






前天给大家整理了免费数据源网站合集,看大家的反馈很积极,有粉丝留言说,她还想要爬取一些网页的数据进行分析,不知道该如何下手
目前的用的比较多数据爬取方法是用python爬虫,这两年python很火,网上关于python爬虫的教程也很多,大家可以自行学习,但是对没有代码基础的朋友来说,短期上手python还是很困难的。
于是我就连日整理8个零代码数据爬取的工具,并附上使用教程,帮助一些没有爬虫基础的同学获取数据
1.Microsoft Excel
没错,第一个要介绍的就Excel,很多知道Excel可以用来做数据分析,但很少有人知道它还能用来爬数
步骤如下:
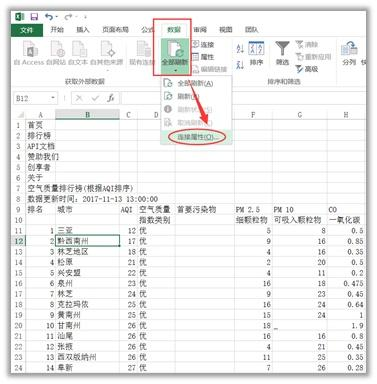
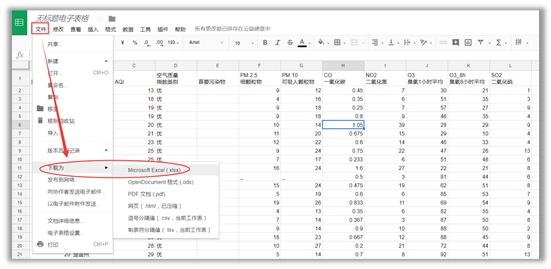
1)新建Excel,点击“数据”——“自网站”
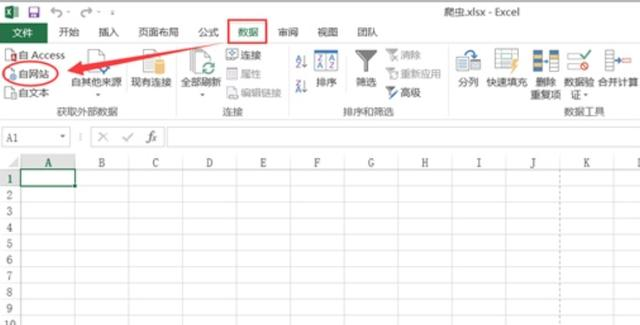
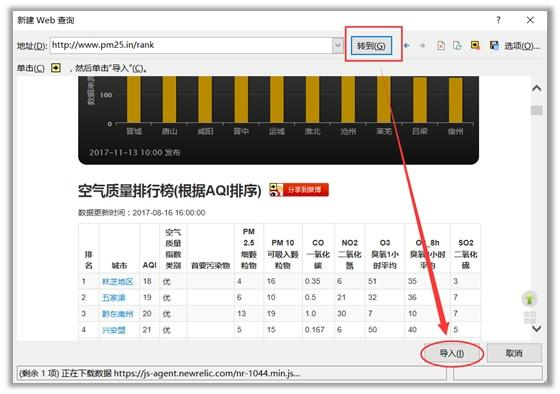
(2)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击转到,再导入
选择导入位置,确定
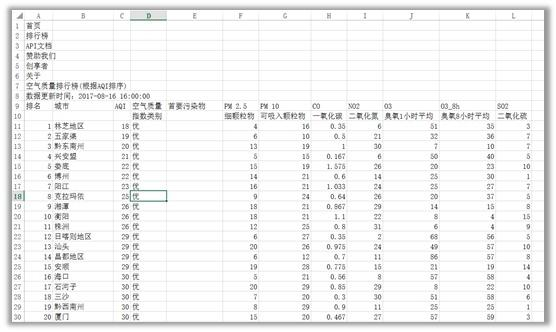
(3)结果如下图所示
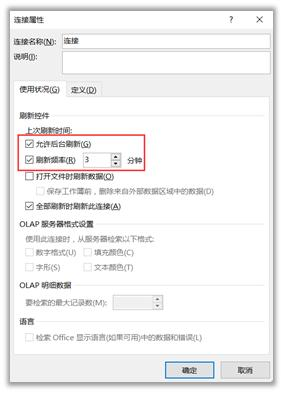
(4)如果要实时更新数据,可以在“数据”——“全部更新”——“连接属性”中进行设置,输入更新频率即可
缺点:这种方式虽然很简单,但是它会把页面上所有的文字信息都抓取过来,所以可能会抓取一部分我们不需要的数据,处理起来比较麻烦
火车头采集器
火车头是爬虫界的元老了,是目前使用人数最多的互联网数据抓取软件。它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。不过它规则和操作设置在我看来有一些死板,对小白用户来说上手也有点困难,需要有一定的网页知识基础
操作步骤:(以火车头8.6版本为准)
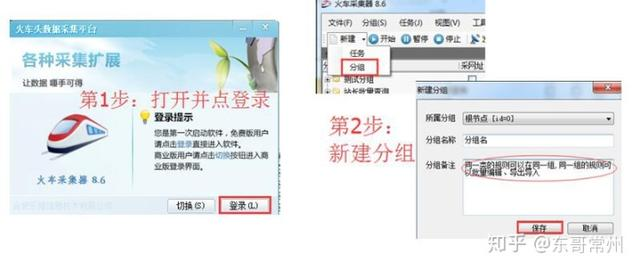
第1步:打开—登录
第2步:新建分组
第3步:右击分组,新建任务,填写任务名;
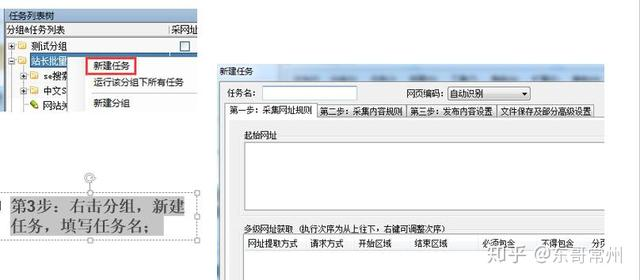
第4步:写采集网址规则(起始网址和多级网址获取)
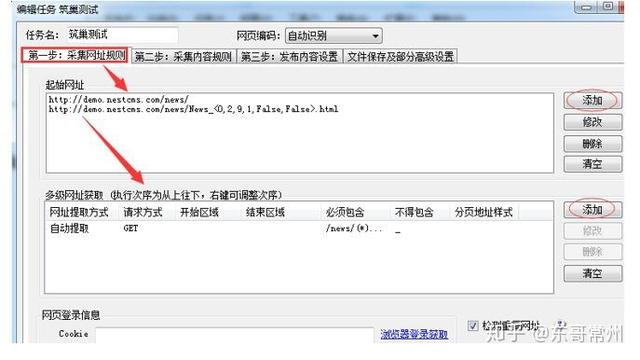
第5步:写采集内容规则(如标题、内容)
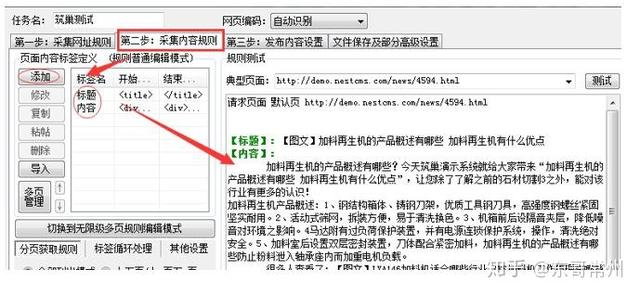
第6步:发布内容设置勾选启用方式二(1)保存格式:一条记录保存为一个txt;(2)保存位置自定义;(3)文件模板不用动;(4)文件名格式:点右边的倒立笔型选[标签:标题];(5)文件编码可以先选utf-8,如果测试时数据正常,但保存下来的数据有乱码则选gb2312;
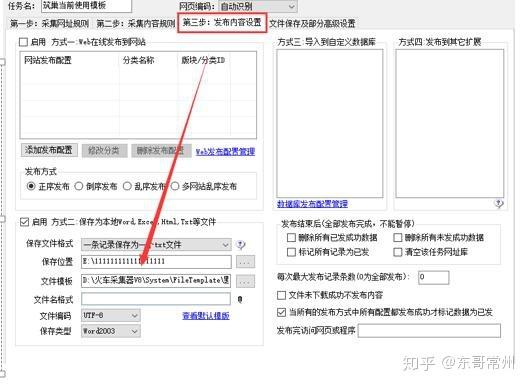
第7步:采集设置,都选100; a.单任务采集内容线程个数:同时可以采集几个网址; b.采集内容间隔时间毫秒数:两个任务的间隔时间; c.单任务发布内容线程个数:一次保存多少条数据; d.发布内容间隔时间毫秒数:两次保存数据的时间间隔;

附注:如果网站有防屏蔽采集机制(如数据很多但只能采集一部分下来,或提示多久才能打开一次页面),则适当调小a值和调大b的值;
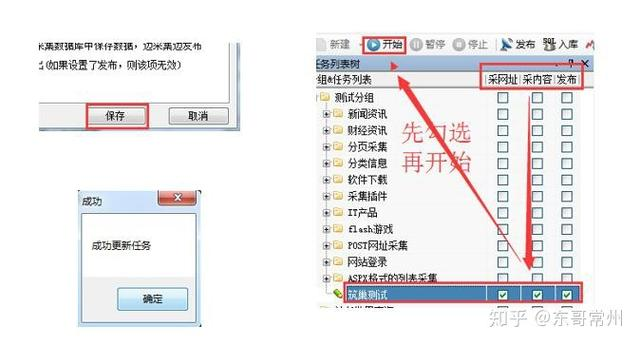
第8步:保存、勾选并开始任务(如果是同一分组的,可以在分组上批量选中)
Google Sheet
使用Google Sheet爬取数据前,要保证三点:使用Chrome浏览器、拥有Google账号、电脑已翻墙。
步骤如下:
(1)打开Google Sheet网站:
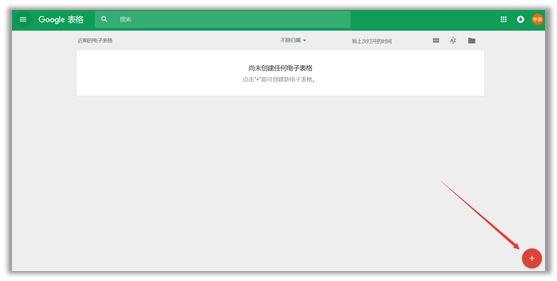
(2)在首页上点击“转到Google表格”,然后登录自己的账号,可以看到如下界面,再点击“+”创建新的表格
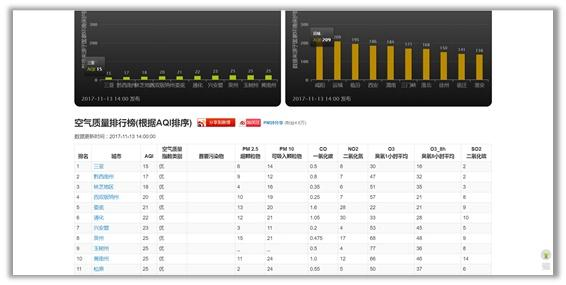
(3)打开要爬取的目标网站,一个全国实时空气质量网站http://www.pm25.in/rank,目标网站上的表格结构如下图所示
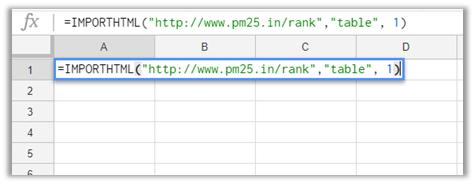
(4)回到Google sheet页面,使用函数=IMPORTHTML(网址, 查询, 索引),“网址”就是要爬取数据的目标网站,“查询”中输入“list”或“table”,这个取决于数据的具体结构类型,“索引”填阿拉伯数字,从1开始,对应着网站中定义的哪一份表格或列表
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入函数=IMPORTHTML("http://www.pm25.in/rank","table",1),回车后就爬得数据啦
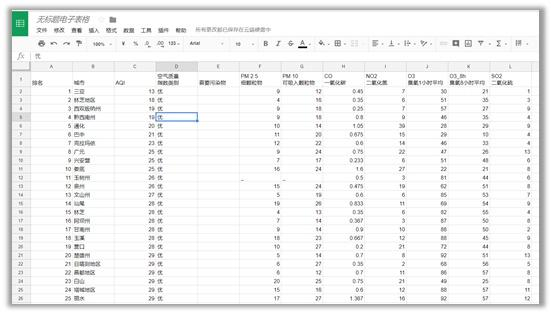
(5)将爬取好的表格存到本地
八爪鱼采集器
八爪鱼采集器是用过最简单易用的采集器,很适合新手使用。采集原理类似火车头采集器,用户设定抓取规则,软件执行。八爪鱼的优点是提供了常见抓取网站的模板,如果不会写规则, 就直接用套用模板就好了。
它是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的现象。不过整体来说还是不错的,毕竟能基本满足新手在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
操作步骤:
(1)登陆后找到主页面,选择主页左边的简易采集,如图:
(2)选择简易采集中淘宝图标,如图红框:

(3)进入到淘宝版块后可以进行具体规则模板的选择,根据楼主截图,应该手提包列表的数据信息采集,此时我们选择“淘宝网-商品列表页采集”,如图:
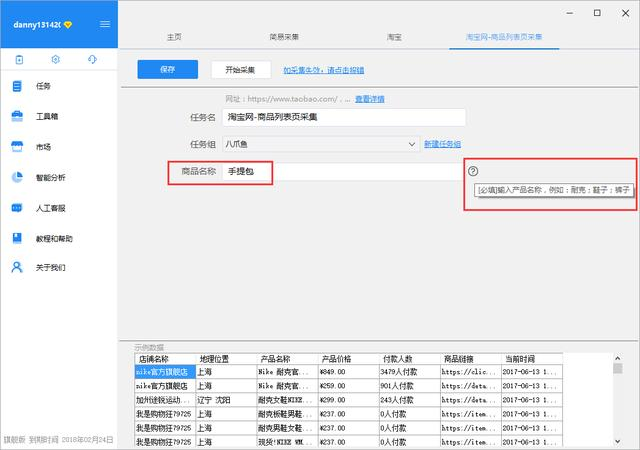
(4)然后会进入到信息设置页面,根据个人需要设置相关关键词,例如此处我们输入的商品名称为“手提包”,如图:
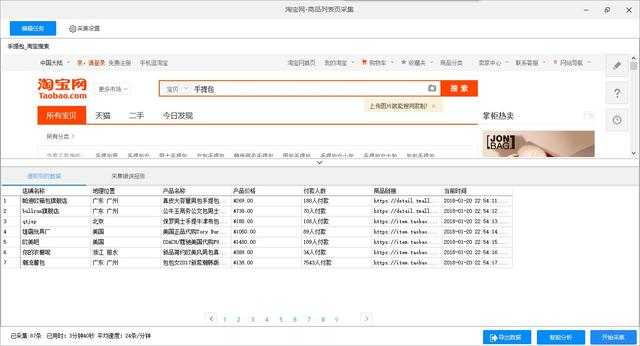
(5)点击保存并启动后就可以进行数据采集了,以下是本地采集效果示例,如图:
GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上悬浮显示的数据。集搜客是以浏览器插件形式抓取数据。虽然具有前面所述的优点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
这个操作原理和八爪鱼也差不多,详细的步骤可以看一下官方的文档,我就不展示了
WebScraper
WebScraper 是一款优秀国外的浏览器插件。同样也是一款适合新手抓取数据的可视化工具。我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
安装和使用步骤:
Web scraper是google浏览器的拓展插件,它的安装和其他插件的安装是一样的。
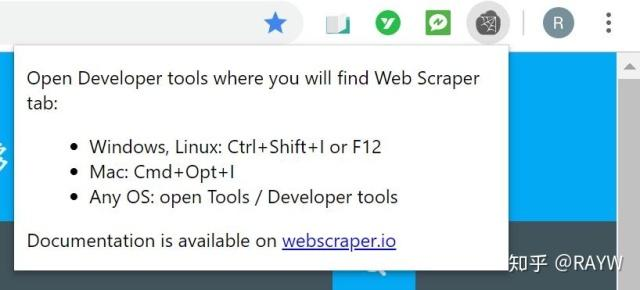
(1)启动插件,根据提示使用快捷键打开插件。实际是在开发者工具中添加了一个tab(开发者工具的位置必须设置在底部才会显示)
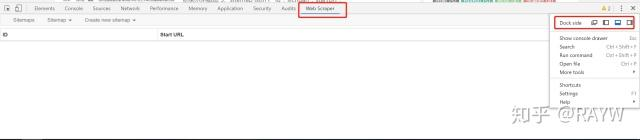
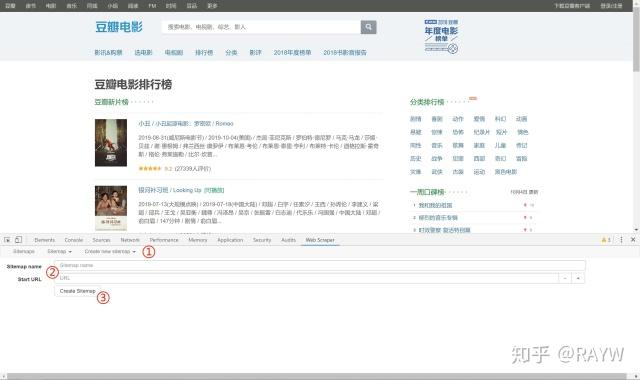
(2) 创建爬取任务
- 点击Create New Sitemap——Create Sitemap
- 输入Sitemap name:爬取任务名称
- 输入start url:爬取的初始页面
- 点击create sitemap完成创建
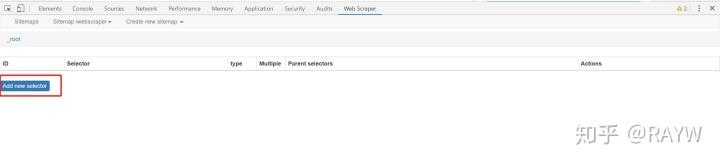
(3) 创建选择器
创建sitemap后进入选择器创建界面,点击Add Selector
Selector:选择器,一个选择器对应网页上的一部分区域,也就是包含我们要收集的数据的部分
一个 sitemap 下可以有多个 selector,每个 selector 有可以包含子 selector ,一个 selector 可以只对应一个标题,也可以对应一整个区域,此区域可能包含标题、副标题、作者信息、内容等等信息。
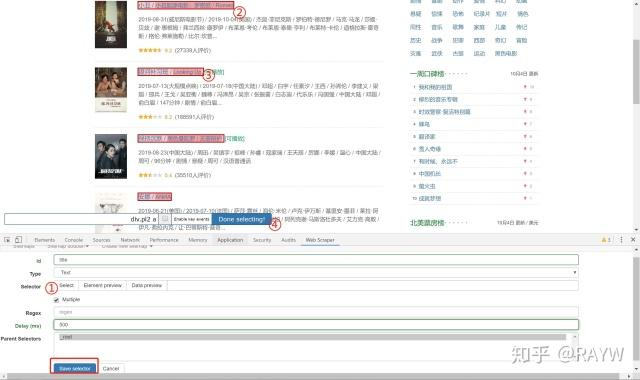
selector设置,参数设置完成后点击save selector
-
- id为selector名称,自行设定(小写英文)
- 爬取排行榜中的电影名称,因此type选text
- selector:点击select,依次点击前两部电影的标题,可以看到后续全部标题已被自动选中,点击Done Selecting结束选择
- 采集多条数据时勾选multiple
- Regex为正交表达式设置,用于对选取文本的过滤,此处不设置
- Delay (ms)为每次爬取之间的延迟时间
(4)爬取数据
点击sitemap douban——Scrape

分别设置请求延时(避免过于频繁被封)与页面载入延时(避免网页载入不全)后点击Start Scraping,弹出新页面开始爬取

爬取结束后弹窗自动关闭,点击refresh按钮,即可看到爬取的数据,然后点击sitemap douban——Export Data to CSV导出数据

Scrapinghub
如果你想抓取国外的网站数据,可以考虑 Scrapinghub。它是一个基于Python 的 Scrapy 框架的云爬虫平台,安装和部署挺简单的,但是操作界面是纯英文的,不太友好,而且性价比不高,它提供的每个工具都是单独收费的。
具体步骤我就不展示了


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











