







 本文介绍了马尔科夫链蒙特卡罗(MCMC)采样方法,包括基本的马尔科夫链、细致平稳条件、接受-拒绝采样、重要性采样以及M-H采样。重点讲解了M-H采样和Gibbs采样,Gibbs采样通过在每个坐标轴上轮流采样,解决了高维数据采样的效率问题,适用于大数据时代。通过Gibbs采样,可以从复杂的联合分布中生成样本,用于机器学习中的期望计算和其他统计推断任务。
本文介绍了马尔科夫链蒙特卡罗(MCMC)采样方法,包括基本的马尔科夫链、细致平稳条件、接受-拒绝采样、重要性采样以及M-H采样。重点讲解了M-H采样和Gibbs采样,Gibbs采样通过在每个坐标轴上轮流采样,解决了高维数据采样的效率问题,适用于大数据时代。通过Gibbs采样,可以从复杂的联合分布中生成样本,用于机器学习中的期望计算和其他统计推断任务。
MCMC sampling & Gibbs sampling
1. 什么是采样
我们知道了一个变量的分布,要生成一批服从这个分布的样本,这个过程就叫采样。
听起来好像很简单,对一些简单的分布函数确实如此,比如,均匀分布、正太分布,但只要分布函数稍微复杂一点,采样这个事情就没那么简单了。
2. 为什么要采样
在讲具体的采样方法之前,有必要弄清楚采样的目的。为什么要采样呢?有人可能会这样想,样本一般是用来估计分布参数的,现在我都知道分布函数了,还采样干嘛呢?其实采样不只是可以用来估计分布参数,还有其他用途,比如说用来估计分布的期望、高阶动量等。其实在机器学习中,采样的主要用途是用来估计某个函数在某个分布上的期望 ∫ f ( x ) p ( x ) d x \int {f(x)p(x)dx} ∫f(x)p(x)dx,比如在EM算法中,计算E步的时候,已知隐变量的分布,用采样的方法估计对数似然的期望。
3. 采样的作用
采样本质上是对随机线性的模拟,根据给定的概率分布,来模拟产生一个对应的随机事件。也可以理解为用较少的样本点来近似总体分布,可以算是一种信息降维。
可以快速了解总体分布中数据的结构和特性。
通过重采样可以充分利用已有数据集,挖掘更多信息,如自助法,刀切法。
4. 常用的采样方法
几乎所有的采样方法都是以均匀分布随机数作为基本操作的。
逆变换采样法:第一步,从均匀分布中产生一个随机数;第二步,根据一个累计分布函数的逆函数进行计算。如果待采样的目标分步的累计分布函数的逆函数无法求得或不易求,则不适合使用逆变换采样法。
拒绝采样:接受/拒绝采样,对于目标分布 p ( x ) p(x) p(x),选取一个容易采样的参考分布 q ( x ) q(x) q(x),使得对于任意 p ( x ) p(x) p(x)都小于等于 M ∗ q ( x ) M*q(x) M∗q(x)。第一步,从参考分布 q ( x ) q(x) q(x)中随机抽取一个样本;第二步,从均匀分布中产生一个随机数;第三步,如果 p ( x ) M q ( x ) \frac{{p(x)}}{{Mq(x)}} Mq(x)p(x) 大于随机数,则接受样本,如果小于则拒绝样本。
自适应拒绝采样:在目标函数是对数凹函数时,用分段函数来覆盖目标分布的对数。
重要性采样:就是用于计算函数在目标分布上的积分,如果只想从目标分布中采样出若干样本,可以使用重要性重采样。
在实际应用中,高维空间的随机向量,拒绝采样和重要性重采样经常难以找到合适的参考分布,采样效率比较低,可以考虑马尔科夫蒙特卡罗采样法(Markov Chain Monte Carlo)。
5. 基本采样方法
首先,最基本的方法是变换法,大概思想是这样的,比如我们要对分布 a a a 采样,但是只有分布 b b b 的采样器,我们可以通过对 b b b 采样的结果进行一些变换,使变换后的结果服从分布 a a a,举个例子,对0到1的均匀分布的结果进行 t a n tan tan 函数变换得到的结果就服从柯西分布,大家可以试想下怎么变换能得到指数分布和高斯分布。
对于简单的标准分布,可以用变换法,对于复杂分布就搞不定了。这个时候就有了拒绝采样(Rejection Sampling)和自适应拒绝采样(Adaptive Rejection Sampling),大概过程如下图所示,假设我们要对分布 p p p 采样,分布 p p p 比较复杂,可以先找一个简单的分布 q q q (Proposal distribution),然后对 q q q 乘上一个系数 k k k,保证对于任意 z z z 都有 k q ( z ) ⩾ p ( z ) kq(z) \geqslant p(z) kq(z)⩾p(z) ,这样可以保证 p p p 分布围成的区域一定在 k q kq kq 的下面,然后就可以在 k q kq kq 围成的区域内采样 ( z , h ) (z, h) (z,h)(分别是横坐标和纵坐标),如果落在 p p p 围成的区域中就得到一个样本点 z z z,否则丢弃这个样本。

这类方法的问题在于,如果建议分布
q
q
q 和实际分布
p
p
p 差别比较大的时候,拒绝率会比较高,导致采样效率低下,而且在高维的情况下这种问题还会被放大,因为维度越高,球的体积会越来越向球壳集中,所以即使建议分布和实际分布很接近,拒绝率还是会非常高。
为了解决拒绝率高的问题,就有了重要性采样(Importance Sampling),这种方法直接考虑求期望$ ∫ f ( x ) p ( x ) d x \int {f(x)p(x)dx} ∫f(x)p(x)dx ,在需要拒绝的时候,打一个折扣然后再算到期望里面,感觉很巧妙。但这种方法实际是绕开了问题,如果不只是需要期望还需要样本呢?这个时候就有了(Sampling-importance-resampleing),也不知道怎么翻译好了。其实和拒绝采样比较类似,只不过是拒绝采样是当场拒绝,这个是先留做备胎,最后按重要性权重再采样一次。
前面这些其实都是铺垫,接着该大招出场了,大招就是我们的MCMC及其变种Gibbs Sampling。
5.1 马尔科夫链蒙特卡洛采样(Markov Chain Monte Carlo)
要理解MCMC,有几个关键要点:
- 什么是随机过程
- 随机变量的变化过程就叫随机过程。相当于给随机变量加了一个时间的维度。
- 什么是马氏链
-
x
1
,
x
2
,
x
3
,
…
x
n
x_{1}, x_{2}, x_{3}, \ldots x_{n}
x1,x2,x3,…xn是一个随机过程,如果第
n
n
n 时刻的变量分布只和
n
−
1
n-1
n−1 时刻的状态有关,那么这个随机过程就叫马尔科夫随机过程,简称马氏链。
P ( x n ∣ x 1 , x 2 , x 3 , … x n − 1 ) = P ( x n ∣ x n − 1 ) P\left(x_{n} \mid x_{1}, x_{2}, x_{3}, \ldots x_{n-1}\right)=P\left(x_{n} \mid x_{n-1}\right) P(xn∣x1,x2,x3,…xn−1)=P(xn∣xn−1)
-
x
1
,
x
2
,
x
3
,
…
x
n
x_{1}, x_{2}, x_{3}, \ldots x_{n}
x1,x2,x3,…xn是一个随机过程,如果第
n
n
n 时刻的变量分布只和
n
−
1
n-1
n−1 时刻的状态有关,那么这个随机过程就叫马尔科夫随机过程,简称马氏链。
- 什么是转移矩阵
- 描述状态的转移过程, T n ( x ( n ) , x ( n + 1 ) ) = P ( x ( n + 1 ) ∣ x ( n ) ) T_{n}\left(x^{(n)}, x^{(n+1)}\right)=P\left(x^{(n+1)} \mid x^{(n)}\right) Tn(x(n),x(n+1))=P(x(n+1)∣x(n)) ,如果马氏链的转移矩阵和时间无关,就叫齐次马氏链。
- 什么是细致平稳条件
- 对于齐次马氏链,如果转移矩阵满足一定的条件,就可以保证每个时刻的状态服从相同的分布,并且最终可以收敛到平稳分布。细致平稳条件就是能保证收敛到平稳分布的一个充分条件。
p ∗ ( x ) T ( x , x ′ ) = p ∗ ( x ′ ) T ( x ′ , x ) p^{*}(x) T\left(x, x^{\prime}\right)=p^{*}\left(x^{\prime}\right) T\left(x^{\prime}, x\right) p∗(x)T(x,x′)=p∗(x′)T(x′,x)
- 对于齐次马氏链,如果转移矩阵满足一定的条件,就可以保证每个时刻的状态服从相同的分布,并且最终可以收敛到平稳分布。细致平稳条件就是能保证收敛到平稳分布的一个充分条件。
MCMC的基本思路是构造一个马氏链,并且凑出一个满足细致平稳条件的转移矩阵,从而保证最后能收敛到我们需要采样的分布。MCMC的巧妙之处就在于转移矩阵的构造 T ( x , x ′ ) = q ( x ′ ∣ x ) min ( 1 , p ( x ′ ) q ( x ∣ x ′ ) p ( x ) q ( x ′ ∣ x ) ) T\left(x, x^{\prime}\right)=q\left(x^{\prime} \mid x\right) \min \left(1, \frac{p\left(x^{\prime}\right) q\left(x \mid x^{\prime}\right)}{p(x) q\left(x^{\prime} \mid x\right)}\right) T(x,x′)=q(x′∣x)min(1,p(x)q(x′∣x)p(x′)q(x∣x′)) ,对于任意的 q ( x ′ ∣ x ) q\left(x^{\prime} \mid x\right) q(x′∣x) 都可以满足细致平稳条件。
5.1.1 蒙特卡罗方法 Monte Carlo method
蒙特卡罗原来是一个赌场的名称,用它作为名字大概是因为蒙特卡罗方法是一种随机模拟的方法,这很像赌博场里的扔骰子的过程。最早的蒙特卡罗方法都是为了求解一些不太好求解的求和或者积分问题。比如积分:
θ
=
∫
a
b
f
(
x
)
d
x
\theta = \int_a^b {f(x)dx}
θ=∫abf(x)dx
如果我们很难求解出 f ( x ) f(x) f(x) 的原函数,那么这个积分比较难求解。当然我们可以通过蒙特卡罗方法来模拟求解近似值。如何模拟呢?假设我们函数图像如下图:
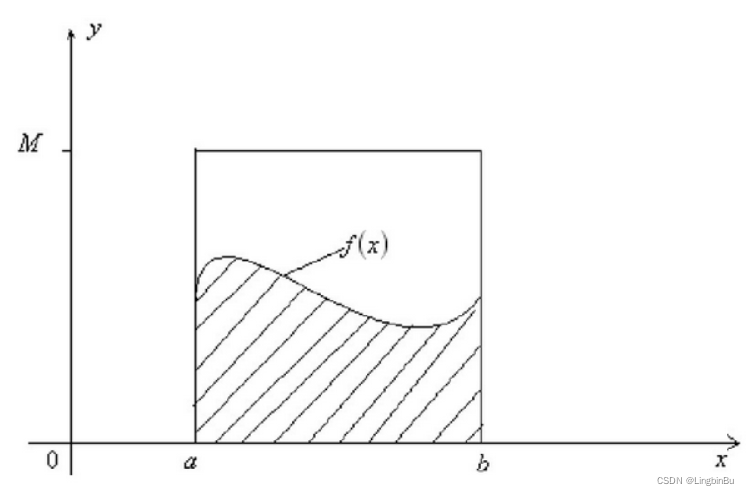
则一个简单的近似求解方法是在
[
a
,
b
]
[a, b]
[a,b] 之间随机的采样一个点。比如
x
o
x_o
xo,然后用
f
(
x
o
)
f(x_o)
f(xo) 代表在
[
a
,
b
]
[a, b]
[a,b] 区间上所有的
f
(
x
)
f(x)
f(x) 的值。那么上面的定积分的近似求解为:
(
b
−
a
)
f
(
x
0
)
(b-a)f(x_0)
(b−a)f(x0)
当然,用一个值代表
[
a
,
b
]
[a, b]
[a,b] 区间上所有的
f
(
x
)
f(x)
f(x) 的值,这个假设太粗糙。那么我们可以采样
[
a
,
b
]
[a, b]
[a,b] 区间的个值:
x
0
,
x
1
,
…
,
x
n
−
1
x_0, x_1, \ldots, x_{n-1}
x0,x1,…,xn−1,用它们的均值来代表
[
a
,
b
]
[a, b]
[a,b] 区间上所有的
f
(
x
)
f(x)
f(x) 的值。这样我们上面的定积分的近似求解为:
b
−
a
n
∑
i
=
0
n
−
1
f
(
x
i
)
\frac{{b - a}}{n}\sum\limits_{i = 0}^{n - 1} {f({x_i})}
nb−ai=0∑n−1f(xi)
虽然上面的方法可以一定程度上求解出近似的解,但是它隐含了一个假定,即
x
x
x 在
[
a
,
b
]
[a, b]
[a,b] 之间是均匀分布的,而绝大部分情况,
x
x
x 在
[
a
,
b
]
[a, b]
[a,b] 之间不是均匀分布的。如果我们用上面的方法,则模拟求出的结果很可能和真实值相差甚远。
怎么解决这个问题呢?如果我们可以得到
x
x
x 在
[
a
,
b
]
[a, b]
[a,b] 的概率分布函数
p
(
x
)
p(x)
p(x),那么我们的定积分求和可以这样进行:
θ
=
∫
a
b
f
(
x
)
d
x
=
∫
a
b
f
(
x
)
p
(
x
)
p
(
x
)
d
x
≈
1
n
∑
i
=
0
n
−
1
f
(
x
i
)
p
(
x
i
)
\theta=\int_{a}^{b} f(x) d x=\int_{a}^{b} \frac{f(x)}{p(x)} p(x) d x \approx \frac{1}{n} \sum_{i=0}^{n-1} \frac{f\left(x_{i}\right)}{p\left(x_{i}\right)}
θ=∫abf(x)dx=∫abp(x)f(x)p(x)dx≈n1i=0∑n−1p(xi)f(xi)
上式最右边的这个形式就是蒙特卡罗方法的一般形式。当然这里是连续函数形式的蒙特卡罗方法,但是在离散时一样成立。
可以看出,最上面我们假设
x
x
x 在
[
a
,
b
]
[a, b]
[a,b] 之间是均匀分布的时候,
p
(
x
)
=
1
/
(
b
一
a
)
p(x)=1/(b一a)
p(x)=1/(b一a),带入我们有概率分布的蒙特卡罗积分的上式,可以得到:
1
n
∑
i
=
0
n
−
1
f
(
x
i
)
1
/
(
b
−
a
)
=
b
−
a
n
∑
i
=
0
n
−
1
f
(
x
i
)
\frac{1}{n} \sum_{i=0}^{n-1} \frac{f\left(x_{i}\right)}{1 /(b-a)}=\frac{b-a}{n} \sum_{i=0}^{n-1} f\left(x_{i}\right)
n1i=0∑n−11/(b−a)f(xi)=nb−ai=0∑n−1f(xi)
也就是说,我们最上面的均匀分布也可以作为一般概率分布函数
f
(
x
)
f(x)
f(x) 在均匀分布时候的特例。那么我们现在的问题转到了如何求出
x
x
x 的分布
p
(
x
)
p(x)
p(x) 对应的若干个样本上来。
上一节我们讲到蒙特卡罗方法的关键是得到
x
x
x 的概率分布。如果求出了
x
x
x 的概率分布,我们可以基于概率分布去采样基于这个概率分布的
n
n
n 个
x
x
x 的样本集,带入蒙特卡罗求和的式子即可求解。但是还有一个关键的问题需要解决,即如何基于概率分布去采样基于这个概率分布的
n
n
n 个
x
x
x 的样本集。
对于常见的均匀分布
u
n
i
f
o
r
m
(
0
,
1
)
uniform(0,1)
uniform(0,1) 是非常容易采样样本的,一般通过线性同余发生器可以很方便的生成
(
0
,
1
)
(0,1)
(0,1) 之间的伪随机数样本。而其他常见的概率分布,无论是离散的分布还是连续的分布,它们的样本都可以通过
u
n
i
f
o
r
m
(
0
,
1
)
uniform(0,1)
uniform(0,1) 的样本转换而得。比如二维正态分布的样本
(
Z
1
,
Z
2
)
(Z_1,Z_2)
(Z1,Z2) 可以通过通过独立采样得到的
u
n
i
f
o
r
m
(
0
,
1
)
uniform(0,1)
uniform(0,1) 样本对
(
X
1
,
X
2
)
(X_1,X_2)
(X1,X2)通过如下的式子转换而得:
Z
1
=
−
2
ln
X
1
cos
(
2
π
X
2
)
Z
2
=
−
2
ln
X
1
sin
(
2
π
X
2
)
\begin{aligned} &Z_{1}=\sqrt{-2 \ln X_{1}} \cos \left(2 \pi X_{2}\right) \\ &Z_{2}=\sqrt{-2 \ln X_{1}} \sin \left(2 \pi X_{2}\right) \end{aligned}
Z1=−2lnX1cos(2πX2)Z2=−2lnX1sin(2πX2)
其他一些常见的连续分布,比如t分布,F分布,Beta分布,Gamma分布等,都可以通过类似的方式从
u
n
i
f
o
r
m
(
0
,
1
)
uniform(0,1)
uniform(0,1) 得到的采样样本转化得到。在pythonE的numpy,scikit-.learn等类库中,都有生成这些常用分布样本的函数可以使用。
不过很多时候,我们的c的概率分布不是常见的分布,这意味着我们没法方便的得到这些非常见的概率分布的样本集。那这个问题怎么解决呢?这就需要用到上面讲到的接受-拒绝等采样方法了。
蒙特卡罗方法小结
使用接受-拒绝采样,我们可以解决一些概率分布不是常见的分布的时候,得到其采样集并用蒙特卡罗方法求和的目的。但是接受-拒绝采样也只能部分满足我们的需求,在很多时候我们还是很难得到我们的概率分布的样本集。比如:
1)对于一些二维分布
p
(
x
,
y
)
p(x,y)
p(x,y),有时候我们只能得到条件分布
p
(
x
∣
y
)
p(x|y)
p(x∣y) 和
p
(
y
∣
x
)
p(y|x)
p(y∣x),却很难得到二维分布
p
(
x
,
y
)
p(x,y)
p(x,y) 一般形式,这时我们无法用接受-拒绝采样得到其样本集。
2)对于一些高维的复杂非常见分布
p
(
x
0
,
x
1
,
…
,
x
n
−
1
)
p(x_0, x_1, \ldots, x_{n-1})
p(x0,x1,…,xn−1),我们要找到一个合适的
p
(
x
)
p(x)
p(x) 和
k
k
k 非常困难。
从上面可以看出,要想将蒙特卡罗方法作为一个通用的采样模拟求和的方法,必须解决如何方便得到各种复杂概率分布的对应的采样样本集的问题。而我们下一篇要讲到的马尔科夫链就是帮助找到这些复杂概率分布的对应的采样样本集的白衣骑士。下一篇我们来总结马尔科夫链的原理。
5.1.2 马尔科夫链
马尔科夫链定义本身比较简单,它假设某一时刻状态转移的概率只依赖于它的前一个状态。举个形象的比喻,假如每天的天气是一个状态的话,那个今天是不是晴天只依赖于昨天的天气,而和前天的天气没有任何关系。当然这么说可能有些武断,但是这样做可以大大简化模型的复杂度,因此马尔科夫链在很多时间序列模型中得到广泛的应用,比如循环神经网络RNN,隐式马尔科夫模型HMM等,当然MCMC也需要它。
如果用精确的数学定义来描述,则假设我们的序列状态是
…
,
X
t
−
2
,
X
t
−
1
,
X
t
,
X
t
+
1
,
…
\ldots, X_{t-2}, X_{t-1}, X_{t}, X_{t+1}, \ldots
…,Xt−2,Xt−1,Xt,Xt+1,…,那么我们的在时刻
X
t
+
1
X_{t+1}
Xt+1 的状态的条件概率仅仅依赖于时刻
X
t
X_{t}
Xt,即:
P
(
X
t
+
1
∣
…
X
t
−
2
,
X
t
−
1
,
X
t
)
=
P
(
X
t
+
1
∣
X
t
)
P\left(X_{t+1} \mid \ldots X_{t-2}, X_{t-1}, X_{t}\right)=P\left(X_{t+1} \mid X_{t}\right)
P(Xt+1∣…Xt−2,Xt−1,Xt)=P(Xt+1∣Xt)
既然某一时刻状态转移的概率只依赖于它的前一个状态,那么我们只要能求出系统中任意两个状态之间的转换概率,这个马尔科夫链的模型就定了。我们来看看下图这个马尔科夫链模型的具体的例子(来源于维基百科)。
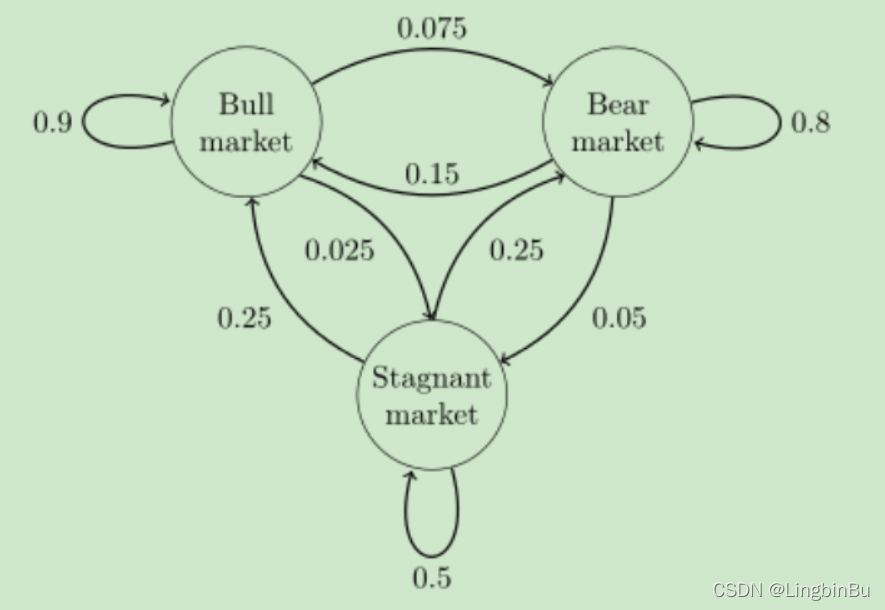
这个马尔科夫链是表示股市模型的,共有三种状态:牛市(Bull market),熊市(Bear market)和横盘(Stagnant market)。每一个状态都以一定的概率转化到下一个状态。比如,牛市以0.025的概率转化到横盘的状态。这个状态概率转化图可以以矩阵的形式表示。如果我们定义矩阵
P
P
P 某一位置
P
(
i
,
j
)
P(i, j)
P(i,j) 的值为
P
(
j
∣
i
)
P(j| i)
P(j∣i),即从状态
i
i
i 转化到状态
j
j
j 的概率,并定义牛市为状态0,熊市为状态1,横盘为状态2。这样我们得到了马尔科夫链模型的状态转移矩阵为:
P
=
(
0.9
0.075
0.025
0.15
0.8
0.05
0.25
0.25
0.5
)
P=\left(\begin{array}{ccc} 0.9 & 0.075 & 0.025 \\ 0.15 & 0.8 & 0.05 \\ 0.25 & 0.25 & 0.5 \end{array}\right)
P=⎝⎛0.90.150.250.0750.80.250.0250.050.5⎠⎞
讲了这么多,那么马尔科夫链模型的状态转移矩阵和我们蒙特卡罗方法需要的概率分布样本集有什么关系呢?这需要从马尔科夫链模型的状态转移矩阵的性质讲起。
得到了马尔科夫链模型的状态转移矩阵,我们来看看马尔科夫链模型的状态转移矩阵的性质。
仍然以上面的这个状态转移矩阵为例。假设我们当前股市的概率分布为: [ 0.3 , 0.4 , 0.3 ] [0.3,0.4,0.3] [0.3,0.4,0.3],即30%概率的牛市,40%概率的熊盘与30%的横盘。然后这个状态作为序列概率分布的初始状态0,将其带入这个状态转移矩阵计算 x 1 , x 2 , x 3 , … x_{1}, x_{2}, x_{3}, \ldots x1,x2,x3,…的状态。代码如下:
import numpy as np
matrix = np.matrix([[0.9,0.075,0.025],[0.15,0.8,0.05],[0.25,0.25,0.5]], dtype=float)
vector1 = np.matrix([[0.3,0.4,0.3]], dtype=float)
for i in range(100):
vector1 = vector1*matrix
print("Current round:" , i+1)
print(vector1)
部分输出结果如下:
Current round: 1
[[ 0.405 0.4175 0.1775]]
Current round: 2
[[ 0.4715 0.40875 0.11975]]
Current round: 3
[[ 0.5156 0.3923 0.0921]]
Current round: 4
[[ 0.54591 0.375535 0.078555]]
。。。。。。
Current round: 58
[[ 0.62499999 0.31250001 0.0625 ]]
Current round: 59
[[ 0.62499999 0.3125 0.0625 ]]
Current round: 60
[[ 0.625 0.3125 0.0625]]
。。。。。。
Current round: 99
[[ 0.625 0.3125 0.0625]]
Current round: 100
[[ 0.625 0.3125 0.0625]]
可以发现,从第60轮开始,我们的状态概率分布就不变了,一直保持在
[
0.6250.31250.0625
]
[0.6250.31250.0625]
[0.6250.31250.0625],即62.5%的牛市,31.25%的熊市与6.25%的横盘。那么这个是巧合吗?
我们现在换一个初始概率分布试一试,现在我们用
[
0.7
,
0.1
,
0.2
]
[0.7,0.1,0.2]
[0.7,0.1,0.2] 作为初始概率分布,然后这个状态作为序列概率分布的初始状态
t
0
t_0
t0,将其带入这个状态转移矩阵计算
x
1
,
x
2
,
x
3
,
…
x_{1}, x_{2}, x_{3}, \ldots
x1,x2,x3,…的状态。代码如下:
import numpy as np
matrix = np.matrix([[0.9,0.075,0.025],[0.15,0.8,0.05],[0.25,0.25,0.5]], dtype=float)
vector1 = np.matrix([[0.7,0.1,0.2]], dtype=float)
for i in range(100):
vector1 = vector1*matrix
print("Current round:" , i+1)
print(vector1)
部分输出结果如下:
Current round: 1
[[ 0.695 0.1825 0.1225]]
Current round: 2
[[ 0.6835 0.22875 0.08775]]
Current round: 3
[[ 0.6714 0.2562 0.0724]]
Current round: 4
[[ 0.66079 0.273415 0.065795]]
。。。。。。。
Current round: 55
[[ 0.62500001 0.31249999 0.0625 ]]
Current round: 56
[[ 0.62500001 0.31249999 0.0625 ]]
Current round: 57
[[ 0.625 0.3125 0.0625]]
。。。。。。。
Current round: 99
[[ 0.625 0.3125 0.0625]]
Current round: 100
[[ 0.625 0.3125 0.0625]]
可以看出,尽管这次我们采用了不同初始概率分布,最终状态的概率分布趋于同一个稳定的概率分布
[
0.6250.31250.0625
]
[0.6250.31250.0625]
[0.6250.31250.0625],也就是说我们的马尔科夫链模型的状态转移矩阵收敛到的稳定概率分布与我们的初始状态概率分布无关,这是一个非常好的性质,也就是说,如果我们得到了这个稳定概率分布对应的马尔科夫链模型的状态转移矩阵,则我们可以用任意的概率分布样本开始,带入马尔科夫链模型的状态转移矩阵,这样经过一些序列的转换,最终就可以得到符合对应稳定概率分布的样本。
这个性质不光对我们上面的状态转移矩阵有效,对于绝大多数的其他的马尔科夫链模型的状态转移矩阵也有效。同时不光是离散状态,连续状态时也成立。
同时,对于一个确定的状态转移矩阵
P
P
P,它的
n
n
n 次幂
P
n
P^n
Pn 在当
n
n
n 大于一定的值的时候也可以发现是确定的,我们还是以上面的例子为例,计算代码如下:
import numpy as np
matrix = np.matrix([[0.9,0.075,0.025],[0.15,0.8,0.05],[0.25,0.25,0.5]], dtype=float)
for i in range(10):
matrix = matrix*matrix
print("Current round:" , i+1)
print(matrix)
部分输出结果如下:
Current round: 1
[[ 0.8275 0.13375 0.03875]
[ 0.2675 0.66375 0.06875]
[ 0.3875 0.34375 0.26875]]
Current round: 2
[[ 0.73555 0.212775 0.051675]
[ 0.42555 0.499975 0.074475]
[ 0.51675 0.372375 0.110875]]
。。。。。。
Current round: 5
[[ 0.62502532 0.31247685 0.06249783]
[ 0.6249537 0.31254233 0.06250397]
[ 0.62497828 0.31251986 0.06250186]]
Current round: 6
[[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]]
Current round: 7
[[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]]
。。。。。。
Current round: 9
[[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]]
Current round: 10
[[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]
[ 0.625 0.3125 0.0625]]
X*Y...Y=Z ==> Y...Y=Z, Y和Z确定之后,X为任意矩阵都可以。Y的n次幂=Z
Y为状态转移矩阵;Z为稳定概率分布。
我们可以发现,在 n ≥ 6 n≥6 n≥6 以后, P n P^n Pn 的值稳定不再变化,而且每一行都为 [ 0.6250.31250.0625 ] [0.6250.31250.0625] [0.6250.31250.0625],这和我们前面的稳定分布是一致的。这个性质同样不光是离散状态,连续状态时也成立。
好了,现在我们可以用数学语言总结下马尔科夫链的收敛性质了:
如果一个非周期的马尔科夫链有状态转移矩阵
P
P
P,并且它的任何两个状态是连通的,那么
lim
n
→
∞
P
i
j
n
\mathop {\lim }\limits_{n \to \infty } P_{ij}^n
n→∞limPijn 与
i
i
i无关,我们有:
lim n → ∞ P i j n = π ( j ) (1) \begin{gathered} \lim _{n \rightarrow \infty} P_{i j}^{n}=\pi(j) \end{gathered}\tag{1} n→∞limPijn=π(j)(1)
lim n → ∞ P n = ( π ( 1 ) π ( 2 ) … π ( j ) … π ( 1 ) π ( 2 ) … π ( j ) … … … … … … π ( 1 ) π ( 2 ) … π ( j ) … … … … … … ) (2) \begin{gathered} \lim _{n \rightarrow \infty} P^{n}=\left(\begin{array}{ccccc} \pi(1) & \pi(2) & \ldots & \pi(j) & \ldots \\ \pi(1) & \pi(2) & \ldots & \pi(j) & \ldots \\ \ldots & \ldots & \ldots & \ldots & \ldots \\ \pi(1) & \pi(2) & \ldots & \pi(j) & \ldots \\ \ldots & \ldots & \ldots & \ldots & \ldots \end{array}\right) \end{gathered} \tag{2} n→∞limPn=⎝⎜⎜⎜⎜⎛π(1)π(1)…π(1)…π(2)π(2)…π(2)………………π(j)π(j)…π(j)………………⎠⎟⎟⎟⎟⎞(2)
π ( j ) = ∑ i = 0 ∞ π ( i ) P i j (3) \begin{gathered} \pi(j)=\sum_{i=0}^{\infty} \pi(i) P_{i j} \end{gathered}\tag{3} π(j)=i=0∑∞π(i)Pij(3)
π π π 是方程 π P = π πP=π πP=π 的唯一非负解,其中:
π = [ π ( 1 ) , π ( 2 ) , … , π ( j ) , … ] , ∑ i = 0 ∞ π ( i ) = 1 (4) \pi=[\pi(1), \pi(2), \ldots, \pi(j), \ldots], \sum_{i=0}^{\infty} \pi(i)=1 \tag{4} π=[π(1),π(2),…,π(j),…],i=0∑∞π(i)=1(4)
上面的性质中需要解释的有:
- 非周期的马尔科夫链:这个主要是指马尔科夫链的状态转化不是循环的,如果是循环的则永远不会收敛。幸运的是我们遇到的马尔科夫链一般都是非周期性的。用数学方式表述则是:对于任意某一状态 i i i, d d d 为集合 { n ∣ n ≥ 1 , P i i n > 0 } \left\{n \mid n \geq 1, P_{i i}^{n}>0\right\} {n∣n≥1,Piin>0}的最大公约数,如果 d = 1 d=1 d=1,则该状态为非周期的
- 任何两个状态是连通的:这个指的是从任意一个状态可以通过有限步到达其他的任意一个状态,不会出现条件概率直为0导致不可达的情况。
- 马尔科夫链的状态数可以是有限的,也可以是无限的。因此可以用于连续概率分布和离散概率分布。
- π π π 通常称为马尔科夫链的平稳分布。
基于马尔科夫链采样
如果我们得到了某个平稳分布所对应的马尔科夫链状态转移矩阵,我们就很容易采用出这个平稳分布的样本集。
假设我们任意初始的概率分布是
π
0
(
x
)
π_0(x)
π0(x),经过第一轮马尔科夫链状态转移后的概率分布是
π
1
(
x
)
π_1(x)
π1(x),… ,第
i
i
i 轮的概率分布是
π
i
(
x
)
π_i(x)
πi(x)。假设经过
n
n
n 轮后马尔科夫链收敛到我们的平稳分布
π
(
x
)
π(x)
π(x),即:
π
n
(
x
)
=
π
n
+
1
(
x
)
=
π
n
+
2
(
x
)
=
…
=
π
(
x
)
\pi_{n}(x)=\pi_{n+1}(x)=\pi_{n+2}(x)=\ldots=\pi(x)
πn(x)=πn+1(x)=πn+2(x)=…=π(x)
对于每个分布
π
i
(
x
)
π_i(x)
πi(x),我们有:
π
i
(
x
)
=
π
i
−
1
(
x
)
P
=
π
i
−
2
(
x
)
P
2
=
π
0
(
x
)
P
i
\pi_{i}(x)=\pi_{i-1}(x) P=\pi_{i-2}(x) P^{2}=\pi_{0}(x) P^{i}
πi(x)=πi−1(x)P=πi−2(x)P2=π0(x)Pi
现在我们可以开始采样了,首先,基于初始任意简单概率分布,比如高斯分布
π
0
(
x
)
π_0(x)
π0(x) 采样得到状态值
x
0
x_0
x0,基于条件概率分布
P
(
x
∣
x
0
)
P(x|x_0)
P(x∣x0)采样状态值
x
1
x_1
x1,一直进行下去,当状态转移进行到一定的次数时,比如到
n
n
n 次时,我们认为此时的采样集
(
x
n
,
x
n
+
1
,
x
n
+
2
,
…
)
\left(x_{n}, x_{n+1}, x_{n+2}, \ldots\right)
(xn,xn+1,xn+2,…)即是符合我们的平稳分布的对应样本集,可以用来做蒙特卡罗模拟求和了。
总结下基于马尔科夫链的采样过程:
- 输入马尔科夫链状态转移矩阵 P P P,设定状态转移次数阈值 n 1 n_1 n1,需要的样本个数 n 2 n_2 n2。
- 从任意简单概率分布采样得到初始状态值 x 0 x_0 x0。
- for t = 0 t=0 t=0 to n 1 + n 2 − 1 n_1+n_2-1 n1+n2−1,从条件概率分布 P ( x ∣ x t ) P(x|x_t) P(x∣xt)中采样得到样本 x t + 1 x_{t+1} xt+1。
样本集 ( x n 1 , x n 1 + 1 , … , x n 1 + n 2 − 1 ) \left(x_{n_{1}}, x_{n_{1}+1}, \ldots, x_{n_{1}+n_{2}-1}\right) (xn1,xn1+1,…,xn1+n2−1)即为我们需要的平稳分布对应的样本集。
马尔科夫链采样小结
如果假定我们可以得到我们需要采样样本的平稳分布所对应的马尔科夫链状态转移矩阵,那么我们就可以用马尔科夫链采样得到我们需要的样本集,进而进行蒙特卡罗模拟。但是一个重要的问题是,随意给定一个平稳分布
π
π
π,如何得到它所对应的马尔科夫链状态转移矩阵P呢?这是个大问题。我们绕了一圈似乎还是没有解决任意概率分布采样样本集的问题。
幸运的是,MCMC采样通过迂回的方式解决了上面这个大问题,我们在下一篇来讨论MCMC的采样,以及它的使用改进版采样:M-H采样和Gibbs采样。
5.1.3 MCMC采样和M-H采样
马尔科夫链的细致平稳条件
在解决从平稳分布 π π π,找到对应的马尔科夫链状态转移矩阵 P P P 之前,我们还需要先看看马尔科夫链的细致平稳条件。定义如下:
如果非周期马尔科夫链的状态转移矩阵
P
P
P 和概率分布
π
(
x
)
π(x)
π(x) 对于所有的
i
i
i,满足:
π
(
i
)
P
(
i
,
j
)
=
π
(
j
)
P
(
j
,
i
)
\pi(i) P(i, j)=\pi(j) P(j, i)
π(i)P(i,j)=π(j)P(j,i)
则称概率分布
π
(
c
)
π(c)
π(c) 是状态转移矩阵
P
P
P 的平稳分布。
证明很简单,由细致平稳条件有:
∑
i
=
1
∞
π
(
i
)
P
(
i
,
j
)
=
∑
i
=
1
∞
π
(
j
)
P
(
j
,
i
)
=
π
(
j
)
∑
i
=
1
∞
P
(
j
,
i
)
=
π
(
j
)
\sum_{i=1}^{\infty} \pi(i) P(i, j)=\sum_{i=1}^{\infty} \pi(j) P(j, i)=\pi(j) \sum_{i=1}^{\infty} P(j, i)=\pi(j)
i=1∑∞π(i)P(i,j)=i=1∑∞π(j)P(j,i)=π(j)i=1∑∞P(j,i)=π(j)
将上式用矩阵表示即为:
π P = π \pi P = \pi πP=π
即满足马尔可夫链的收敛性质。也就是说,只要我们找到了可以使概率分布
π
(
x
)
π(x)
π(x) 满足细致平稳分布的矩阵
P
P
P 即可。这给了我们寻找从平稳分布
π
(
x
)
π(x)
π(x),找到对应的马尔科夫链状态转移矩阵
P
P
P 的新思路。
不过不幸的是,仅仅从细致平稳条件还是很难找到合适的矩阵
P
P
P。比如我们的目标平稳分布是
π
(
x
)
π(x)
π(x),随机找一个马尔科夫链状态转移矩阵
Q
Q
Q,它是很难满足细致平稳条件的,即:
π
(
i
)
Q
(
i
,
j
)
≠
π
(
j
)
Q
(
j
,
i
)
\pi(i) Q(i, j) \neq \pi(j) Q(j, i)
π(i)Q(i,j)=π(j)Q(j,i)
那么如何使这个等式满足呢?下面我们来看MCMC采样如何解决这个问题。
MCMC采样
由于一般情况下,目标平稳分布
π
(
x
)
\pi(x)
π(x) 和某一个马尔科夫链状态转移矩阵
Q
Q
Q 不满足细致平稳条件,即
π
(
i
)
Q
(
i
,
j
)
≠
π
(
j
)
Q
(
j
,
i
)
\pi(i) Q(i, j) \neq \pi(j) Q(j, i)
π(i)Q(i,j)=π(j)Q(j,i)
我们可以对上式做一个改造,使细致平稳条件成立。方法是引入一个
α
(
i
,
j
)
\alpha(i, j)
α(i,j),使上式可以取等号,即:
π
(
i
)
Q
(
i
,
j
)
α
(
i
,
j
)
=
π
(
j
)
Q
(
j
,
i
)
α
(
j
,
i
)
\pi(i) Q(i, j) \alpha(i, j)=\pi(j) Q(j, i) \alpha(j, i)
π(i)Q(i,j)α(i,j)=π(j)Q(j,i)α(j,i)
问题是什么样的
α
(
i
,
j
)
\alpha(i, j)
α(i,j) 可以使等式成立呢? 其实很简单,只要满足下两式即可:
α
(
i
,
j
)
=
π
(
j
)
Q
(
j
,
i
)
α
(
j
,
i
)
=
π
(
i
)
Q
(
i
,
j
)
\begin{aligned} &\alpha(i, j)=\pi(j) Q(j, i) \\ &\alpha(j, i)=\pi(i) Q(i, j) \end{aligned}
α(i,j)=π(j)Q(j,i)α(j,i)=π(i)Q(i,j)
这样,我们就得到了我们的分布
π
(
x
)
\pi(x)
π(x) 对应的马尔科夫链状态转移矩阵
P
P
P ,满足:
P
(
i
,
j
)
=
Q
(
i
,
j
)
α
(
i
,
j
)
P(i, j)=Q(i, j) \alpha(i, j)
P(i,j)=Q(i,j)α(i,j)
也就是说,我们的目标矩阵
P
P
P 可以通过任意一个马尔科夫链状态转移矩阵
Q
Q
Q 乘以
α
(
i
,
j
)
\alpha(i, j)
α(i,j) 得到。
α
(
i
,
j
)
\alpha(i, j)
α(i,j) 我们一般称之 为接受率。取值在
[
0
,
1
]
[0,1]
[0,1] 之间,可以理解为一个概率值。即目标矩阵
P
P
P 可以通过任意一个马尔科夫链状态转移矩阵
Q
Q
Q 以一定的接 受率获得。这个很像我们在MCMC (二)蒙特卡罗方法第4节讲到的接受-拒绝采样,那里是以一个常用分布通过一定的接受-拒绝 概率得到一个非常见分布,这里是以一个常见的马尔科夫链状态转移矩阵
Q
Q
Q 通过一定的接受-拒绝概率得到目标转移矩阵
P
P
P,两者 的解决问题思路是类似的。
好了,现在我们来总结下MCMC的采样过程。
- 输入我们任意选定的马尔科夫链状态转移矩阵 Q Q Q ,平稳分布 π ( x ) \pi(x) π(x) ,设定状态转移次数阈值 n 1 n_{1} n1 ,需要的样本个数 n 2 n_{2} n2
- 从任意简单概率分布采样得到初始状态值 x 0 x_{0} x0
- for
t
=
0
t=0
t=0 to
n
1
+
n
2
−
1
n_{1}+n_{2}-1
n1+n2−1 :
a) 从条件概率分布 Q ( x ∣ x t ) Q\left(x \mid x_{t}\right) Q(x∣xt) 中采样得到样本 x ∗ x_{*} x∗
b) 从均匀分布采样 u ∼ u n i f o r m [ 0 , 1 ] u \sim uniform [0,1] u∼uniform[0,1]
c) 如果 u < α ( x t , x ∗ ) = π ( x ∗ ) Q ( x ∗ , x t ) u<\alpha\left(x_{t}, x_{*}\right)=\pi\left(x_{*}\right) Q\left(x_{*}, x_{t}\right) u<α(xt,x∗)=π(x∗)Q(x∗,xt) ,则接受转移 x t → x ∗ x_{t} \rightarrow x_{*} xt→x∗ ,即 x t + 1 = x ∗ x_{t+1}=x_{*} xt+1=x∗
d) 否则不接受转移,即 x t + 1 = x t x_{t+1}=x_{t} xt+1=xt
样本集 ( x n 1 , x n 1 + 1 , … , x n 1 + n 2 − 1 ) \left(x_{n_{1}}, x_{n_{1}+1}, \ldots, x_{n_{1}+n_{2}-1}\right) (xn1,xn1+1,…,xn1+n2−1) 即为我们需要的平稳分布对应的样本集。
上面这个过程基本上就是MCMC采样的完整采样理论了,但是这个采样算法还是比较难在实际中应用,为什么呢? 问 题在上面第三步的c步骤,接受率这儿。由于 α ( x t , x ∗ ) \alpha\left(x_{t}, x_{*}\right) α(xt,x∗) 可能非常的小,比如0.1,导致我们大部分的采样值都被拒绝转移,采 样效率很低。有可能我们采样了上百万次马尔可夫链还没有收敛,也就是上面这个 n 1 n_{1} n1 要非常非常的大,这让人难以接受,怎么 办呢? 这时就轮到我们的M-H采样出场了。
M-H采样
M-H采样是Metropolis-Hastings采样的简称,这个算法首先由Metropolis提出,被Hastings改进,因此被称之为 Metropolis-Hastings采样或M-H采样
M-H采样解决了我们上一节MCMC采样接受率过低的问题。
我们回到MCMC采样的细致平稳条件:
π
(
i
)
Q
(
i
,
j
)
α
(
i
,
j
)
=
π
(
j
)
Q
(
j
,
i
)
α
(
j
,
i
)
\pi(i) Q(i, j) \alpha(i, j)=\pi(j) Q(j, i) \alpha(j, i)
π(i)Q(i,j)α(i,j)=π(j)Q(j,i)α(j,i)
我们采样效率低的原因是
α
(
i
,
j
)
\alpha(i, j)
α(i,j) 太了,比如为
0.1
0.1
0.1 ,而
α
(
j
,
i
)
\alpha(j, i)
α(j,i) 为
0.2
0.2
0.2 。即:
π
(
i
)
Q
(
i
,
j
)
×
0.1
=
π
(
j
)
Q
(
j
,
i
)
×
0.2
\pi(i) Q(i, j) \times 0.1=\pi(j) Q(j, i) \times 0.2
π(i)Q(i,j)×0.1=π(j)Q(j,i)×0.2
这时我们可以看到,如果两边同时扩大五倍,接受率提高到了0.5,但是细致平稳条件却仍然是满足的,即:
π
(
i
)
Q
(
i
,
j
)
×
0.5
=
π
(
j
)
Q
(
j
,
i
)
×
1
\pi(i) Q(i, j) \times 0.5=\pi(j) Q(j, i) \times 1
π(i)Q(i,j)×0.5=π(j)Q(j,i)×1
这样我们的接受率可以做如下改进,即:
α
(
i
,
j
)
=
min
{
π
(
j
)
Q
(
j
,
i
)
π
(
i
)
Q
(
i
,
j
)
,
1
}
\alpha(i, j)=\min \left\{\frac{\pi(j) Q(j, i)}{\pi(i) Q(i, j)}, 1\right\}
α(i,j)=min{π(i)Q(i,j)π(j)Q(j,i),1}
通过这个微小的改造,我们就得到了可以在实际应用中使用的M-H采样算法过程如下:
- 输入我们任意选定的马尔科夫链状态转移矩阵 Q Q Q ,平稳分布 π ( x ) \pi(x) π(x) ,设定状态转移次数阈值 n 1 n_{1} n1 ,需要的样本个数 n 2 n_{2} n2
- 从任意简单概率分布采样得到初始状态值 x 0 x_{0} x0
- for
t
=
0
t=0
t=0 to
n
1
+
n
2
−
1
n_{1}+n_{2}-1
n1+n2−1 :
a) 从条件概率分布 Q ( x ∣ x t ) Q\left(x \mid x_{t}\right) Q(x∣xt) 中采样得到样本 x ∗ x_{*} x∗
b) 从均匀分布采样 u ∼ u n i f o r m [ 0 , 1 ] u \sim uniform [0,1] u∼uniform[0,1]
c) 如果 u < α ( x t , x ∗ ) = min { π ( j ) Q ( j , i ) π ( i ) Q ( i , j ) , 1 } u<\alpha\left(x_{t}, x_{*}\right)=\min \left\{\frac{\pi(j) Q(j, i)}{\pi(i) Q(i, j)}, 1\right\} u<α(xt,x∗)=min{π(i)Q(i,j)π(j)Q(j,i),1} ,则接受转移 x t → x ∗ x_{t} \rightarrow x_{*} xt→x∗ ,即 x t + 1 = x ∗ x_{t+1}=x_{*} xt+1=x∗
d) 否则不接受转移,即 x t + 1 = x t x_{t+1}=x_{t} xt+1=xt
样本集 ( x n 1 , x n 1 + 1 , … , x n 1 + n 2 − 1 ) \left(x_{n_{1}}, x_{n_{1}+1}, \ldots, x_{n_{1}+n_{2}-1}\right) (xn1,xn1+1,…,xn1+n2−1) 即为我们需要的平稳分布对应的样本集。
很多时候,我们选择的马尔科夫链状态转移矩阵
Q
Q
Q 如果是对称的,即满足
Q
(
i
,
j
)
=
Q
(
j
,
i
)
Q(i, j)=Q(j, i)
Q(i,j)=Q(j,i),这时我们的接受率可以 进一步简化为:
α
(
i
,
j
)
=
min
{
π
(
j
)
π
(
i
)
,
1
}
\alpha(i, j)=\min \left\{\frac{\pi(j)}{\pi(i)}, 1\right\}
α(i,j)=min{π(i)π(j),1}
M-H采样实例
为了更容易理解,这里给出一个M-H采样的实例。
在例子里,我们的目标平稳分布是一个均值3,标准差2的正态分布,而选择的马尔可夫链状态转移矩阵 Q ( i , j ) Q(i, j) Q(i,j)的条件转移概率是以 i i i 为均值,方差1的正态分布在位置 j j j 的值。这个例子仅仅用来让大家加深对M-H采样过程的理解。毕竟一个普通的一维正态分布用不着去用M-H采样来获得样本。
import random
import math
from scipy.stats import norm
import matplotlib.pyplot as plt
%matplotlib inline
def norm_dist_prob(theta):
y = norm.pdf(theta, loc=3, scale=2)
return y
T = 5000
pi = [0 for i in range(T)]
sigma = 1
t = 0
while t < T-1:
t = t + 1
pi_star = norm.rvs(loc=pi[t - 1], scale=sigma, size=1, random_state=None)
alpha = min(1, (norm_dist_prob(pi_star[0]) / norm_dist_prob(pi[t - 1])))
u = random.uniform(0, 1)
if u < alpha:
pi[t] = pi_star[0]
else:
pi[t] = pi[t - 1]
plt.scatter(pi, norm.pdf(pi, loc=3, scale=2))
num_bins = 50
plt.hist(pi, num_bins, normed=1, facecolor='red', alpha=0.7)
plt.show()
输出的图中可以看到采样值的分布与真实的分布之间的关系如下,采样集还是比较拟合对应分布的。
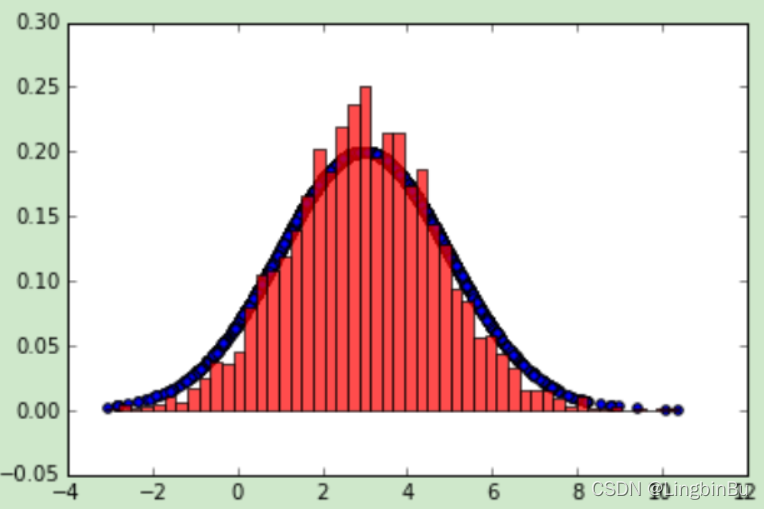
M-H采样总结
M-H采样完整解决了使用蒙特卡罗方法需要的任意概率分布样本集的问题,因此在实际生产环境得到了广泛的应用,但是在大数据时代,M-H采样面临着两大难题:
- 我们的数据特征非常的多,M-H采样由于接受率计算式 π ( j ) Q ( j , i ) π ( i ) Q ( i , j ) \frac{\pi(j) Q(j, i)}{\pi(i) Q(i, j)} π(i)Q(i,j)π(j)Q(j,i) 的存在,在高维时需要的计算时间非常的可观,算法效率很低。同时 α ( i , j ) \alpha(i, j) α(i,j) 一般小于1,有时候辛苦计算出来却被拒绝了。能不能做到不拒绝转移呢?
- 由于特征维度大,很多时候我们甚至很难求出目标的各特征维度联合分布,但是可以方便求出各个特征之间的条件概率分布。这时候我们能不能只有各维度之间条件概率分布的情况下方便的采样呢?
Gibbs采样解决了上面两个问题,因此在大数据时代,MCMC采样基本是Gibbs采样的天下,下一篇我们就来讨论Gibbs采样。
5.1.3 吉布斯采样(Gibbs采样)
重新寻找合适的细致平稳条件
在上一篇中,我们讲到了细致平稳条件:如果非周期马尔科夫链的状态转移矩阵
P
P
P 和概率分布
π
(
x
)
\pi(x)
π(x) 对于所有的
i
,
j
i, j
i,j 满足:
π
(
i
)
P
(
i
,
j
)
=
π
(
j
)
P
(
j
,
i
)
\pi(i) P(i, j)=\pi(j) P(j, i)
π(i)P(i,j)=π(j)P(j,i)
则称概率分布
π
(
x
)
\pi(x)
π(x) 是状态转移矩阵
P
P
P 的平稳分布。
在M-H采样中我们通过引入接受率使细致平稳条件满足。现在我们换一个思路。
从二维的数据分布开始,假设
π
(
x
1
,
x
2
)
\pi\left(x_{1}, x_{2}\right)
π(x1,x2) 是一个二维联合数据分布,观察第一个特征维度相同的两个 点
A
(
x
1
(
1
)
,
x
2
(
1
)
)
A\left(x_{1}^{(1)}, x_{2}^{(1)}\right)
A(x1(1),x2(1)) 和
B
(
x
1
(
1
)
,
x
2
(
2
)
)
B\left(x_{1}^{(1)}, x_{2}^{(2)}\right)
B(x1(1),x2(2)) ,容易发现下面两式成立:
π
(
x
1
(
1
)
,
x
2
(
1
)
)
π
(
x
2
(
2
)
∣
x
1
(
1
)
)
=
π
(
x
1
(
1
)
)
π
(
x
2
(
1
)
∣
x
1
(
1
)
)
π
(
x
2
(
2
)
∣
x
1
(
1
)
)
π
(
x
1
(
1
)
,
x
2
(
2
)
)
π
(
x
2
(
1
)
∣
x
1
(
1
)
)
=
π
(
x
1
(
1
)
)
π
(
x
2
(
2
)
∣
x
1
(
1
)
)
π
(
x
2
(
1
)
∣
x
1
(
1
)
)
\begin{aligned} &\pi\left(x_{1}^{(1)}, x_{2}^{(1)}\right) \pi\left(x_{2}^{(2)} \mid x_{1}^{(1)}\right)=\pi\left(x_{1}^{(1)}\right) \pi\left(x_{2}^{(1)} \mid x_{1}^{(1)}\right) \pi\left(x_{2}^{(2)} \mid x_{1}^{(1)}\right) \\ &\pi\left(x_{1}^{(1)}, x_{2}^{(2)}\right) \pi\left(x_{2}^{(1)} \mid x_{1}^{(1)}\right)=\pi\left(x_{1}^{(1)}\right) \pi\left(x_{2}^{(2)} \mid x_{1}^{(1)}\right) \pi\left(x_{2}^{(1)} \mid x_{1}^{(1)}\right) \end{aligned}
π(x1(1),x2(1))π(x2(2)∣x1(1))=π(x1(1))π(x2(1)∣x1(1))π(x2(2)∣x1(1))π(x1(1),x2(2))π(x2(1)∣x1(1))=π(x1(1))π(x2(2)∣x1(1))π(x2(1)∣x1(1))
由于两式的右边相等,因此我们有:
π
(
x
1
(
1
)
,
x
2
(
1
)
)
π
(
x
2
(
2
)
∣
x
1
(
1
)
)
=
π
(
x
1
(
1
)
,
x
2
(
2
)
)
π
(
x
2
(
1
)
∣
x
1
(
1
)
)
\pi\left(x_{1}^{(1)}, x_{2}^{(1)}\right) \pi\left(x_{2}^{(2)} \mid x_{1}^{(1)}\right)=\pi\left(x_{1}^{(1)}, x_{2}^{(2)}\right) \pi\left(x_{2}^{(1)} \mid x_{1}^{(1)}\right)
π(x1(1),x2(1))π(x2(2)∣x1(1))=π(x1(1),x2(2))π(x2(1)∣x1(1))
也就是:
π
(
A
)
π
(
x
2
(
2
)
∣
x
1
(
1
)
)
=
π
(
B
)
π
(
x
2
(
1
)
∣
x
1
(
1
)
)
\pi(A) \pi\left(x_{2}^{(2)} \mid x_{1}^{(1)}\right)=\pi(B) \pi\left(x_{2}^{(1)} \mid x_{1}^{(1)}\right)
π(A)π(x2(2)∣x1(1))=π(B)π(x2(1)∣x1(1))
观察上式再观察细致平稳条件的公式,我们发现在
x
1
=
x
1
(
1
)
x_{1}=x_{1}^{(1)}
x1=x1(1) 这条直线上,如果用条件概率分布
π
(
x
2
∣
x
1
(
1
)
)
\pi\left(x_{2} \mid x_{1}^{(1)}\right)
π(x2∣x1(1)) 作为马尔 科夫链的状态转移概率,则任意两个点之间的转移满足细致平稳条件!这真是一个开心的发现,同样的道理,在
x
2
=
x
2
(
1
)
x_{2}=x_{2}^{(1)}
x2=x2(1) 这条直线上,如果用条件概率分布
π
(
x
1
∣
x
2
(
1
)
)
\pi\left(x_{1} \mid x_{2}^{(1)}\right)
π(x1∣x2(1)) 作为马尔科夫链的状态转移概率,则任意两个点之间的转移也满足 细致平稳条件。那是因为假如有一点
C
(
x
1
(
2
)
,
x
2
(
1
)
)
C\left(x_{1}^{(2)}, x_{2}^{(1)}\right)
C(x1(2),x2(1)) ,我们可以得到:
π
(
A
)
π
(
x
1
(
2
)
∣
x
2
(
1
)
)
=
π
(
C
)
π
(
x
1
(
1
)
∣
x
2
(
1
)
)
\pi(A) \pi\left(x_{1}^{(2)} \mid x_{2}^{(1)}\right)=\pi(C) \pi\left(x_{1}^{(1)} \mid x_{2}^{(1)}\right)
π(A)π(x1(2)∣x2(1))=π(C)π(x1(1)∣x2(1))
基于上面的发现,我们可以这样构造分布
π
(
x
1
,
x
2
)
\pi\left(x_{1}, x_{2}\right)
π(x1,x2) 的马尔可夫链对应的状态转移矩阵
P
P
P :
P
(
A
→
B
)
=
π
(
x
2
(
B
)
∣
x
1
(
1
)
)
if
x
1
(
A
)
=
x
1
(
B
)
=
x
1
(
1
)
P
(
A
→
C
)
=
π
(
x
1
(
C
)
∣
x
2
(
1
)
)
if
x
2
(
A
)
=
x
2
(
C
)
=
x
2
(
1
)
P
(
A
→
D
)
=
0
else
\begin{aligned} P(A \rightarrow B)=& \pi\left(x_{2}^{(B)} \mid x_{1}^{(1)}\right) \text { if } x_{1}^{(A)}=x_{1}^{(B)}=x_{1}^{(1)} \\ P(A \rightarrow C)=& \pi\left(x_{1}^{(C)} \mid x_{2}^{(1)}\right) \text { if } x_{2}^{(A)}=x_{2}^{(C)}=x_{2}^{(1)} \\ & P(A \rightarrow D)=0 \text { else } \end{aligned}
P(A→B)=P(A→C)=π(x2(B)∣x1(1)) if x1(A)=x1(B)=x1(1)π(x1(C)∣x2(1)) if x2(A)=x2(C)=x2(1)P(A→D)=0 else
有了上面这个状态转移矩阵,我们很容易验证平面上的任意两点
E
,
F
E, F
E,F ,满足细致平稳条件:
π
(
E
)
P
(
E
→
F
)
=
π
(
F
)
P
(
F
→
E
)
\pi(E) P(E \rightarrow F)=\pi(F) P(F \rightarrow E)
π(E)P(E→F)=π(F)P(F→E)
二维Gibbs采样
利用上一节找到的状态转移矩阵,我们就得到了二维Gibbs采样,这个采样需要两个维度之间的条件概率。具体过程如下:
- 输入平稳分布 π ( x 1 , x 2 ) \pi\left(x_{1}, x_{2}\right) π(x1,x2) ,设定状态转移次数阈值 n 1 n_{1} n1 ,需要的样本个数 n 2 n_{2} n2
- 随机初始化初始状态值 x 1 ( 0 ) x_{1}^{(0)} x1(0) 和 x 2 ( 0 ) x_{2}^{(0)} x2(0)
- for
t
=
0
t=0
t=0 to
n
1
+
n
2
−
1
n_{1}+n_{2}-1
n1+n2−1 :
a) 从条件概率分布 P ( x 2 ∣ x 1 ( t ) ) P\left(x_{2} \mid x_{1}^{(t)}\right) P(x2∣x1(t)) 中采样得到样本 x 2 t + 1 x_{2}^{t+1} x2t+1
b) 从条件概率分布 P ( x 1 ∣ x 2 ( t + 1 ) ) P\left(x_{1} \mid x_{2}^{(t+1)}\right) P(x1∣x2(t+1)) 中采样得到样本 x 1 t + 1 x_{1}^{t+1} x1t+1
样本集 { ( x 1 ( n 1 ) , x 2 ( n 1 ) ) , ( x 1 ( n 1 + 1 ) , x 2 ( n 1 + 1 ) ) , … , ( x 1 ( n 1 + n 2 − 1 ) , x 2 ( n 1 + n 2 − 1 ) ) } \left\{\left(x_{1}^{\left(n_{1}\right)}, x_{2}^{\left(n_{1}\right)}\right),\left(x_{1}^{\left(n_{1}+1\right)}, x_{2}^{\left(n_{1}+1\right)}\right), \ldots,\left(x_{1}^{\left(n_{1}+n_{2}-1\right)}, x_{2}^{\left(n_{1}+n_{2}-1\right)}\right)\right\} {(x1(n1),x2(n1)),(x1(n1+1),x2(n1+1)),…,(x1(n1+n2−1),x2(n1+n2−1))} 即为我们需要的平稳分布对应的样本集。
整个采样过程中,我们通过轮换坐标轴,采样的过程为:
( x 1 ( 1 ) , x 2 ( 1 ) ) → ( x 1 ( 1 ) , x 2 ( 2 ) ) → ( x 1 ( 2 ) , x 2 ( 2 ) ) → … → ( x 1 ( n 1 + n 2 − 1 ) , x 2 ( n 1 + n 2 − 1 ) ) \left(x_{1}^{(1)}, x_{2}^{(1)}\right) \rightarrow\left(x_{1}^{(1)}, x_{2}^{(2)}\right) \rightarrow\left(x_{1}^{(2)}, x_{2}^{(2)}\right) \rightarrow \ldots \rightarrow\left(x_{1}^{\left(n_{1}+n_{2}-1\right)}, x_{2}^{\left(n_{1}+n_{2}-1\right)}\right) (x1(1),x2(1))→(x1(1),x2(2))→(x1(2),x2(2))→…→(x1(n1+n2−1),x2(n1+n2−1))
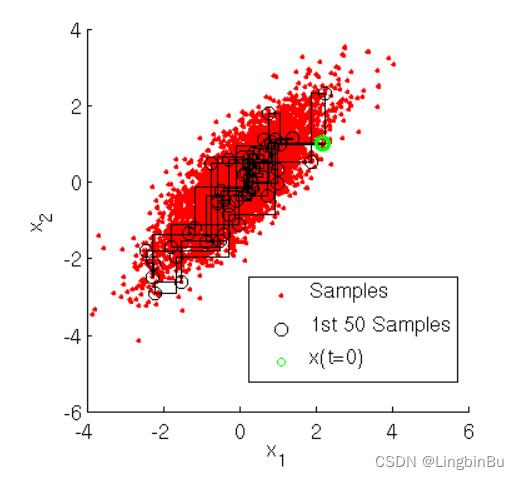
用下图可以很直观的看出,采样是在两个坐标轴上不停的轮换的。当然,坐标轴轮换不是必须的,我们也可以每次随机选择一个坐标轴进行采样。不过常用的Gibbs采样的实现都是基于坐标轴轮换的。
多维Gibbs采样
上面的这个算法推广到多维的时候也是成立的。比如一个
n
n
n 维的概率分布
π
(
x
1
,
x
2
,
…
x
n
)
\pi\left(x_{1}, x_{2}, \ldots x_{n}\right)
π(x1,x2,…xn) ,我们可以通过在
n
n
n 个坐标 轴上轮换采样,来得到新的样本。对于轮换到的任意一个坐标轴
x
i
x_{i}
xi 上的转移,马尔科夫链的状态转移概率 为
P
(
x
i
∣
x
1
,
x
2
,
…
,
x
i
−
1
,
x
i
+
1
,
…
,
x
n
)
P\left(x_{i} \mid x_{1}, x_{2}, \ldots, x_{i-1}, x_{i+1}, \ldots, x_{n}\right)
P(xi∣x1,x2,…,xi−1,xi+1,…,xn) ,即固定
n
−
1
n-1
n−1 个坐标轴,在某一个坐标轴上移动。
具体的算法过程如下:
- 输入平稳分布
π
(
x
1
,
x
2
,
…
,
x
n
)
\pi\left(x_{1}, x_{2}, \ldots, x_{n}\right)
π(x1,x2,…,xn) 或者对应的所有特征的条件概率分布,设定状态转移次数阈值
n
1
n_{1}
n1 ,需要的样本
个数 n 2 n_{2} n2 - 随机初始化初始状态值 ( x 1 ( 0 ) , x 2 ( 0 ) , … , x n ( 0 ) \left(x_{1}^{(0)}, x_{2}^{(0)}, \ldots, x_{n}^{(0)}\right. (x1(0),x2(0),…,xn(0)
- for
t
=
0
t=0
t=0 to
n
1
+
n
2
−
1
n_{1}+n_{2}-1
n1+n2−1 :
a) 从条件概率分布 P ( x 1 ∣ x 2 ( t ) , x 3 ( t ) , … , x n ( t ) ) P\left(x_{1} \mid x_{2}^{(t)}, x_{3}^{(t)}, \ldots, x_{n}^{(t)}\right) P(x1∣x2(t),x3(t),…,xn(t)) 中采样得到样本 x 1 t + 1 x_{1}^{t+1} x1t+1
b) 从条件概率分布 P ( x 2 ∣ x 1 ( t + 1 ) , x 3 ( t ) , x 4 ( t ) , … , x n ( t ) ) P\left(x_{2} \mid x_{1}^{(t+1)}, x_{3}^{(t)}, x_{4}^{(t)}, \ldots, x_{n}^{(t)}\right) P(x2∣x1(t+1),x3(t),x4(t),…,xn(t)) 中采样得到样本 x 2 t + 1 x_{2}^{t+1} x2t+1
C)…
d) 从条件概率分布 P ( x j ∣ x 1 ( t + 1 ) , x 2 ( t + 1 ) , … , x j − 1 ( t + 1 ) , x j + 1 ( t ) … , x n ( t ) ) P\left(x_{j} \mid x_{1}^{(t+1)}, x_{2}^{(t+1)}, \ldots, x_{j-1}^{(t+1)}, x_{j+1}^{(t)} \ldots, x_{n}^{(t)}\right) P(xj∣x1(t+1),x2(t+1),…,xj−1(t+1),xj+1(t)…,xn(t)) 中采样得到样本 x j t + 1 x_{j}^{t+1} xjt+1
e)…
f) 从条件概率分布 P ( x n ∣ x 1 ( t + 1 ) , x 2 ( t + 1 ) , … , x n − 1 ( t + 1 ) ) P\left(x_{n} \mid x_{1}^{(t+1)}, x_{2}^{(t+1)}, \ldots, x_{n-1}^{(t+1)}\right) P(xn∣x1(t+1),x2(t+1),…,xn−1(t+1)) 中采样得到样本 x n t + 1 x_{n}^{t+1} xnt+1
样本集 { ( x 1 ( n 1 ) , x 2 ( n 1 ) , … , x n ( n 1 ) ) , … , ( x 1 ( n 1 + n 2 − 1 ) , x 2 ( n 1 + n 2 − 1 ) , … , x n ( n 1 + n 2 − 1 ) ) } \left\{\left(x_{1}^{\left(n_{1}\right)}, x_{2}^{\left(n_{1}\right)}, \ldots, x_{n}^{\left(n_{1}\right)}\right), \ldots,\left(x_{1}^{\left(n_{1}+n_{2}-1\right)}, x_{2}^{\left(n_{1}+n_{2}-1\right)}, \ldots, x_{n}^{\left(n_{1}+n_{2}-1\right)}\right)\right\} {(x1(n1),x2(n1),…,xn(n1)),…,(x1(n1+n2−1),x2(n1+n2−1),…,xn(n1+n2−1))} 即为我们需要的平稳分布对应 的样本集。
整个采样过程和Lasso回归的坐标轴下隆法算法非常类似,只不过Lasso回归是固定
n
一
1
n一1
n一1 个特征,对某一个特征求极值。而Gibbs采样是固定
n
一
1
n一1
n一1 个特征在某一个特征采样。
同样的,轮换坐标轴不是必须的,我们可以随机选择某一个坐标轴进行状态转移,只不过常用的Gibbs采样的实现都是基于坐标轴轮换的。
二维Gibbs采样实例
这里给出一个Gibbs采样的例子。完整代码参见我的github: https://github.com/ljpzzz/machinelearning/blob /master/mathematics/mcmc_3_4.ipynb
假设我们要采样的是一个二维正态分布
Norm
(
μ
,
Σ
)
\operatorname{Norm}(\mu, \Sigma)
Norm(μ,Σ), 其中:
μ
=
(
μ
1
,
μ
2
)
=
(
5
,
−
1
)
Σ
=
(
σ
1
2
ρ
σ
1
σ
2
ρ
σ
1
σ
2
σ
2
2
)
=
(
1
1
1
4
)
\begin{gathered} \mu=\left(\mu_{1}, \mu_{2}\right)=(5,-1) \\ \Sigma=\left(\begin{array}{cc} \sigma_{1}^{2} & \rho \sigma_{1} \sigma_{2} \\ \rho \sigma_{1} \sigma_{2} & \sigma_{2}^{2} \end{array}\right)=\left(\begin{array}{ll} 1 & 1 \\ 1 & 4 \end{array}\right) \end{gathered}
μ=(μ1,μ2)=(5,−1)Σ=(σ12ρσ1σ2ρσ1σ2σ22)=(1114)
而采样过程中的需要的状态转移条件分布为:
P
(
x
1
∣
x
2
)
=
Norm
(
μ
1
+
ρ
σ
1
/
σ
2
(
x
2
−
μ
2
)
,
(
1
−
ρ
2
)
σ
1
2
)
P
(
x
2
∣
x
1
)
=
Norm
(
μ
2
+
ρ
σ
2
/
σ
1
(
x
1
−
μ
1
)
,
(
1
−
ρ
2
)
σ
2
2
)
\begin{aligned} &P\left(x_{1} \mid x_{2}\right)=\operatorname{Norm}\left(\mu_{1}+\rho \sigma_{1} / \sigma_{2}\left(x_{2}-\mu_{2}\right),\left(1-\rho^{2}\right) \sigma_{1}^{2}\right) \\ &P\left(x_{2} \mid x_{1}\right)=\operatorname{Norm}\left(\mu_{2}+\rho \sigma_{2} / \sigma_{1}\left(x_{1}-\mu_{1}\right),\left(1-\rho^{2}\right) \sigma_{2}^{2}\right) \end{aligned}
P(x1∣x2)=Norm(μ1+ρσ1/σ2(x2−μ2),(1−ρ2)σ12)P(x2∣x1)=Norm(μ2+ρσ2/σ1(x1−μ1),(1−ρ2)σ22)
具体的代码如下:
import math
import random
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.stats import multivariate_normal
samplesource = multivariate_normal(mean=[5,-1], cov=[[1,1],[1,4]])
def p_ygivenx(x, m1, m2, s1, s2):
return (random.normalvariate(m2 + rho * s2 / s1 * (x - m1), math.sqrt((1 - rho ** 2) * (s2**2))))
def p_xgiveny(y, m1, m2, s1, s2):
return (random.normalvariate(m1 + rho * s1 / s2 * (y - m2), math.sqrt((1 - rho ** 2) * (s1**2))))
N = 5000
K = 20
x_res = []
y_res = []
z_res = []
m1 = 5
m2 = -1
s1 = 1
s2 = 2
rho = 0.5
y = m2
for i in range(N):
for j in range(K):
x = p_xgiveny(y, m1, m2, s1, s2)
y = p_ygivenx(x, m1, m2, s1, s2)
z = samplesource.pdf([x,y])
x_res.append(x)
y_res.append(y)
z_res.append(z)
num_bins = 50
plt.hist(x_res, num_bins, normed=1, facecolor='green', alpha=0.5)
plt.hist(y_res, num_bins, normed=1, facecolor='red', alpha=0.5)
plt.title('Histogram')
plt.show()
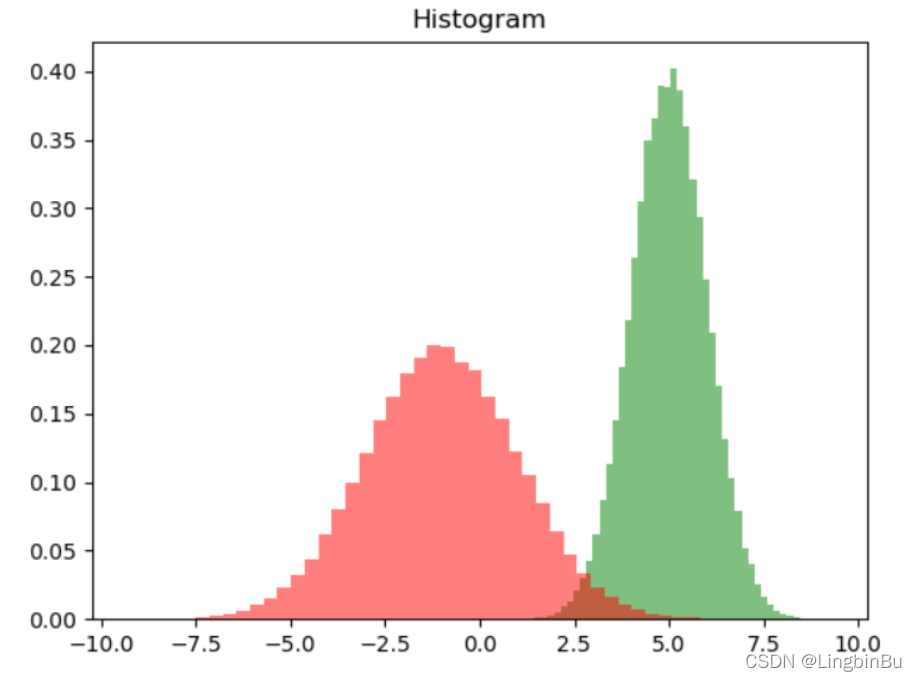
然后我们看看样本集生成的二维正态分布,代码如下:
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=30, azim=20)
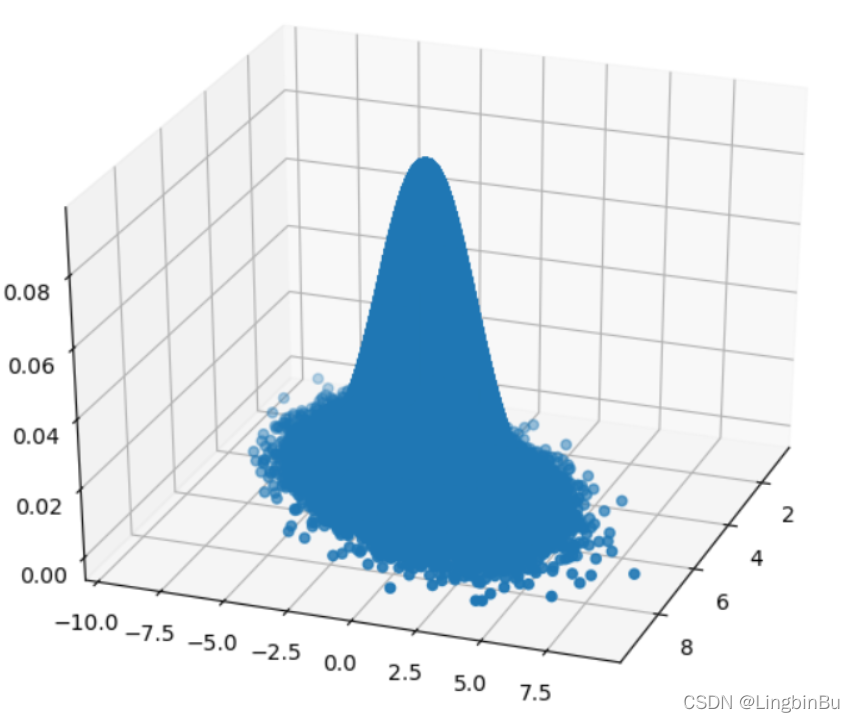
ax.scatter(x_res, y_res, z_res,marker='o')
plt.show()
Gibbs采样小结
由于Gibbs采样在高维特征时的优势,目前我们通常意义上的MCMC采样都是用的Gibbs采样。当然Gibbs采样是从M-H采样的基础上的进化而来的,同时Gbbs采样要求数据至少有两个维度,一维概率分布的采样是没法用Gibbs采样的,这时M-H采样仍然成立。
有了Gbbs采样来获取概率分布的样本集,有了蒙特卡罗方法来用样本集模拟求和,他们一起就奠定了MCMC算法在大数据时代高维数据模拟求和时的作用。MCMC系列就在这里结束吧。
参考文章
[1] https://blog.csdn.net/anne033/article/details/109322076 对采样的理解
[2] https://zhuanlan.zhihu.com/p/125648419 机器学习——采样
[3] https://zhuanlan.zhihu.com/p/46096712 对采样的理解
[4] https://www.cnblogs.com/emanlee/p/12356492.html 蒙特卡罗方法 Monte Carlo method

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









