







进程创建
fork()函数初识
前面进程状态一文,我们讲解了用fork()创建一个进程
这里我们主要了解:
-
进程创建过程中操作系统具体做了什么
-
具体谈谈在这过程发生的写时拷贝技术
进程调用fork,当控制转移到内核中的fork代码后,内核做:
-
分配新的内存块和内核数据结构(我们知道的task_struct、mm_struct)
-
将父进程的部分数据结构内容拷贝至子进程
如:task_struct、地址空间的区域划分(mm_struct)
并完全拷贝,一定会有子进程自己特有的数据:PID、PPID、调度的时间片……
-
将子进车添加到系统进程列表中
-
fork返回,开始调度器调度
我们回顾一下之前的内容:
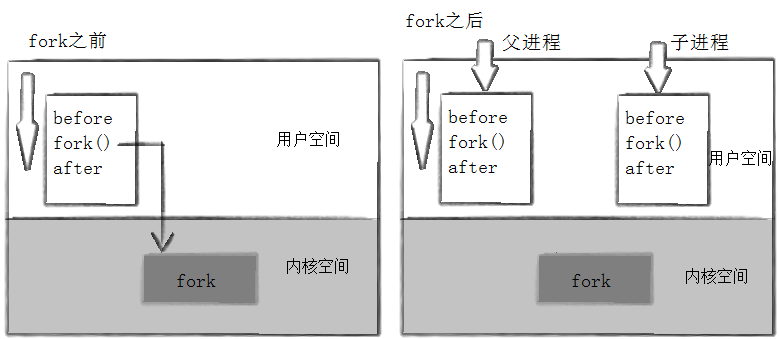
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程,看如下程序
int main(void)
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
pid = fork();//创建子进程,下面两个进程都开始执行
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}
运行结果:
[root@localhost linux]# ./a.out
Before: pid is 43676
After:pid is 43676, fork return 43677
After:pid is 43677, fork return 0
这里看到了三行输出,一行before,两行after。
进程43676先打印before消息,然后它有打印after。
另一个after消息是由43677打印的。注意到进程43677没有打印before,为什么呢?如下图所示

那么fork之后,是否只有fork之后的代码是被父子进程共享的呢?
我们知道,代码具有独立性:代码独立、数据独立
其中数据的独立由写时拷贝支持,那代码呢?
我们知道,程序的代码是只读的,没有被修改的可能性,就可以让父子进程代码共享
所以fork之后,代码共享,一般情况下,父子共享所有的代码!!
子进程执行后续代码 != 只共享后面的代码;只不过子进程只能从这里开始。
那如何让子进程只执行后续代码呢?

上图内存中是进程的一条一条的指令;
我们的CPU中有一个寄存器叫
eip(也叫cp指针),它保存着一个指针,指向当前执行指令的下一条指令在进程控制块
task_struct中对应也有一个变量,存着这个值,当父进程fork形成了子进程,那子进程
进程控制块的这个变量也就跟父进程一致;当子进程被加载到CPU中,它的
eip也就一定是和父进程一致,也就是理所当然从fork开始执行当然我们也可以改这个子进程的eip,让它从代码的第一行开始执行
总结:
fork之后,操作系统做了什么呢?
进程 = 内核的进程数据结构 + 进程的代码和数据
创建子进程的内核数据结构(struct task_struct + struct mm_struct + 页表) + 代码继承父进程、数据写时拷贝的方式来共享或独立。
写时拷贝
概念
通常,父子代码共享,父子在不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。
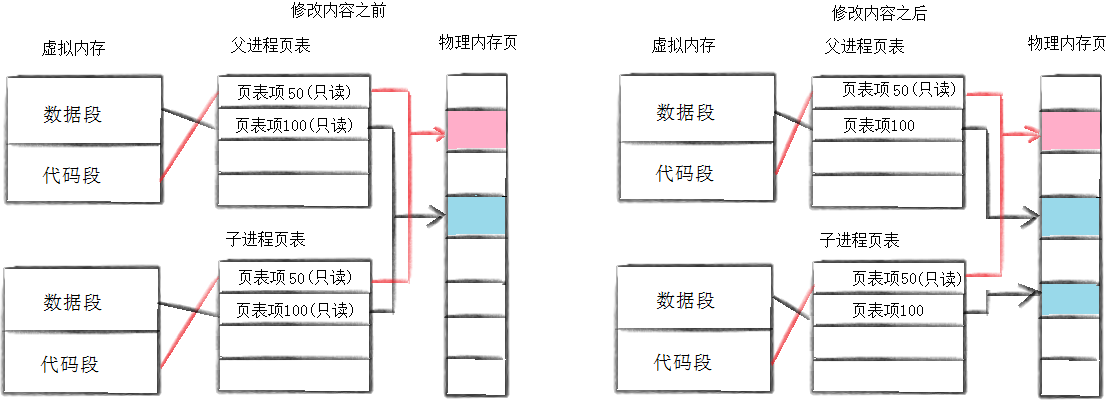
我们的页表中,除了有映射关系,还会包含读写属性
在子进程创建过程,操作系统会把父子进程的页表都设为只读
当某一个进程尝试向数据区写入的时候,操作系统就会把数据区拷贝一份,通过页表建立新的映射关系,并把父子的只读属性去掉。
这个写时拷贝是操作系统的内存管理模块完成的,当它收到如上的写入信号,会自动完成写时拷贝的
原因
那为什么要写时拷贝呢?
创建子进程的时候,就把数据分开不行吗?
答案是可以,但是:
- 父进程的数据,子进程不一定全用,即使使用,也不一定写入 ——— 无脑拷贝会有浪费空间和时间的嫌疑
- 最理想的情况:只有会被父子修改的数据才进行分离拷贝,不需要修改的共享的即可 ——— 从技术的角度,几乎不可能实现(因为,在运行之前,操作系统也不知道某些数据会不会发生写入)
所以我们采用写时拷贝,
那拷贝的成本依旧在啊,为什么不在创建进程的开始,知道进程有写入,就直接完成拷贝呢?
- 写时拷贝本质是一种延时拷贝:你想要,但是立刻使用,我就先不给你,只有你真正要用的时候才给你;那么也就意味着可以先给别人———变相提高了内存的使用效率。
fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数
fork调用失败的原因
-
系统中有太多的进程
——放不下了
-
实际用户的进程数超过了限制
linux有限制
我们写一段循环创建子进程的代码:
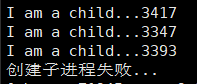
#include <stdio.h> #include<unistd.h> #include<stdlib.h> int main() { while(1) { pid_t id = fork(); if(id<0) { printf("创建子进程失败...\n"); break; } if(id == 0) { printf("I am a child...%d\n",getpid()); sleep(2); exit(0); } } return 0; }可以看到,在创建了N多子进程后,创建子进程失败
终止进程
进程退出码
我们写C/C++代码的时候,main函数作为入口函数,最后总要莫名奇妙写一句return 0;
- return 0;给谁return的呢?
- 为何是0?可以是其它值吗?
常见的进程退出:
- 代码跑完,结果正确
- 代码跑完,结果不正确
- 代码没跑完,程序异常了(比如:访问野指针报错了,这个部分后面讲)
其中main函数返回0,就表示第一种:跑完且正确
非0:失败
既然失败了,我们最想知道的是失败的原因,所以非零就标识不同的原因
我们把main函数return的值称为进程退出码,用来表征进程退出的信息,让父进程读取。
我们写段代码:
test.c
int main()
{
return 123;
}
我们知道,命令行上的所有进程都是bash的子进程,那么我们写的这个程序的退出码,就返回给了bash,echo作为bash中的一个函数,可以显示其中的变量,于是,我们便可以通过如下的方法,打印返回值。
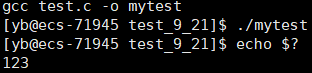
其中,&?是最近一次的执行完进程的退出码
我们执行一下ls程序,显示一个不存在文件

可以看到,人家系统程序如果未完成任务,就会返回一个特定的退出码
一般而言,失败的非零值我们该如何设置呢?默认的返回值有什么含义呢?
我们的C语言提供了一个函数strerror(),返回错误码对应错误的字符串。
#include <stdio.h>
#include<string.h>
int main()
{
int i = 0;
for(;i<100;i++)
{
printf("[%d]: %s\n",i,strerror(i));
}
return 0;
}
部分结果:
[0]: Success
[1]: Operation not permitted
[2]: No such file or directory
[3]: No such process
[4]: Interrupted system call
[5]: Input/output error
[6]: No such device or address
[7]: Argument list too long
[8]: Exec format error
[9]: Bad file descriptor
[10]: No child processes
[11]: Resource temporarily unavailable
[12]: Cannot allocate memory
[13]: Permission denied
[14]: Bad address
[15]: Block device required
[16]: Device or resource busy
[17]: File exists
[18]: Invalid cross-device link
[19]: No such device
[20]: Not a directory
这个错误码是C语言给我们打的,我们也可以不遵守,有一套自己的规则即可
建议返回值在255以内
进程常见退出方法
-
在main函数中return;(只能是main函数)
-
在自己的代码的任意地点,调用exit();

这个status就是退出码
写一段代码:
#include <stdio.h>
#include<stdlib.h>
void func()
{
printf("hello func()\n");
exit(111);
}
int main()
{
func();
return 10;
}

可以看到,执行可func()函数,直接就exit(111);退出了,没有执行main的return语句
还有一个与exit()相似的系统调用函数 —— _exit()
其实exit()的底层调用就是_exit(),只不过exit()多做了点事:刷新缓存区
执行下面的代码:
#include<unistd.h>
int main()
{
printf("hello exit");
_exit(0);
return 10;
}
由于printf没有\n所以不会自动刷新缓存区,如果直接_exit,就会直接退出,屏幕就不会输出

但如果换成exit就会刷新缓存区后再退出

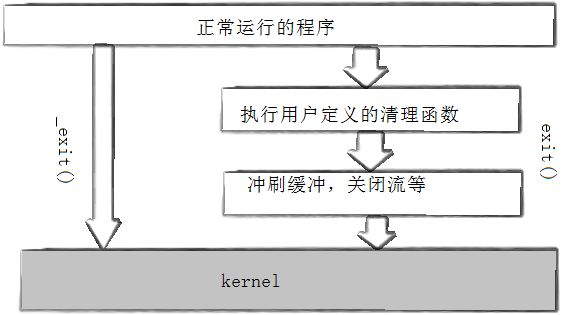
关于终止,内核做了什么
当一个进程结束了,首先会进入Z状态,僵尸状态,等待父进程回收,父进程得到结果就会把它置为X状态,
进程 = 内核结构 + 进程代码 和 数据
操作系统就会把X状态的这个进程的所有数据释放掉
实际上,对于内核结构(task_struct && mm_struct……),操作系统可能并不会释放该进程的数据结构
这都是一个一个的对象,如果要重新加载进程,就要重新创建对象,就要重新开辟空间,重新初始化,这些都要消耗时间
所以操作系统就会把这些本来要释放的数据结构维护起来
下次再调用的时候,只需要初始化一下就行,不需要再开辟空间了
这个东西就是内核的数据结构缓冲池,slab分派器
进程等待
为什么要进行等待
-
之前讲过,子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。
-
另外,进程一旦变成僵尸状态,那就刀枪不入,“杀人不眨眼”的kill -9 也无能为力,因为谁也没有办法
杀死一个已经死去的进程。 -
最后,父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对,
或者是否正常退出。
总之:父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
如何等待
wait方法
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
返回值:
成功返回被等待进程pid,失败返回-1。
参数:
输出型参数,获取子进程退出状态,不关心则可以设置成为NULL
#include <stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id==0)
{
//child
while(1)
{
printf("我是子进程,我正在运行...PID: %d\n",getpid());
sleep(1);
}
}
else
{
//fater
printf("我是父进程,我正在运行...PID: %d\n",getpid());
sleep(20);
pid_t ret = wait(NULL);
if(ret < 0)
{
printf("等待失败\n");
}
else
{
printf("等待成功,result:%d\n",ret);
}
sleep(20);
}
}
如上代码逻辑为:
-
创建子进程后,子进程执行死循环
-
父进程在20秒后等待子进程
-
我们在20秒之内通过另一终端,用kill -9 和子进程的PID杀掉子进程,此时子进程就会进入僵尸状态
-
20秒时,父进程就会对子进程等待,把子进程的Z状态改为X状态,子进程就可以被系统回收
-
再开一台终端,通过这个检测脚本,
while :; do ps axj | head -1 && ps axj | grep myte------"; sleep 1; done
每隔1秒,打印一下父子进程的进程信息
就会看到:
- 前20秒,父子进程都是S+状态
- 我们手动kill子进程后,子进程状态变为Z状态
- 20秒后,子进程消失(子进程变为X状态后,没来得及我们检测,就被系统回收了)

既然叫等待,也就是说,如果我们20秒内没有将子进程杀掉20秒时子进程还在运行,那父进程就会一直停留在wait函数这里,直到子进程结束
上面的测试之所以提前杀掉子进程,就是想看它先进入Z状态,wait再进行回收了
如果我们过20秒后再杀子进程,看到的就是子进程直接消失,无法看到实际的先到Z再到X释放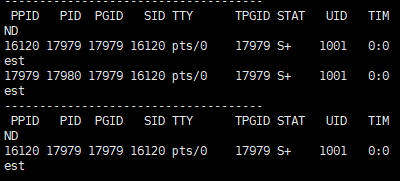
waitpid方法
前面我们使用的wait()可以认为是一个精简版的进程等待方法,它是等待退出的第一个进程,如果只有一个子进程,问题不大,如果有多个子进程,它仅会回收第一个进入僵尸态的子进程
接下来我们讲讲豪华版——waitpid()
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候waitpid返回收集到的子进程的进程ID;
如果设置了第三个参数选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数:
pid:
Pid=-1,等待任一个子进程。与wait等效。
Pid>0.等待其进程ID与pid相等的子进程。
status:
通过一个输出型int*参数获得退出信息
options:
0:阻塞等待
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该进程的ID。
status
作用
这是一个int*的指针,一般函数参数的指针有两种:数组、返回型参数,而在这里显然不是数组,那就是一个返回型参数,
也就是想从函数中带出一些特定的数据,
然而waitpid()是系统调用,也就是status会从操作系统中带出来一个int值
这个值表示什么信息呢?
我们的内核中有进程控制块,指向着相应的进程代码,当一个进程执行了return或exit,结束后进入Z状态,会将自己的退出信息写入到进程控制块中;此时代码可以释放,但进程控制块一定要维护。

也就是填充到如下部分

我们父进程调用waitpid(),这个系统调用就会在操作系统内部找到子进程的task_struct,提取出它的退出码

内容
status指向一个四字节整型(32位),其实这个整型是被当一个位结构使用的
而我们这里只关心它的低16个比特位
这低16位被分为三部分:
- 0-6:终止信号/退出信号
- 7:core dump标志
- 8-15:退出码/退出状态
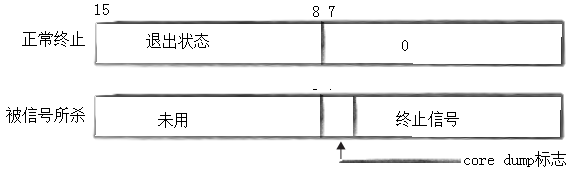
退出码
status的次低八位
我们写段代码验证一下:
#include <stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
//child
int cnt = 5;
while (cnt)
{
printf("我是子进程,我正在运行...PID: %d\n", getpid());
sleep(1);
cnt--;
}
exit(13);
}
else
{
int status = 0;
printf("我是父进程,我正在运行...PID: %d\n", getpid());
// sleep(20);
pid_t res = waitpid(id, &status, 0);
if (res > 0)
{
printf("等待成功,res:%d,\
我所等待的子进程的退出码:%d\n", res, (status >> 8) & 0xff);
}
else if (res < 0)
{
printf("等待失败\n");
}
}
}
我们让子进程运行5秒后退出,退出码是13;同时父进程一直阻塞等待,直到5秒后,
- res接收子进程的pid,
- status接收子进程的推出信息,通过如下方式
(status >> 8) & 0xff取出次低8位——子进程的退出码

这里问个小问题:
waitpid设计的时候,可以把这个status设为一个全局变量,父进程直接通过这个全局变量获取子进程退出信息吗?
答案是不可以,由于进程是独立的,父子进程的数据区是分离的,只要子进程有过数据更改,他们的全局变量就绝对不会对应同一块物理地址空间,所以必须跨过操作系统。
退出信号

status的低7位是退出信号,中间的core dump我们先不讲
#include <stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
//child
while (1)
{
printf("我是子进程,我正在运行...PID: %d\n", getpid());
sleep(1);
}
}
else
{
int status = 0;
printf("我是父进程,我正在运行...PID: %d\n", getpid());
// sleep(20);
pid_t res = waitpid(id, &status, 0);
if (res > 0)
{
printf("等待成功,res:%d,我所等待的子进程的退出码:%d,退出信号:%d\n", res, (status >> 8) & 0xff, status & 0x7f);
}
else if (res < 0)
{
printf("等待失败\n");
}
}
}
这回我们让子进程死循环,父进程阻塞等待子进程,当我们用另一台终端kill -9杀掉子进程的时候,父进程将接收子进程的返回信息,通过status & 0x7f可以获得低七位

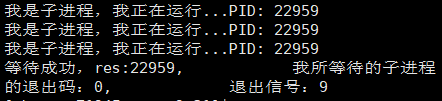
可以看到,退出信号就是9
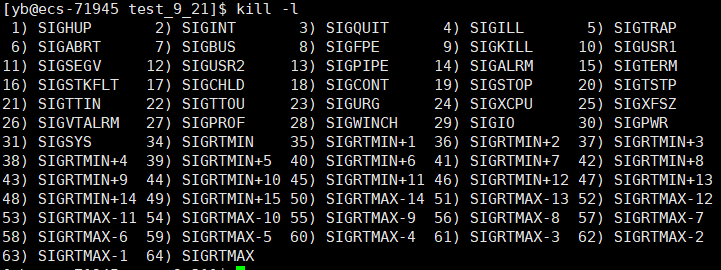
我们也可以使用其他信号试试


或者我们手动写一段会报错的代码
if(id==0) { //child printf("我是子进程,我正在运行...PID: %d\n",getpid()); sleep(2); int a = 5/0; }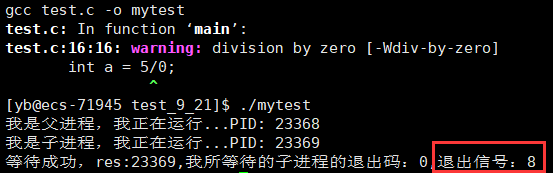
其中8号信号是
浮点错误
这里我们像一个小问题:
操作系统怎么直到我们出错了?
目前我们所见的异常都体现在系统或硬件上
比如说除0,CPU在计算的时候内部有寄存器保存除数、被除数、得数,还有一个寄存器称为状态寄存器,这个状态寄存器有某些比特位用来标志当前计算是否有溢出,一旦溢出CPU就会将其设为1;
然而这个硬件一定是要被操作系统管理的,这些错误表现在硬件上,进而被操作系统得知,既然硬件出了问题,操作系统就一定会找到产生问题的进程,找到它的PCB,填写退出信号,把它的状态从R改为Z ,从运行队列拿下去,在用户看来就是进程崩溃了。
我们用户自己通过kill -9等信号,就是直接进行后面的填写退出信号,把它的状态从R改为Z ,从运行队列拿下去等等任务,与上面的结果是一致的。
退出码/退出信号总结:
于是,这里的退出码和退出信号就和前面进程退出码对应起来了:

通过退出信号,可以判断是1、2还是3,一旦出现异常,我们只关心退出信号,判断异常的原因
如果没有再通过退出码,可以判断是1./2..
1.就是成功2.再通过约定退出码含义做出相应的措施
上面我们是通过位运算的方式获得相应退出码和退出信号的,
实际C语言给我们提供了两个宏,获得status中的退出码和退出信息
- WIFEXITED(status):退出信号
- WEXITSTATUS(status):退出码
就可以把我们上面的:
-
获得退出信号:
status & 0x7f换成是WIFEXITED(status) -
获得推码:
(status >> 8) & 0xff换成是WEXITSTATUS(status)
options

我们知道等待分为,阻塞等待和非阻塞等待
那如何理解父进程阻塞呢?
父进程的task_struct中的状态由R–>S,从运行队列投入到等待队列,等待子进程退出
子进程退出就相当与条件就绪,当就绪后,父进程就会将面的步骤反着执行一遍
阻塞等待&&非阻塞
0 —— 阻塞等待:
父进程通过系统调用接口waitpid(),让操作系统拿到子进程的推出信息,并把Z转成X让子进程释放,
但操作系统说,你得等等,子进程还没退出
于是父进程说,你把我的状态改了,我就在waitpid这行代码先等着;
等子进程好了,你再把我唤醒,把相应信息给我,我再干其他的事
WNOHANG —— 非阻塞:
还是父进程调用waitpid(),让操作系统拿到子进程的推出信息
操作系统一看,子进程没好,告诉父进程
这父进程直接从waitpid返回,做自己的事
过了一会,再调用waitpid()问一下操作系统,这回子进程完事了,于是父进程就拿到信息了。
这种多次调用非阻塞接口的方式我们称为轮询检测!
这里HANG是阻塞,WNOHANG(wait no hang)就是等待的时候不阻塞
我们写一段代码实现一下非阻塞等待:
#include <stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
//child
printf("我是子进程,我正在运行...PID: %d\n", getpid());
sleep(5);
return 123;
}
else
{
int status = 0;
printf("我是父进程,我正在运行...PID: %d\n", getpid());
// sleep(20);
while (1)
{
pid_t res = waitpid(id, &status, WNOHANG);
if (res > 0)
{
printf("等待成功,res:%d,我所等待的子进程的退出码:%d,退出信号:%d\n", res, (status >> 8) & 0xff, status & 0x7f);
return 0;
}
else if (res == 0)
{
//等待成功,但子进程没有退出
printf("子进程好了没?没好,那我父进程先做其他事\n");
sleep(1);
}
else
{
//出错了,暂时不处理
}
}
}
}
逻辑:
子进程执行5秒后退出,父进程进行非阻塞等待,通过while循环轮询检测
当waitpid返回值>0(子进程pid),等待成功,结束进程
当waitpid返回值==0,子进程没有退出,父进程先做其他的是,一秒后继续询问
以此逻辑一直循环轮询检测,知道子进程退出
其中,这一块可以换成相应的任务

我们通过如下方法,定义一个任务集——
handlerstypedef void (*handler_t)(); std::vector<handler_t> handlers; void fun1() { cout << "我是任务一" << endl; } void fun2() { cout << "我是任务二" << endl; } void Load() { //加载任务 handlers.push_back(fun1); handlers.push_back(fun2); }执行任务就是

小贴士:
void (*handler_t)()的handler_t是一个函数指针
typedef void (*handler_t)()的handler_t就是一个类型,该类型的实例是一个函数指针
vector<handler_t> handlers的handlers就是一个函数指针类型的vector,可以接收下面如fun1,fun2这样的函数下面调用时就是,调用Load函数把任务加载进来,然后访问vector中的每一个元素进行函数回调
但一般C++不喜欢用函数指针,可以用仿函数代替
进程的程序替换
概念
我们之前fork()创建的子进程,执行的是父进程的代码片段
如果我们今天想让子进程执行一个全新的程序呢?
——进程的程序替换
为什么要替换
我们一般在服务器设计(Linux编程)的时候,往往需要让子进程干两种事情
- 让子进程执行父进程的代码(服务器代码)
- 让子进程执行执行磁盘中的一个全新的程序(shell;让客户端执行相应的程序;通过我们的进程,执行其他人写的进程代码:c/c+±->c/c++/Python/Shell/Java,完成某些任务)
原理
如果直接fork创建子进程
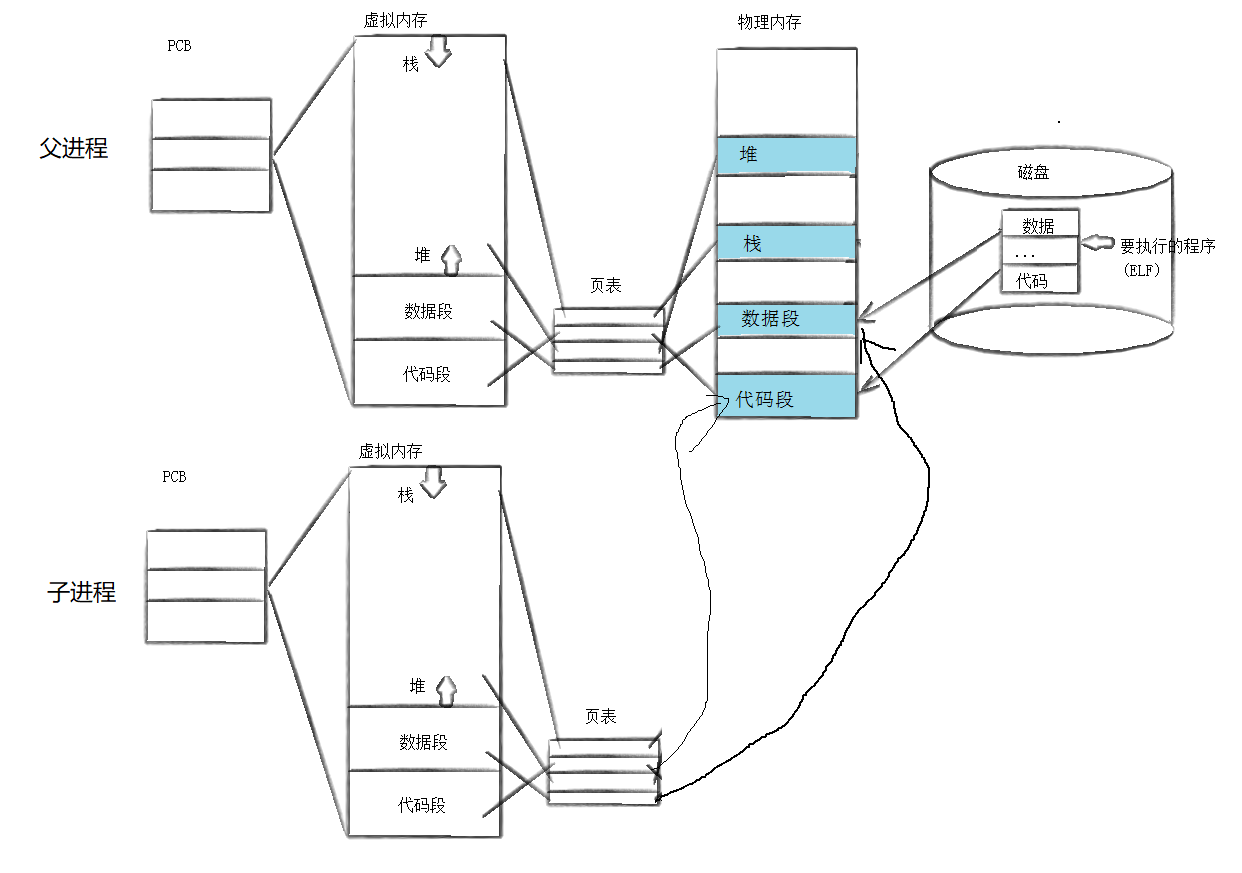
子进程会和父进程共享代码数据
如果我们要进行程序替换
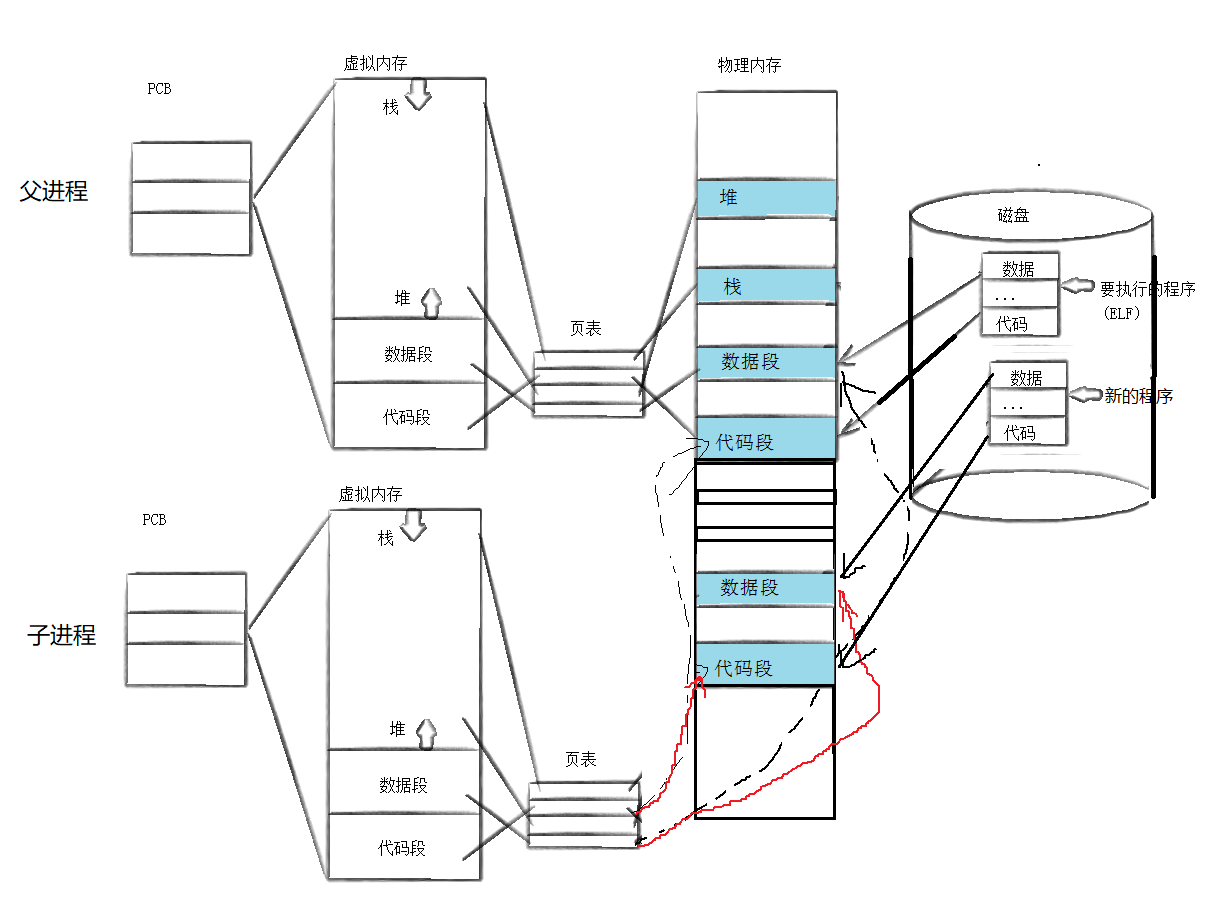
操作系统就会把新程序的代码和数据加载到内存中来,然后重新调整子进程的页表映射
程序替换的原理:
- 将磁盘中的程序加载到内存结构
- 重新建立页表映射,谁执行的程序替换,就重新建立谁的映射(子进程)
效果:让子进程和父进程彻底分离,并让子进车执行一个全新的程序
注意:这个替换的过程没有创建新的进程,这个过程子进程的内核数据结构基本没变,只是重新建立了一下页表映射,PID还是原来的PID。
这些加载到内存、建立映射等操作一定是由操作系统帮我们完成的,那么我们就要调用系统调用接口,让操作系统完成
如何进行程序替换
见见猪跑——最基本的代码
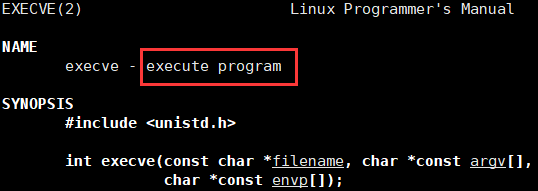
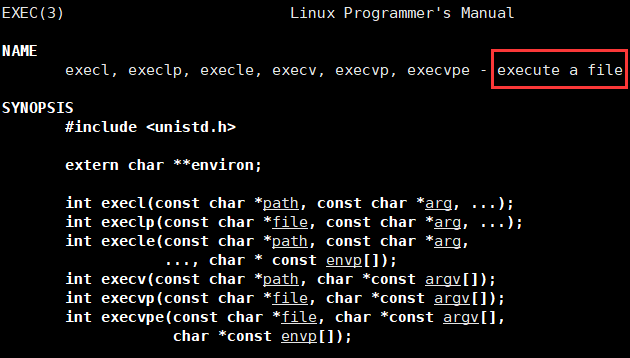
以上一共八个程序替换的系统调用,我们先看看这一个:

我们如果要执行一个全新的程序,需要做几件事呢?
-
先找到这个程序在哪里
-
程序可能携带选项进行执行(也可以不携带)–>明确告诉操作系统,我想怎么执行这个程序
-
上面的
path就是一个放着程序位置的字符串,告诉操作系统去哪找 -
后面的
...是一个可变参数列表(可以传入任意个参数),加上前面的arg参数,就可以按照我们命令行写的方式 ,把选项一个一个传进去,亦或只传程序名,不传选项;但是最有一个参数必须是NULL,标识参数传递完毕
,把选项一个一个传进去,亦或只传程序名,不传选项;但是最有一个参数必须是NULL,标识参数传递完毕
execl("/usr/bin/ls","ls","-a","-l",NULL);
看完猪照片,我们见见猪跑
myexec.c
#include<stdio.h>
#include<unistd.h>
int main()
{
//ls -a-l
printf("我是一个进程,我的PID是:%d\n",getpid());
execl("/usr/bin/ls","ls","-a","-l",NULL);
printf("我执行完毕了,我的PID是:%d\n",getpid());
return 0;
}


可以看到,execl确实让我们执行了ls程序,但是可以发现少打印了一句“我执行完毕了”
也很好理解,一旦替换成功,当前的进程代码和数据就被全部替换,包括后面的printf代码。
那么,这个程序替换函数用不用判断返回值呢??
int ret = execl(. . .);
这个ret是当前程序内的变量,一旦替换成功,还会执行返回语句吗?
肯定不会
那这个返回值还有没有用?答案是有用
不用判断返回值,因为只要成功就不会有返回值;而失败的时候,必然会继续向后执行!!我们最多可以通过返回值获得导致失败的原因。
#include<stdio.h>
#include<unistd.h>
int main()
{
//ls -a-l
printf("我是一个进程,我的PID是:%d\n",getpid());
int ret = execl("/usr/bin/lssss","ls","-a","-l",NULL);
printf("我执行完毕了,我的PID是:%d,ret:%d\n",getpid(),ret);
return 0;
}
我们故意用一个不存在的文件路径

引入进程创建
为了不影响父进程,我们fork一个子进程,把子进程替换成一个全新的程序
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
int main()
{
printf("我是父进程,我的PID是:%d\n",getpid());
id_t id = fork();
if(id==0)
{
//子进程
printf("我是子进程,我的PID是:%d\n",getpid());
int ret = execl("/usr/bin/ls","ls","-a","-l",NULL);
printf("子进程创建替换失败:%d",ret);
}
int status = 0;
sleep(3);
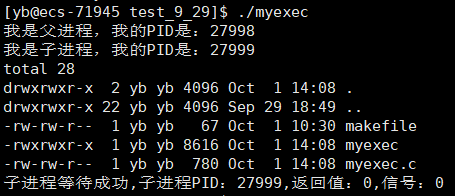
id = waitpid(id,&status,0);
printf("子进程等待成功,子进程PID:%d,返回值:%d,信号:%d\n",id,(status>>8)&0xff,status&0x7f);
return 0;
}
测试不同接口
execv
int execv(const char *path, char *const argv[]);
-
path–>如何找到 -
argv–>如何执行
这个接口与execl唯一的区别就是:把一个一个的参数放到一个字符串数组中一起传过去。
char* const argv_[4] = {
(char*)"ls",
(char*)"-l",
(char*) "-a",
NULL
};
execv(/usr/bin/ls, argv_);
为了更好的区分execl和execv,
- 我们把
l看作是list——>代表可变参数列表 - 把
v看作是vector–>代表一个数组
execlp
int execlp(const char *file, const char *arg, …);
很明显,这个execlp是在execl的基础上做了一些改变
file--> 要执行什么样的程序 -->会像我们平时使用系统命令时直接输入程序名,就默认从PATH路径中找一样,这里也是直接输入程序名就行,会从自动PATH环境变量中找到这个程序的路径- 剩下的与
execl一致
execlp("ls","ls","-a","-l");
注意:这两个ls含义不一样——一个告诉操作系统找谁,另一个是告诉操作系统你想怎么执行
函数名细节:我们可以把这里的p看成是PATH,代表会从PATH中搜索路径
execvp
int execvp(const char *file, char *const argv[]);
有了上面两个案例,这个也很好猜到:
- file–>文件名
- argv–>指令数组
char* const argv_[4] = {
(char*)"ls",
(char*)"-l",
(char*) "-a",
NULL
};
execvp("ls",argv_);
execle
int execle(const char *path, const char *arg, …, char * const envp[]);
这里execle的‘e’表示环境变量
这个环境变量这个参数需由该函数的调用方传入,
被换入的程序就可以使用这个环境变量
所以我们写一个C程序,它运行起来后,产生一个子进程,然后对子进程使用execle进行替换,同时传入一个环境变量;其中被换入的这个程序,我们中C++来写,在其中获得调用execle时传入的环境变量。
mycmd.cpp
#include<iostream>
#include<stdlib.h>
using namespace std;
int main()
{
cout<<"PATH:"<<getenv("PATH")<<endl;
cout<<"MYPATH:"<<getenv("MYPATH")<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
return 0;
}
直接编译运行这个程序

会看到,只打印了第一行的,后面直接没有,因为它没找就直接崩溃退出了
那么我们用一个C程序演示一下,如何用execle给替换的程序传入环境量
myexec.c
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
int main()
{
printf("我是父进程,我的PID是:%d\n",getpid());
id_t id = fork();
if(id==0)
{
//子进程
printf("我是子进程,我的PID是:%d\n",getpid());
char* const env_[] = {
(char*)"MYPATH=YouCanSeeMe!!",
NULL
};
execle("./mycmd","mycmd",NULL,env_);
}
int status = 0;
sleep(3);
id = waitpid(id,&status,0);
printf("父进程等待成功,子进程PID:%d,返回值:%d,信号:%d\n",id,(status>>8)&0xff,status&0x7f);
return 0;
}
我们通过一个.c程序间接调用上面的.C++程序,并传入MYPATH这个环境变量。

但此时,连第一句都无法打印
我们先引掉PATH环境变量的打印
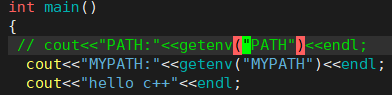
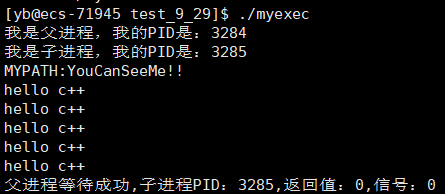
可以正常打印
可以看出,如果调用execle,替换前进程所有的环境变量会直接被全部覆盖掉
如果想继承替换前 进程的环境变量,可以声明环境变量的指针
extern char** environ;
调用的时候传入environ
execle(“./mycmd”,“mycmd”,NULL,environ);
此时,execle的意义也就不大了,相当于execl("./mycmd","mycmd",NULL)
如果想进行追加,可以使用putenv函数

注意:保存环境变量的数组仅保存对应环境变量的字符串的指针,putenv也仅仅是把新建的环境变量的字符串的指针push给了环境变量的数组;所以一定要保证
具体的使用,见下面的export
或者也可手动实现一下:
extern char** environ;
size_t env_size = 0;
while(environ[env_size++]);//记录环境变量的个数,包括NULL
char** const env_ = (char**)malloc(1+env_size*sizeof(char*));
env_[0] = (char*)"MYPATH=YouCanSeeMe!!";
memcpy(env_+1,environ,env_size*sizeof(char*));
execle("./mycmd","mycmd",NULL,env_);
亦或者在命令行的bash进程就创建环境变量,一直传到替换后的进程

execve
int execve(const char *filename, char *const argv[], char *const envp[]);
与execle唯一的区别就是,
v–>数组传参
l–>可变参数列表传参
execvpe
int execvpe(const char *file, char *const argv[], char *const envp[]);
v–>数组传参
p–>直接传程序名,默认在PATH查找
e–>传入环境变量
总结
为什么要这么多接口呢?
适配不同的使用情况
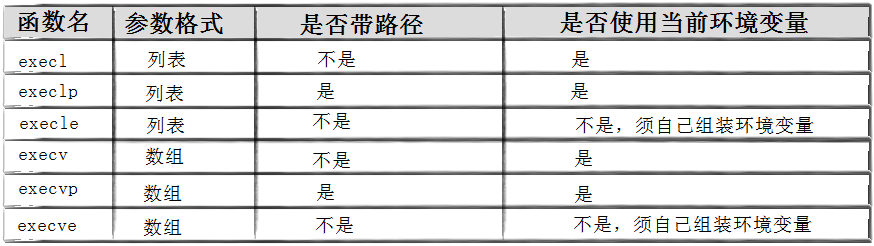
事实上,只有execve是真正的系统调用,其他最终都会调用execve,所以只有execve是在man手册的第2页,其它都是第3页
用C语言代码调用其它语言的程序
C++
我们这里创建两个程序,用c的程序调用c++的程序
makefile
.PHONY:all
all:mycmd myexec
mycmd:mycmd.cpp
g++ -o $@ $^
myexec:myexec.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f myexec mycmd
当前make可以编译生成两个可执行程序
mycmd.cpp
#include<iostream>
using namespace std;
int main()
{
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
cout<<"hello c++"<<endl;
return 0;
}
先看一下当前的路径:

myexec.c
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
int main()
{
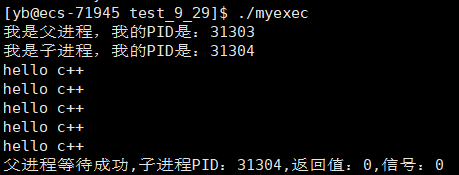
printf("我是父进程,我的PID是:%d\n",getpid());
id_t id = fork();
if(id==0)
{
//子进程
printf("我是子进程,我的PID是:%d\n",getpid());
execl("/home/yb/code/linux-learning/test_9_29/mycmd","mycmd",NULL);
}
//也可使用相对路径:./mycmd
//父进程
int status = 0;
sleep(3);
id = waitpid(id,&status,0);
printf("父进程等待成功,子进程PID:%d,返回值:%d,信号:%d\n",id,(status>>8)&0xff,status&0x7f);
}
python
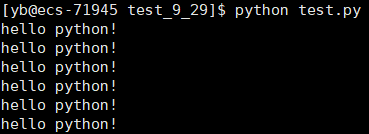
我们在再试一段python代码
#! /bin/python3
print("hello python!")
print("hello python!")
print("hello python!")
print("hello python!")
print("hello python!")
print("hello python!")
像这种解释型语言,就可以直接用一个解释器,把上面的脚本型语言跑起来
看一眼解释器的路径

#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
int main()
{
printf("我是父进程,我的PID是:%d\n",getpid());
id_t id = fork();
if(id==0)
{
//子进程
printf("我是子进程,我的PID是:%d\n",getpid());
execl("/bin/python","python","test.py",NULL);
}
int status = 0;
sleep(3);
id = waitpid(id,&status,0);
printf("父进程等待成功,子进程PID:%d,返回值:%d,信号:%d\n",id,(status>>8)&0xff,status&0x7f);
return 0;
}
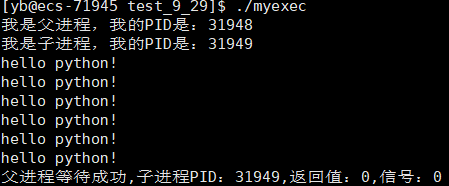
便可通过C语言调用python代码
shell
我们再写一段shell 脚本
test.sh
#!//bin/bash
cnt=0;
while [ $cnt -le 100 ]
do
echo "hello $cnt"
let cnt++
done
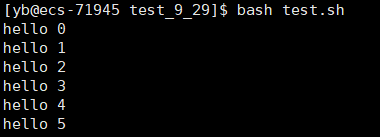
我们再用C语言去调用:
execl("/bin/bash","bash","test.sh",NULL);
照样可以跑起来
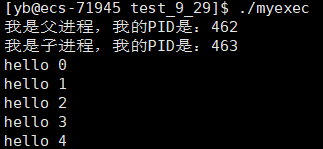
做一个简单的shell
初步实现
通过观察系统的shell,它的操作不就是:
- 打印一个提示行,等待用户输入
- 输入后,执行字符串所显示的程序
- 再次打印提示符,等待输入……
就是一个死循环
所以我们简单实现一下:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
#define SEP " "
#define NUM 1024
#define SIZE 128
char command_line[NUM];//存储外部输入的
char* command_args[SIZE];
int main()
{
//shell实际上就是一个死循环
while(1)
{
//1.显示提示符
printf("[张三@我的主机名 当前目录]# ");
fflush(stdout);
//2.获取用户输入
memset(command_line,'\0',sizeof(command_line)*sizeof(char));
sleep(2);
fgets(command_line,NUM,stdin);//获取C风格的字符串,默认\0结尾
command_line[strlen(command_line)-1] = '\0';//fgets会获取到键盘最后敲得回车-\n字符,要将其置为\0
//3."ls -a -l -i" --> "ls" "-a" "-l" "-i"
//char *strtok(char *str, const char *delim);
//将一个字符串按照特定的分隔符,打散成字串,并将子串依次返回
command_args[0] = strtok(command_line,SEP);
int index = 1;
while(command_args[index++] = strtok(NULL,SEP));//strtok截取成功返回字符串地址,截取失败返回NULL
//for debug
//for(int i = 0;i<index;i++)
//{
// printf("%s\n",command_args[i]);
//}
//4.TODO
//5.创建进程,执行
pid_t id = fork();
if(id == 0)
{
//子进程
//6.程序替换
execvp(command_args[0],command_args);
exit(1);//替换失败,子进程直接退出
}
if(id>0)
{
int status = 0;
waitpid(id,&status,0);
printf("等待成功:sig:%d, code:%d\n",status&0x7f,(status>>8)&0xff);
}
}//end while
}
运行./myshell
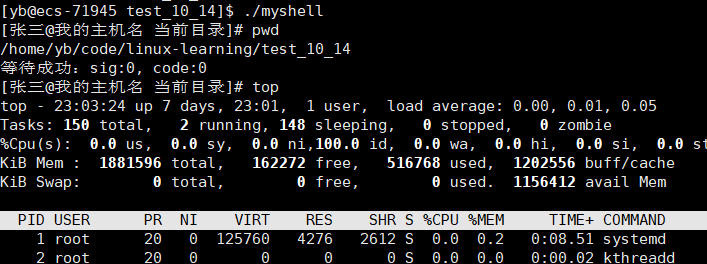
一般命令都可以用,但是使用ls的时候会出现问题
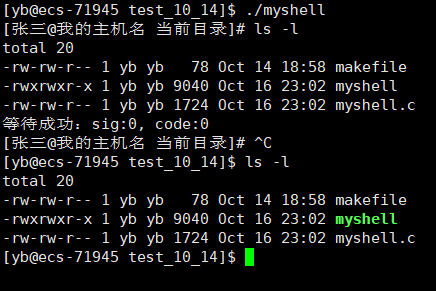
ls配色解决
我们发现,系统shell的ls有配色,但是我们自己的没有
这时因为,系统的ls是一个别名

这里的alias表示起别名,我们输入的ls会在shell中被转换为ls --color=auto,也就是实际使用的是ls --color=auto
我们自己的shell如果添加了颜色配置选项,ls也会对输出进行颜色配置
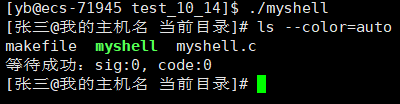
所以,我们在myshell中为ls添加--color=auto选项:
command_args[0] = strtok(command_line,SEP);
int index = 1;
if(strcmp(command_args[0],"ls")==0)//为ls增加颜色
command_args[index++] = (char*)"--color=auto";
while(command_args[index++] = strtok(NULL,SEP));//strtok截取成功返回字符串地址,截取失败返回NULL
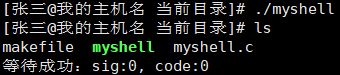
内建命令
ls
除了ls,我们发现cd使用的时候也有问题
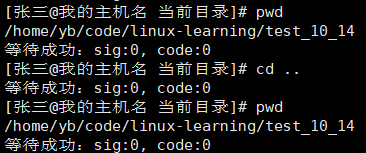
它,并不能完成路径的切换
这是因为,我们在执行ls之前,会先创建一个子进程,这个子进程会程序替换为cd程序,执行路径的切换;此时路径确实切换了,但是切换的是这个子进程的路径;当子进程结束,回到myshell进程,路径还是原来的。
所以我们希望,cd命令并不是通过创建子进程执行,在父进程中完成路径的切换
但是可以直接把父进程替换为cd吗?
答案肯定是不行,因为替换后父进程的执行逻辑将被中断。
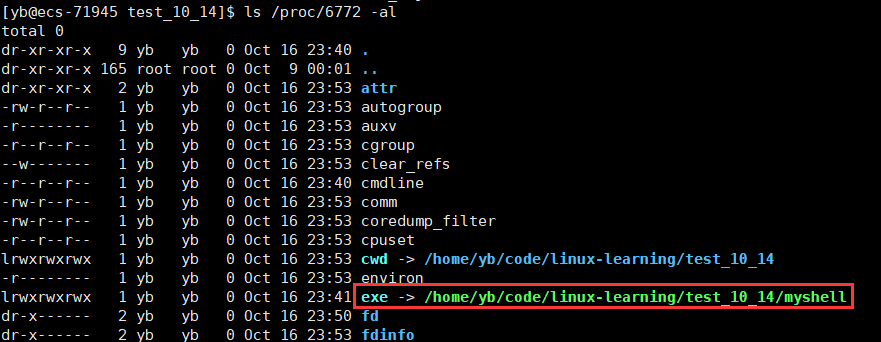
pwd打印的是什么呢?shell进程的当前路径
那这个路径存在哪呢?
在进程概念一篇中,我们知道,进程的当前路径存在进程控制块中;可以在/proc/进程ID路径下看到
既然是改进程控制块中的东西,那就一定是有操作系统完成的,也就是需要使用系统调用
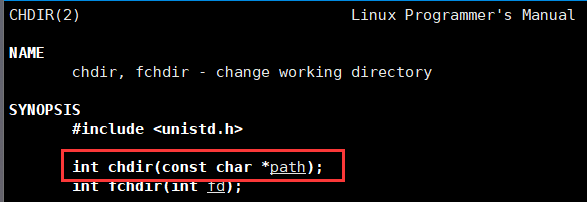
chdir这个系统调用函数可以改变当前进程的当前路径,传入目的路径的字符串(相对路径/绝对路径)
于是便可在父进程通过调用一个实现路径的切换。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
#define SEP " "
#define NUM 1024
#define SIZE 128
char* command_args[SIZE];
char command_line[NUM];
int ChangeDir(const char * new_path)
{
chdir(new_path);
return 0;//更改成功
}
int main()
{
//shell实际上就是一个死循环
while(1)
{
//1.显示提示符
printf("[张三@我的主机名 当前目录]# ");
fflush(stdout);
//2.获取用户输入
memset(command_line,'\0',sizeof(command_line)*sizeof(char));
sleep(2);
fgets(command_line,NUM,stdin);//获取C风格的字符串,默认\0结尾
command_line[strlen(command_line)-1] = '\0';//fgets会获取到键盘最后敲得回车-\n字符,要将其置为\0
//3."ls -a -l -i" --> "ls" "-a" "-l" "-i"
//char *strtok(char *str, const char *delim);
//将一个字符串按照特定的分隔符,打散成字串,并将子串依次返回
command_args[0] = strtok(command_line,SEP);
int index = 1;
if(strcmp(command_args[0],"ls")==0)//为ls增加颜色
command_args[index++] = (char*)"--color=auto";
while(command_args[index++] = strtok(NULL,SEP));//strtok截取成功返回字符串地址,截取失败返回NULL
//4.内建命令
if(strcmp(command_args[0],"cd") == 0&&command_args[1]!=NULL)
{
ChangeDir(command_args[1]); //让当前进程进行路径切换
continue;
}
//5.创建进程,执行
pid_t id = fork();
if(id == 0)
{
//子进程
//6.程序替换
execvp(command_args[0],command_args);
exit(1);//替换失败,子进程直接退出
}
if(id>0)
{
int status = 0;
waitpid(id,&status,0);
printf("等待成功:sig:%d, code:%d\n",status&0x7f,(status>>8)&0xff);
}
}//end while
}
我们把这样的在shell进程中执行的任务称为内建命令
export
export这个命令可以由一个子进程完成吗?
其实环境变量就是一个指针数组,保存每一个字符串的首地址
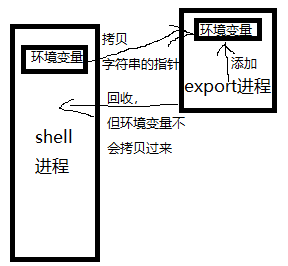
所以,export必须是一个内建命令
于是,我们要在shell进程中使用putenv这个函数为父进程添加环境变量
if(strcmp(command_args[0],"export")==0)
{
putenv((char*)command_args[1]);
continue;
}
像这样直接把strtok拆出来的环境变量putenv可以吗?

运行我们的shell,创建一个环境变量,但是env指令查看后,发现并没有找到xxx这个环境变量,说明没有添加成功。
这是因为command_arg[1]存是strtok()返回的指针,这个指针指向command_line这个字符串,
而当export函数执行完成,进行下一次输入的时候,command_line这个字符串会被env这个字符串所覆盖,
即env不能找到正确的环境变量了
所以,我们必须用一个新的字符数组进行保存这个环境变量,
if(strcmp(command_args[0],"export")==0)
{
char* new_env = (char*)malloc((strlen(command_args[1])+1)*sizeof(char));
strcpy(new_env,command_args[1]);
PutEnv(new_env);
continue;
}
此时,就可以正常创建环境变量了















 4524
4524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









