






OpenMMLab 实战营打卡 - 第 4 课
注:本博客仅用于个人上课随手笔记
计算机视觉之目标检测
一、上课笔记
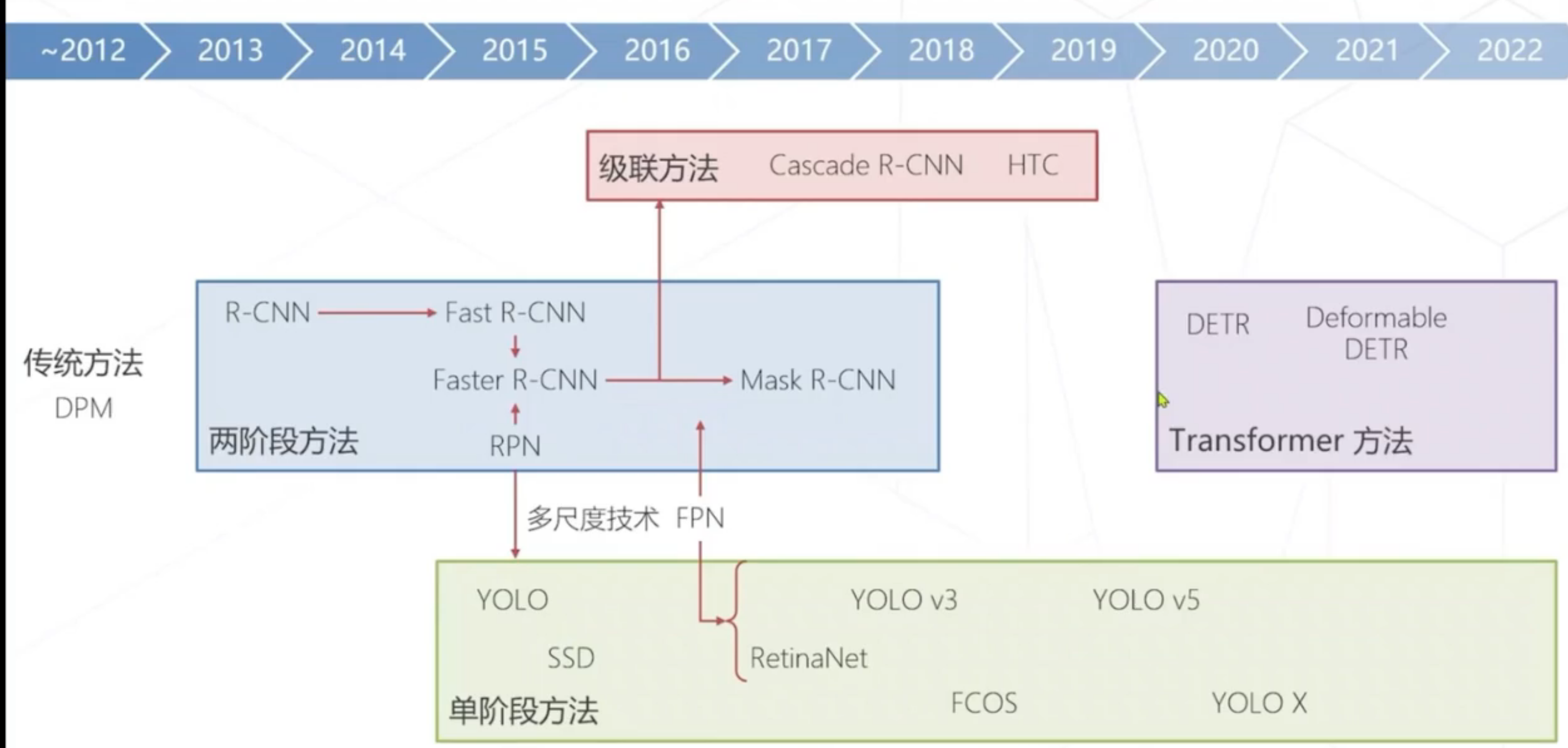
目标检测技术演进
传统方法:使用滑动窗口预测,事先设定好预测框,推断 目标是否在预先设定的框中,但是效率太低,代价无法忍受。
改进思路:1.启发式计算2.减少冗余计算(用卷积一次性算所有特征,然后取出对应特征分类避免重复)
推理精度,推理速度
新方法:在特征图上进行密集预测,利用卷积把特征图转换为概率图 。是一种隐式的滑动窗口思路,计算效率高。
目标检测的范式:
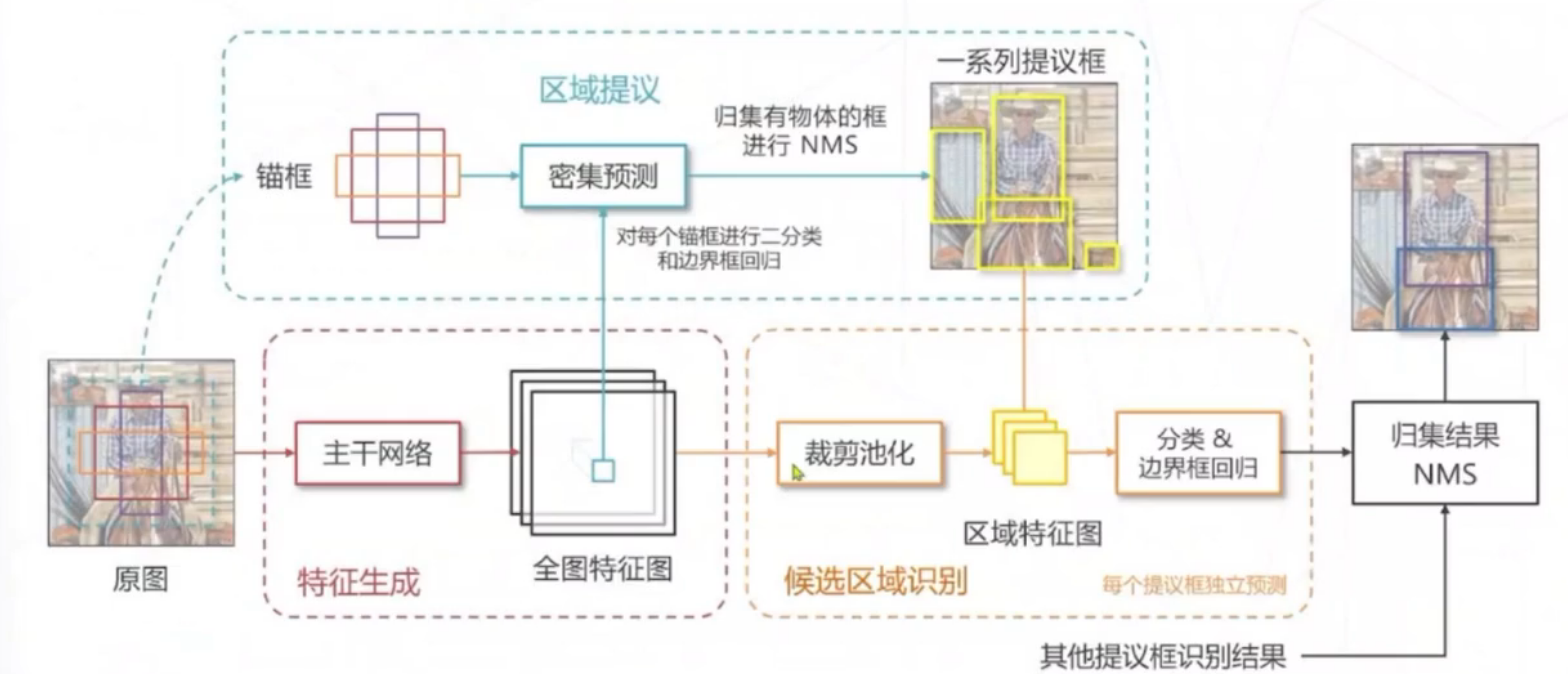
1.两阶段方法
双:先预选框,然后判断,准确率高,但由于预选框多,所消耗时间多,速度慢
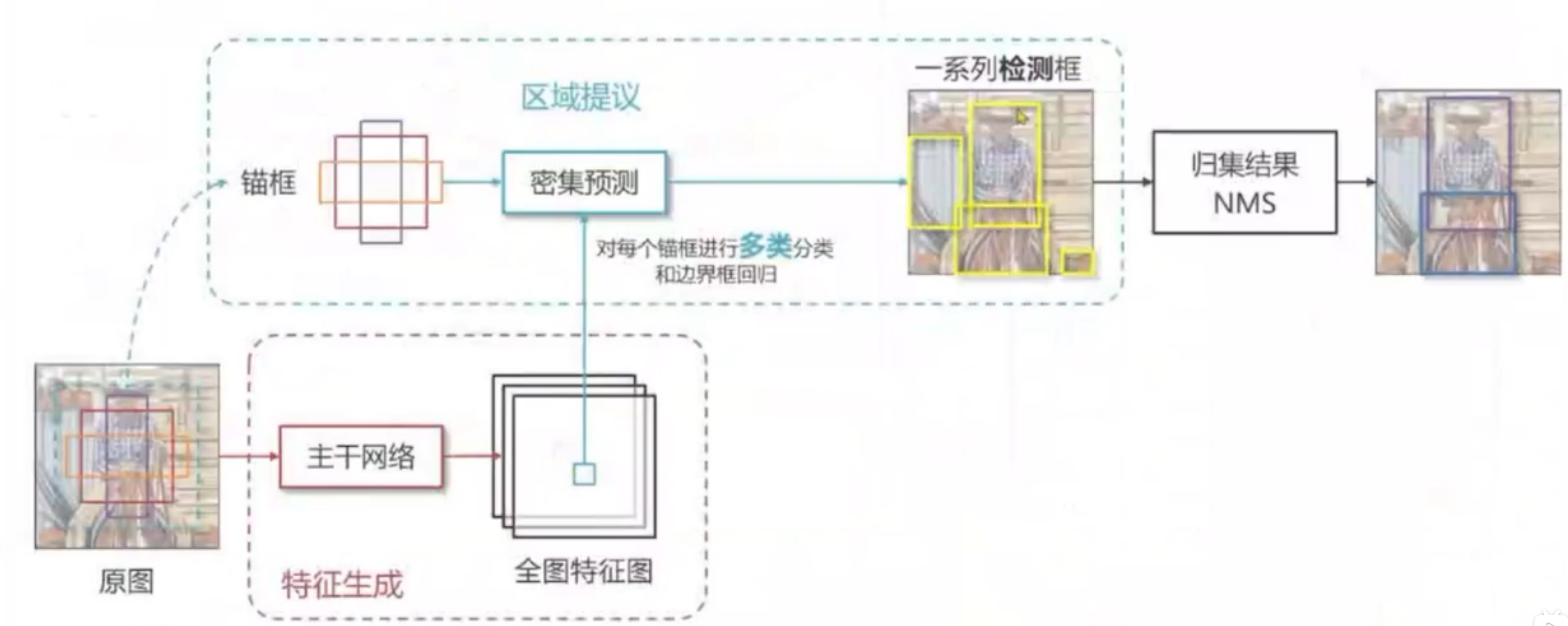
2.单阶段方法
单:直接用端到端神经网络,提取信息,速度快,但是精度低,对密集目标可能比较差。(如上述的密集预测)
目标检测技术演进:
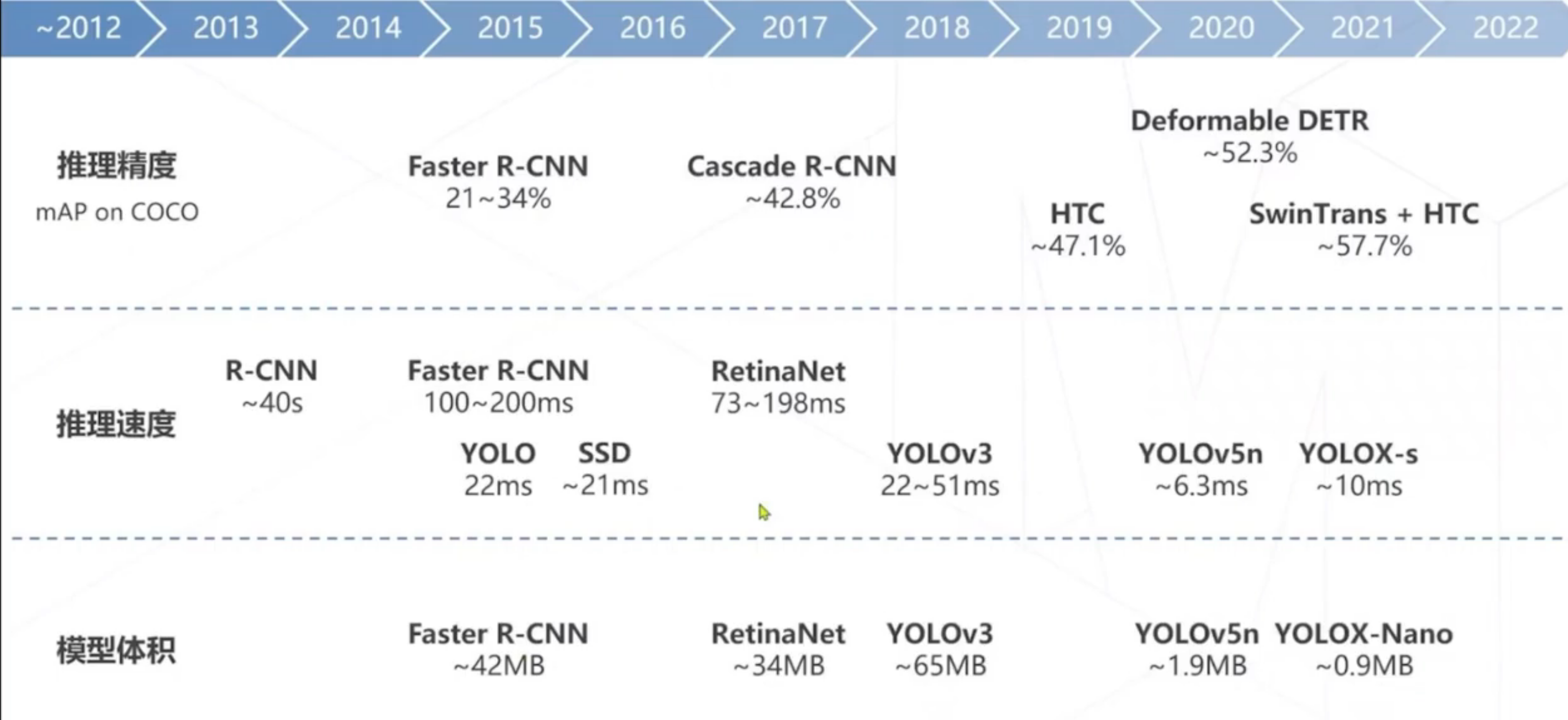
目标检测算法:
使用边界框(横平竖直)进行目标检测,一般描述框需要最基本的四个值(中心点x,y,框的长宽HW)
框同义词:区域,区域提议,感兴趣区域(ROI),锚框(Anchor Box)
衡量指标:IoU(交并比) 两框交集和并集之比。
置信度:模型认可自身预测结构的程度,通常每个框给一个置信度。
非极大值抑制:如一块目标区域有多个相近的框,取置信度最高的
其算法(NMS):

边界框回归:滑窗和物体精准边界有偏差,处理方法是让预测物体类别同时预测边界框相对滑窗的偏移量
因为绝对偏移量数值较大,不利于神经网络训练,通常对偏移量进行 编码,作为回归模型预测目标。
传统方法:使用区域提议,在图中找到包含物体的框,不需要区分类别(FAST-RCNN),但成本高。
他也存在局限,如图中如果有大小不同的物体,需要产生不同尺寸框;以及如果物体有重合,区域提议算法需要有能力在是同一位置产生不同尺寸的框。
改进:使用锚框,在原图上设置不同尺寸的基准框,基于特征独立预测每个锚框是否包含物体,可以解决上述问题。
继续改进,二分类->多分类,双阶段->单阶段,单阶段比较有名的是yolo,ssd,retinanet算法。
无锚框检测算法
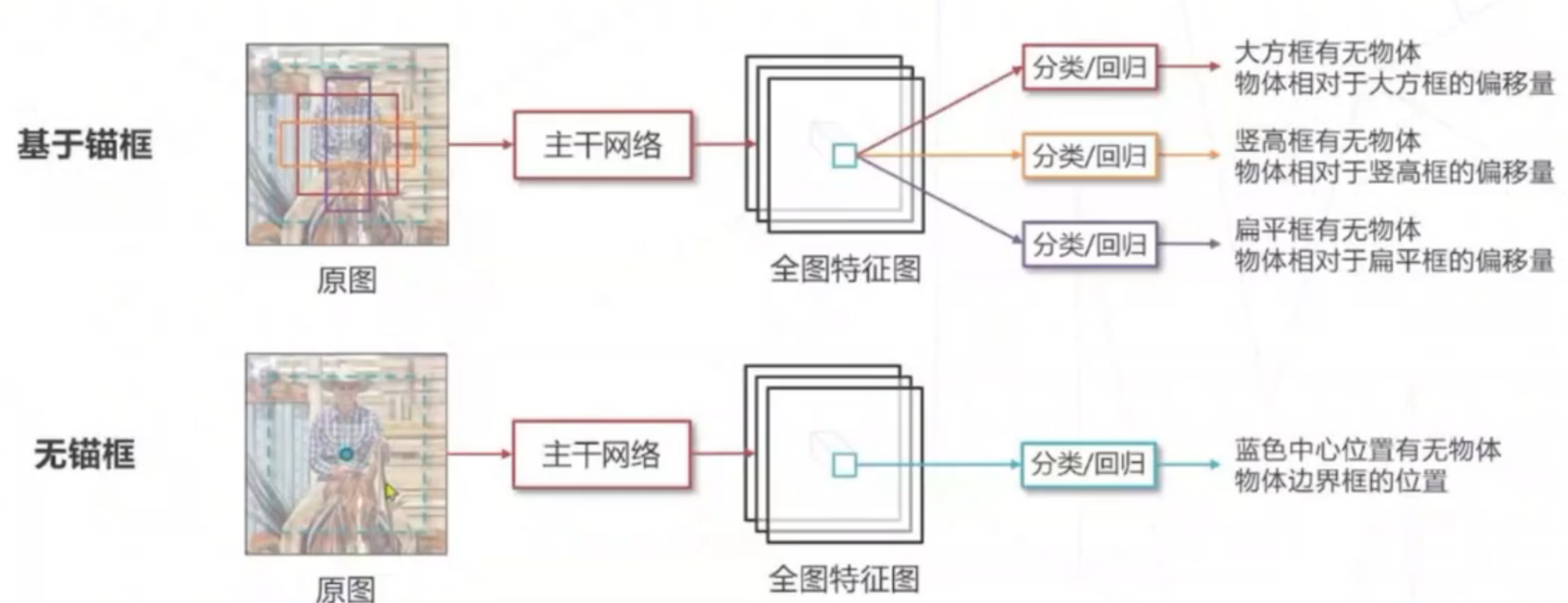
使用锚框是因为,同物体可能不同尺寸大小,并且同一位置可能有重叠。
无锚框:不基于框训练,直接基于语义。代表算法:FCOS,全卷积单阶段算法
以关键点位中心的目标检测:以中心点表示物体,将2D检测建模为关键点检测和额外回归任务,一个框架可以同时覆盖2D,3D检测。代表算法centernet
基于Transformer的目标检测:DETR.他脱离密集预测范式,将检测建模为了从特征序列到框序列的翻译问题,用Transformer模型解决(比VIT早).缺点是收敛慢。借鉴可分离卷积的思想,后面提出了可分离DETR来改进。
**评估指标:**使用mAP值来评估,是一种综合准确率和召回率的方案。
准确率:TP/(TP+FP) 召回率:TP/ (TP+FN)
TP: 算法检测到了某类物体(Positive),图中也确实有这个物体,检测结果正确(True)
FP:算法检测到了某类物体(Positive),图中并没有有这个物体,检测结果错误(False)
FN:算法没有检测到某类物体(Negative),图中但是存在这个物体,检测结果错误(False)
mAP计算方式:

二、个人心得
1.目标检测算法的锚框设计,是在原图上设置不同尺寸的基准框,基于特征独立预测每个锚框是否包含物体。这种思想或许可以使用在语义或者实例分割领域中,初始化一些锚框,优先将一张图片的前景和背景相互分离出来,然后基于每个锚框再做类别上的预测。这样可能会存在一些问题,比如分离前景边界不够细致,细节信息可能会缺失,而且每个检测锚框的类别预测错误会对整个任务造成巨大的损失。就传统语言分割而言,大多数任务是做像素级别的语义分割,因此基于这种锚框机制的来做语义分割可能需要重点解决如何确定损失函数和细节区域的分割的问题。现在目标检测的部分思想也已经运用到语义分割领域中,如借鉴了可变形DETR 的解码器的基于区域分类的maskformer模型,在目标检测,语言分割,实例分割任务上均取得了良好的结果。学习目标检测算法,对语义分割新方法的实践也有重要意义。
2.目前2D目标检测发展的重点还是在模型的进度和推理的速度上,其中yolov5的版本已经对这两点做的比较好了,目前企业上也已经开始部署运用。但是目前的目标检测框还是为横平竖直为主,现在也开始有做旋转框检测的算法,但目前更让我感兴趣的是3D的目标检测和三维场景重构算法。如22年提出的bevformer,是一种用在基于多摄像头的图形的3D检测和地图分割任务的模型,应用在自动驾驶领域。因此就我现在学习的语义分割而言,我也对目标检测和实例分割非常感兴趣,希望这些能够能够相互撞击形成灵感的火花。
提出的bevformer,是一种用在基于多摄像头的图形的3D检测和地图分割任务的模型,应用在自动驾驶领域。因此就我现在学习的语义分割而言,我也对目标检测和实例分割非常感兴趣,希望这些能够能够相互撞击形成灵感的火花。















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









