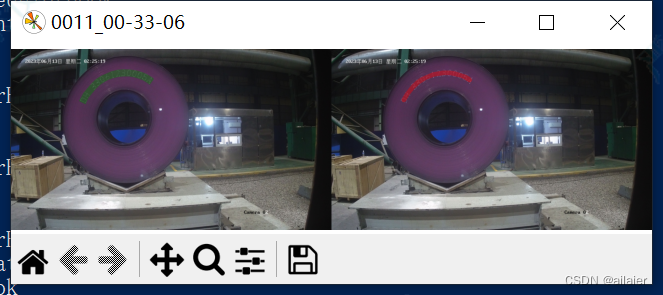
使用模型
MMOCR已经封装的非常方便,只需要几行代码就可以使用训练好的模型,代码如下
from mmocr.apis import TextDetInferencer
infer = TextDetInferencer(
model="模型配置文件.py",
weights="模型权重文件.pth",
device="cuda:0", # 显卡或CPU运行
)
det_res = infer(f"图片.jpg", show=True)
print(det_res)
后续
下篇将讲解如何用MMDeploy将模型转换成ONNX和TensorRT,并在visual studio工程里用QT和C++调用,部署成性能最佳可供生产环境使用的版本。
再后续将讲解如何结合前几篇
【STR文字识别项目】之 最新SOTA项目PARSeq(一)训练自己的数据集,并转成onnx用C++调用
【STR文字识别项目】之 最新SOTA项目PARSeq(二)转TensorRT并用C++调用
STR文本识别结合起来形成完整的文字识别流程。



















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











