







(五)MMDetection 代码教学
AI实战营第五课!最热门的目标检测工具箱 MMDetection 来啦!本节课为如何使用 MMDetection 训练自己的模型!链接5 MMDetection 代码教学_哔哩哔哩_bilibili
目录
一、目标检测工具包MMDetection
MMDetection就是用于做目标检测的一个工具包,面向深度学习时代,首发在2018年,后续经过不断迭代出来1.0版本和2.0版本。

1.支持的模型和数据集
支持点云、视觉、多模态检测算法。
支持室内、室外场景的数据集。
60多篇论文复现,400多个预训练模型,可直接使用。

2.广泛应用

3.MMDetection可以做什么
MMDetection提供400余个性能优良的预训练模型,开箱即用,几行Python API即可调用强大的检测能力。
MMDetection涵盖60余个目标检测算法,并提供方便易用的工具,经过简单的配置文件改写和调参就可以训练自己的目标检测模型。
4.MMDetection环境搭建

二、MMDetection 项目
1.重要概念——配置文件
➢ 深度学习模型的训练涉及几个方面:
− 模型结构 模型有几层、每层多少通道数等等
− 数据集 用什么数据训练模型:数据集划分、数据文件路径、数据增强策略等等
− 训练策略 梯度下降算法、学习率参数、batch_size、训练总轮次、学习率变化策略等等
− 运行时 GPU、分布式环境配置等等
− 一些辅助功能 如打印日志、定时保存checkpoint等等
➢ 在 OpenMMLab 项目中,所有这些项目都涵盖在一个配置文件中,一个配置文件定义了一个完整的训练过程
− model 字段定义模型
− data 字段定义数据
− optimizer、lr_config 等字段定义训练策略
− load_from 字段定义与训练模型的参数文件
2.代码库结构
open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark (github.com)

3.配置文件的运作方式

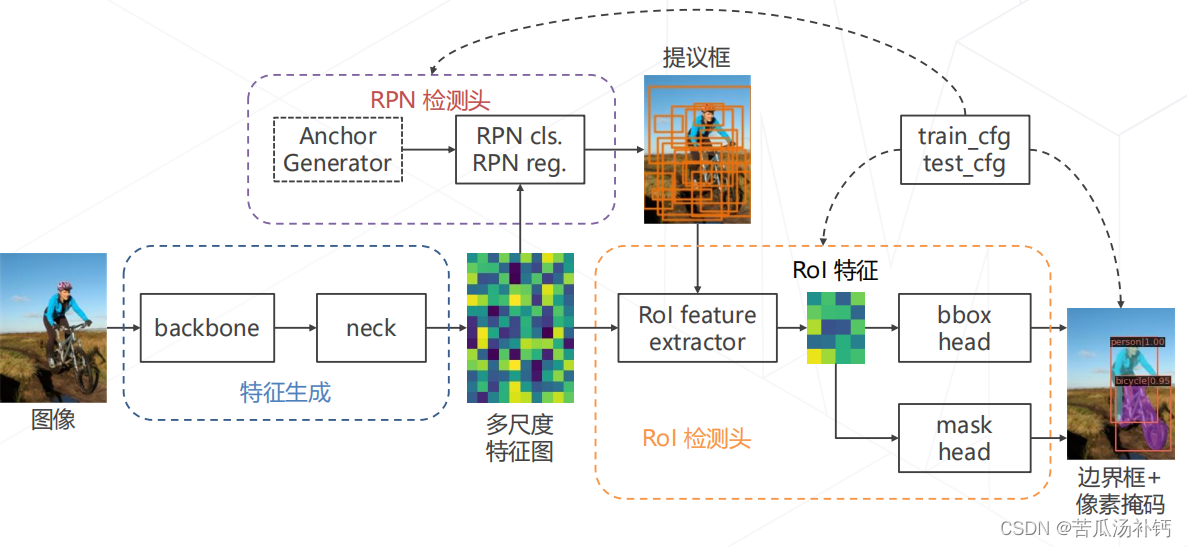
4.两段检测器的构成
5.单段检测器的构成

6.常用训练策略
通常使用SGD算法配合不同的学习率策略,所有策略均包含一个学习率升温过程。
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
7.训练自己的检测模型
通常基于微调训练:
• 使用基于COCO预训练的检测模型作为梯度下降的“起点”
• 使用自己的数据进行“微调训练”,通常需要降低学习率
具体到 MMDetection,需要:
• 选择一个基础模型,下载对应的配置文件和预训练模型的参数文件
• 将数据整理成MMDetection的支持的格式,如COCO格式或者自定义格式
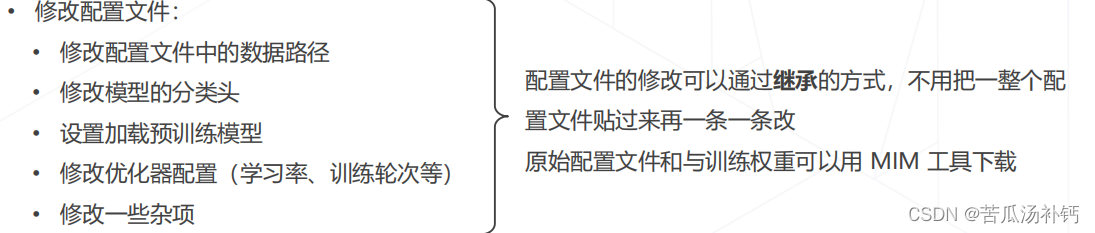
• 修改配置文件:
三、COCO数据集
1.数据集介绍
微软于2014年提出,最常用的是2017年版本。https://cocodataset.org/
• 全集 33W 张图像
• 针对多种任务进行了标注
• 80类、150W 物体标注用于目标检测与实例分割
2.数据集格式
完整的 COCO 数据集包含一系列单独存放的图片,和若干“标注文件”(annotation files),每个标注文件定义了一个数据子集,包含对应的图片路径,以及图片上的所有标注信息。

3.数据集标注格式

BBOX 标注格式

标注、类别、图像 id 的对应关系

4.在MMDetection中配置COCO数据集

四、MMDetection 中的自定义
1.数据集格式
[
{
'filename': 'a.jpg',
'width': 1280,
'height': 720, 'ann': {
'bboxes': <np.ndarray> (n, 4),
'labels': <np.ndarray> (n, ), 'bboxes_ignore': <np.ndarray> (k, 4), (optional field)
'labels_ignore': <np.ndarray> (k, ) (optional field),
'masks': [poly] }
},
...
]2.数据集
dataset_type = 'CustomDataset'
data_root = 'dataset_path/' #自定义数据集的根目录
classes=('clsname1','clasname2',...) #自定义数据集的类别名
#配置 batch_size
#配置 Dataloader 进程数
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
#针对训练、验证、测试子集,分别配置:
# 数据类型 = 自定义数据集
# 标注文件的路径(自定义格式中包含ndarray,需要用pkl格式)
# 图像目录的路径
# 数据处理流水线
train=dict(
type=dataset_type,
ann_file='train/custom_anno.pkl',
img_prefix='train',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file='val/custom_anno.pkl',
img_prefix='val',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file='val/custom_anno.pkl',
img_prefix='val',
pipeline=test_pipeline))3.数据处理流水线


五、MMDetection3D的安装和依赖
1.依赖
MMDetection3D总共有四个依赖,分别是基础库MMCV、用于检测与分割的MMDet和MMSeg,如果你使用的是1.1版本 MMDetection3D,它还依赖于MMEngine这个基础库。
















 2060
2060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









