






最近面试有要求手撕SGD,这里顺便就把梯度下降、随机梯度下降、批次梯度下降给写出来了
有几个注意点:
1.求梯度时注意label[i]和pred[i]不要搞反,否则会导致模型发散
2.如果跑了几千个epoch,还是没有收敛,可能是学习率太小了
# X:n*k
# Y: n*1
import random
import numpy
class GD:
def __init__(self,w_dim,r):
# 随机初始化
self.w = [random.random() for _ in range(w_dim)]
self.bias = random.random()
self.learningRate = r
print(f"original w is {self.w}, original bias is {self.bias}")
def forward(self,x):
# 前馈网络
ans = []
for i in range(len(x)):
y=0
for j in range(len(x[0])):
y+=self.w[j]*x[i][j]
ans.append(y+self.bias)
return ans
def bp(self,X,pred,label,op="GD"):
# 计算均方差
loss = 0
for i in range(len(pred)):
loss+=(label[i]-pred[i])**2
loss = loss/len(X)
# 计算梯度
# 梯度下降
if op=="GD":
grad_w = [0 for _ in range(len(self.w))]
grad_bias=0
for i in range(len(X)):
grad_bias+=-2*(label[i]-pred[i])
for j in range(len(self.w)):
grad_w[j]+=-2*(label[i]-pred[i])*X[i][j]
# 反向传播,更新梯度
self.bias=self.bias-self.learningRate*grad_bias/len(X)
for i in range(len(self.w)):
self.w[i]-=self.learningRate*grad_w[i]/len(X)
# 随机梯度下降
if op=="SGD":
grad_w = [0 for _ in range(len(self.w))]
grad_bias=0
randInd = random.randint(0,len(X)-1)
grad_bias+=-2*(label[randInd]-pred[randInd])
for j in range(len(self.w)):
grad_w[j]+=-2*(label[randInd]-pred[randInd])*X[randInd][j]
# 反向传播,更新梯度
self.bias=self.bias-self.learningRate*grad_bias
for i in range(len(self.w)):
self.w[i]-=self.learningRate*grad_w[i]
# 批次梯度下降
if op=="BGD":
grad_w = [0 for _ in range(len(self.w))]
grad_bias=0
BS=8
randInd = random.randint(0,len(X)/BS-1)
X = X[BS*randInd:BS*(randInd+1)]
label = label[BS*randInd:BS*(randInd+1)]
pred = pred[BS*randInd:BS*(randInd+1)]
for i in range(len(X)):
grad_bias+=-2*(label[i]-pred[i])
for j in range(len(self.w)):
grad_w[j]+=-2*(label[i]-pred[i])*X[i][j]
# 反向传播,更新梯度
self.bias=self.bias-self.learningRate*grad_bias/len(X)
for i in range(len(self.w)):
self.w[i]-=self.learningRate*grad_w[i]/len(X)
return loss
def testY(X,w):
Y = []
for x in X:
y=0
for i in range(len(x)):
y+=w[i]*x[i]
Y.append(y)
return Y
# 构建数据
n = 1000
X=[[random.random() for _ in range(2)] for _ in range(n)]
w=[0.2,0.3]
B=0.4
Y = testY(X,w)
# 设置样本维度为2
k = 2
lr = GD(k,0.01)
Loss=0
epochs=2000
for e in range(epochs):
Loss = 0
pred = lr.forward(X)
loss=lr.bp(X,pred,Y,"BGD")
Loss+=loss
if (e%100)==0:
print(f"step:{e},Loss:{Loss}")
X_test=[[random.random() for _ in range(2)] for _ in range(2)]
Y_test=testY(X_test,w)
print("X_test=",X_test)
print("Y_test=",Y_test)
print("Y_pred=",lr.forward(X_test))
测试效果如下:
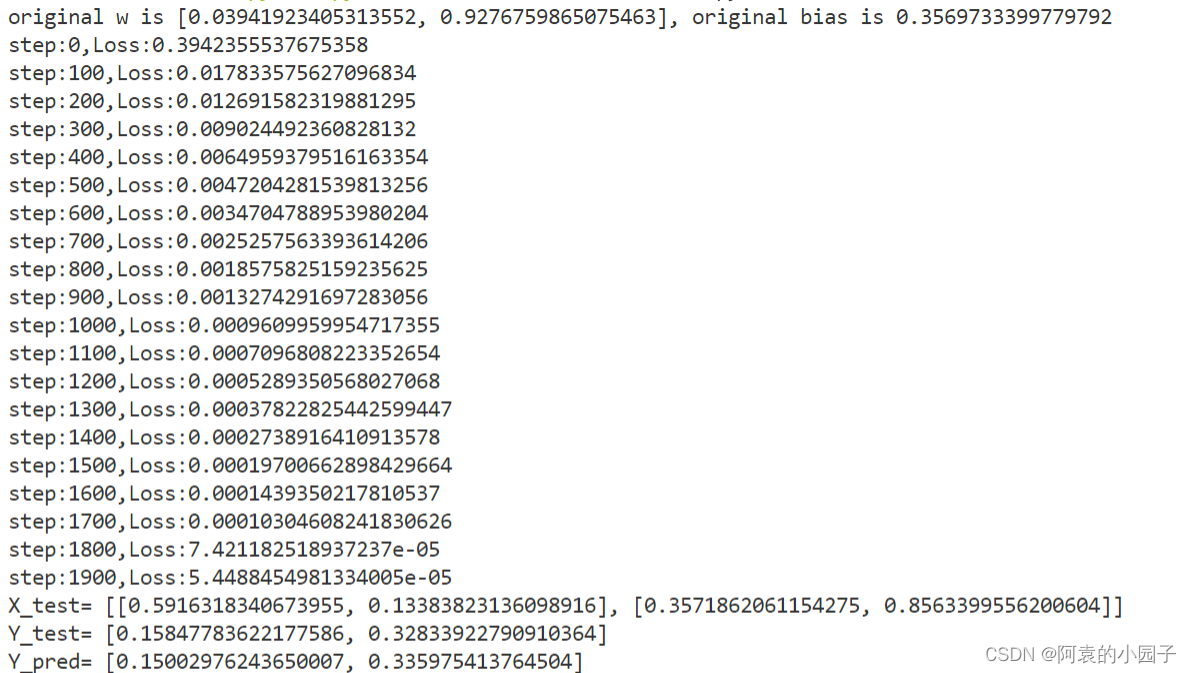
也还行














 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









