






如何利用爬虫与数据分析指导选择首篇小说类型:写作新手的实用指南
第二章 使用代理ip获取小说数据
前言
之前一篇文章已讲述如何使用爬虫获取小说数据:第一章 小说数据获取与解析
相信尝试过的读者不难发现,如果使用本地ip去获取小说数据时,多次请求网页数据后会导致连接异常,此时需要使用代理ip去执行请求数据操作,避免单一ip频繁请求导致网站封禁。
目前获取代理ip途径有付费和免费两种模式,以下详细讲述两种模式的实现方式。
一、付费获取代理ip
1.获取代理ip
网上付费代理ip网站众多,本次以快代理网站为例,说明如何使用其付费模式。
一般付费网站都有试用模式,以快代理网站为例,每种代理模式可免费使用6小时,足够大家尝试使用。
进入官网点击欢迎使用,选择其中一种代理方式,博主已试用过隧道代理,故此次使用私密代理方式以做演示。
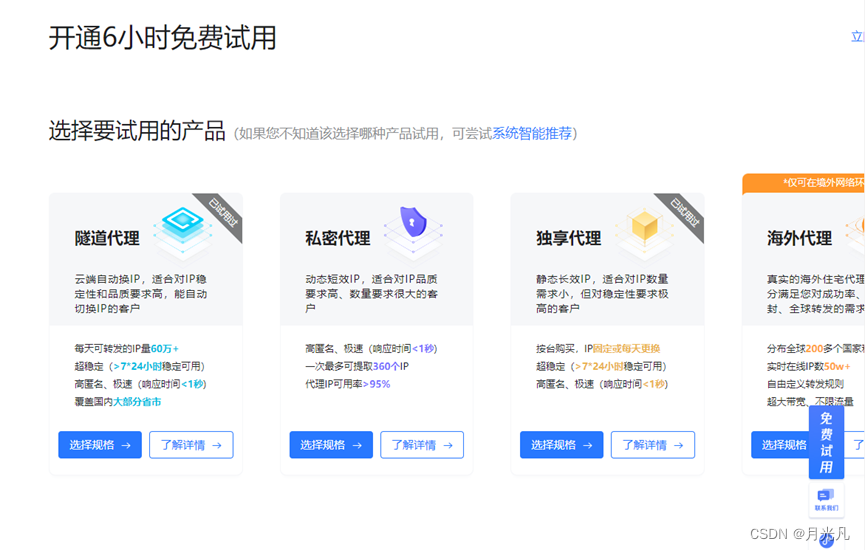
点击私密代理方式出现下图:
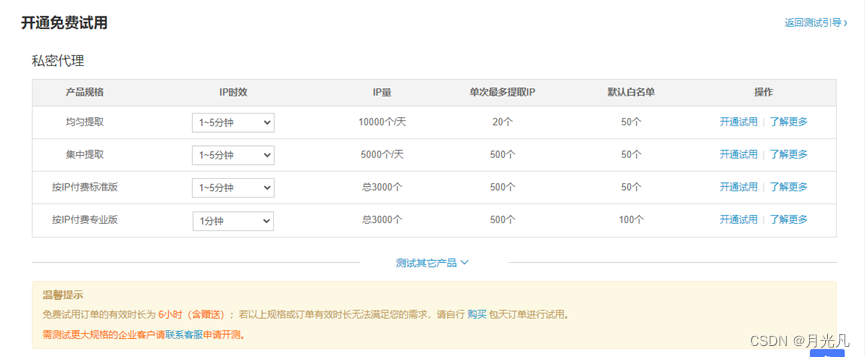
选择集中提取并开通试用,如下图所示:
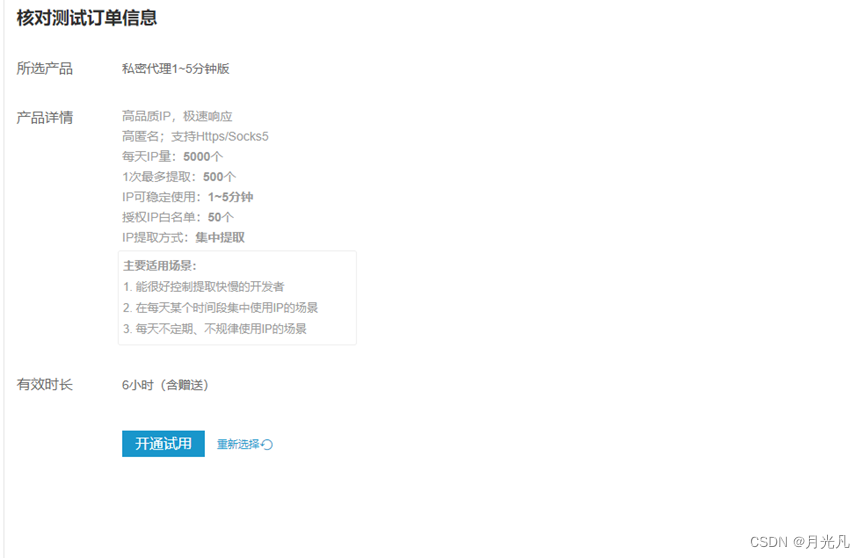
至此完成试用开通,点击开发指南可观看详细信息:
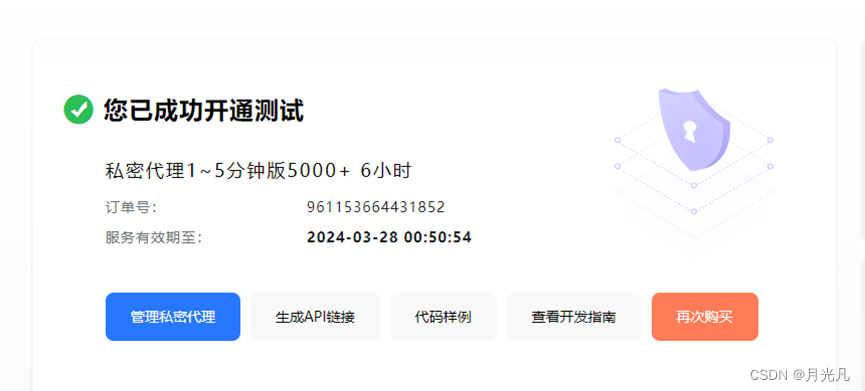

从账户管理内查找全部订单,可查阅开通的订单详情,点击刚刚开通的私密代理进入详情页面。
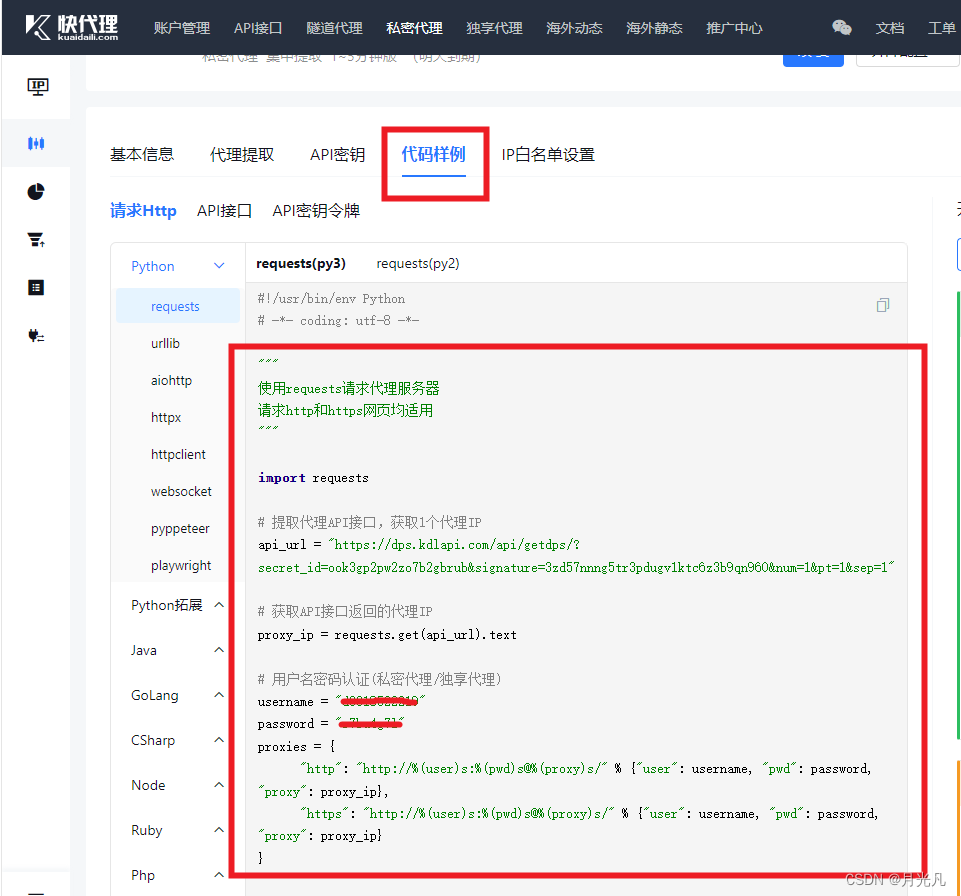
切换至代码样例,里面包含调用api接口随机生成返回代理ip以及账号、密码凭证,可直接使用。
2.使用代理ip
将上述返回代理ip代码封装成函数方便调用:
def getProxies():
# 提取代理API接口,获取1个代理IP
api_url = "https://dps.kdlapi.com/api/getdps/?secret_id=ook3gp2pw2zo7b2gbrub&signature=3zd57nnng5tr3pdugv1ktc6z3b9qn960&num=1&pt=1&sep=1"
# 获取API接口返回的代理IP
proxy_ip = requests.get(api_url).text
# 用户名密码认证(私密代理/独享代理)
username = "d3318522219"
password = "s7*****l"
#
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip}
}
return proxies
然后改造第一章 小说数据获取与解析的代码
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Mobile Safari/537.36',
'Cookie': 'newstatisticUUID=1687606367_135137479; fu=1132719504; supportwebp=true; supportWebp=true; _ga_D20NXNVDG2=GS1.1.1698680222.2.0.1698680231.0.0.0; _ga_VMQL7235X0=GS1.1.1698680222.2.0.1698680231.0.0.0; _csrfToken=8c77025c-97fa-44ff-8029-a31ab8aa56f9; traffic_utm_referer=https%3A//www.baidu.com/link; Hm_lvt_f00f67093ce2f38f215010b699629083=1710860919,1710935729,1711019219,1711187302; Hm_lpvt_f00f67093ce2f38f215010b699629083=1711187302; _yep_uuid=831915fd-ea5d-b598-f669-6482d91cd7e2; _gid=GA1.2.1754461931.1711187303; _gat_gtag_UA_199934072_2=1; _ga_FZMMH98S83=GS1.1.1711187302.10.0.1711187302.0.0.0; _ga=GA1.1.1178557524.1687606367; _ga_PFYW0QLV3P=GS1.1.1711187302.10.0.1711187302.0.0.0; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A10%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A114%22%7D; w_tsfp=ltvgWVEE2utBvS0Q6aLhkkynFT07Z2R7xFw0D+M9Os09AaIpVZ2F1IN9udfldCyCt5Mxutrd9MVxYnGAV94ifhEdRsWTb5tH1VPHx8NlntdKRQJtA83YW1YXKrIh7TVFKT8LcBGy2D15IoFByeNmiA0EsSEg37ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgS3A9wqpcgQ2Xusewk+A1SgfDngj4RG7dOldNRytI86vWO0wrTPzwjn3apCs2RYx/UJk6EtuWZaxhCfAPX4VKFhsbVzg1Lkkfqf4PuFx6jcbVKQcGg8SoF4Yt+s66wk=',
} # 请求头 若不携带cookie 请求返回202
##########根据起点首页获得强推网址
url = r'https://www.qidian.com/' #起点中文网首页
while True:
try:
proxies = getProxies() #每次请求前先调用获取代理ip
response = requests.get(url, headers=headers, proxies=proxies)
if response.status_code == 200:
break
except Exception as e:
print(e)
pass
soup = BeautifulSoup(response.text,'html.parser') #获取请求返回网页资源
div_strongrecWrap = soup.find('div', 'book-list-wrap mr30 fl') #根据div的class属性获取往期强推div信息
a_tag = div_strongrecWrap.find('a')
strongrecWrap = r'https:' + a_tag['href'] #根据往期强推div信息获取网址
##########获取3个月内强推小说网址
while True:
try:
proxies = getProxies() #每次请求前先调用获取代理ip
response = requests.get(strongrecWrap, headers=headers, proxies=proxies) # 获取往期强推网页资源
if response.status_code == 200:
break
except Exception as e:
print(e)
pass
soup = BeautifulSoup(response.text,'html.parser')
lists = soup.findAll('li', 'strongrec-list book-list-wrap') # 获取3个月内所有小说列表资源
timeList = []
novel_href_list = []
for list in lists:
time = list.find('span', 'date-from').text #获取每周的开始日期
novelLists = list.findAll('li')
for novel in novelLists:
a_tag = novel.find('a', 'name')
novelHref = r'https:' + a_tag['href'] #获取每本小说的网址
timeList.append(time) #获取3个月内小说强推日期
novel_href_list.append(novelHref) #获取3个月内小说列表
############根据小说网址获取小说详细数据
novelInfoList = [] #3个月内小说信息总列表
for id in range(len(novel_href_list)):
print(novel_href_list[id])
while True:
try:
proxies = getProxies() #每次请求前先调用获取代理ip
response = requests.get(novel_href_list[id], headers=headers,proxies=proxies) # 获取小说网址网页资源
if response.status_code == 200:
break
except Exception as e:
print(e)
pass
soup = BeautifulSoup(response.text, 'html.parser')
bookName = soup.find('h1',id='bookName').text #小说名
book_attribute = soup.find('p', 'book-attribute')
channel_type = book_attribute.findAll('a')
channel = channel_type[0].text #小说频道
novelType = channel_type[1].text #小说类型
count = soup.find('p', 'count').findAll('em')
total_num_word = count[0].text #小说字数
total_recommend = count[1].text #总推荐
week_recommend = count[2].text #周推荐
mouth_count = soup.find('p', id='monthCount').text #月票
writer_name = soup.find('a', 'writer-name').text #作者名
level = soup.find('div', 'outer-intro').find('p').text #作者等级
authorInfo = soup.findAll('em', 'color-font-card')
works_num = authorInfo[0].text #作者作品数
total_words = authorInfo[1].text #作者创作字数
write_days = authorInfo[2].text #作者创作天数
#####获取小说上架字数
catalog_volumes = soup.findAll('div', 'catalog-volume')
chapter_itemList = [] ###免费章节可能分为几大板块,获取所有板块的免费章节信息
for catalog_volume in catalog_volumes:
free = catalog_volume.find('span', 'free')
if free:
chapter_items = catalog_volume.findAll('li', 'chapter-item')
chapter_itemList.extend(chapter_items)
#####获取免费小说字数
novelWords = 0 #小说免费字数
for chapter_item in chapter_itemList:
chapter_href = r'https:' + chapter_item.find('a', 'chapter-name')['href']
print(bookName,chapter_href)
while True:
try:
proxies = getProxies() #每次请求前先调用获取代理ip
chapter_response = requests.get(chapter_href, headers=headers,proxies=proxies) # 获取小说网址网页资源
if chapter_response.status_code == 200:
break
except Exception as e:
print(e)
pass
chapter_soup = BeautifulSoup(chapter_response.text, 'html.parser')
chapter_main = chapter_soup.find('main', 'content mt-1.5em text-s-gray-900 leading-[1.8] relative z-0 r-font-black')
content_texts = chapter_main.findAll('p')
novelText = ''.join([_.text for _ in content_texts]) #获取小说内容
novelText = "".join(novelText.split()) #去除空格
novelWords += len(novelText)
novelDict = {
'id': id,
'time': timeList[id],
'novel_href': novel_href_list[id],
'bookName':bookName,
'channel': channel,
'novelType': novelType,
'total_num_word': total_num_word,
'total_recommend': total_recommend,
'week_recommend': week_recommend,
'mouth_count': mouth_count,
'writer_name': writer_name,
'level': level,
'works_num': works_num,
'total_words': total_words,
'write_days': write_days,
'novelWords':novelWords,
}
novelInfoList.append(novelDict) #3个月内小说信息总列表
最后将获取的小说数据保存入文件中,先封装一个保存数据函数:
##############保存数据
def pd_toExcel(data, fileName): # pandas库储存数据到excel
ids = []
time = []
novel_href = []
bookName = []
channel = []
novelType = []
total_num_word = []
total_recommend = []
week_recommend = []
mouth_count = []
novelWords = []
writer_name = []
level = []
works_num = []
total_words = []
write_days = []
for i in range(len(data)):
ids.append(data[i]["id"])
time.append(data[i]["time"])
novel_href.append(data[i]["novel_href"])
bookName.append(data[i]["bookName"])
channel.append(data[i]["channel"])
novelType.append(data[i]["novelType"])
total_num_word.append(data[i]["total_num_word"])
total_recommend.append(data[i]["total_recommend"])
week_recommend.append(data[i]["week_recommend"])
mouth_count.append(data[i]["mouth_count"])
novelWords.append(data[i]["novelWords"])
writer_name.append(data[i]["writer_name"])
level.append(data[i]["level"])
works_num.append(data[i]["works_num"])
total_words.append(data[i]["total_words"])
write_days.append(data[i]["write_days"])
dfData = { # 用字典设置DataFrame所需数据
'序号': ids,
'时间': time,
'网址': novel_href,
'书名': bookName,
'频道': channel,
'类目': novelType,
'字数': total_num_word,
'总推荐': total_recommend,
'周推荐': week_recommend,
'月票': mouth_count,
'上架字数': novelWords,
'作者': writer_name,
'级别': level,
'作品数': works_num,
'累计字数': total_words,
'创作天数': write_days,
}
df = pd.DataFrame(dfData) # 创建DataFrame
df.to_excel(fileName, index=False) # 存表,去除原始索引列(0,1,2...)
后直接调用函数保存数据:
fileName = '小说数据.xlsx'
pd_toExcel(novelInfoList, fileName)
当然上述代码有许多重复代理可提取封装,读者可自行优化。
二、免费获取代理ip
1.免费代理ip网站
66网:http://www.66ip.cn/
89网:https://www.89ip.cn/
快代理:https://www.kuaidaili.com/free/dps/
开心代理:http://www.kxdaili.com/dailiip.html
云代理:http://www.ip3366.net/free/
站大爷:https://www.zdaye.com/free/
等。。。
其提供免费代理ip样例如下:
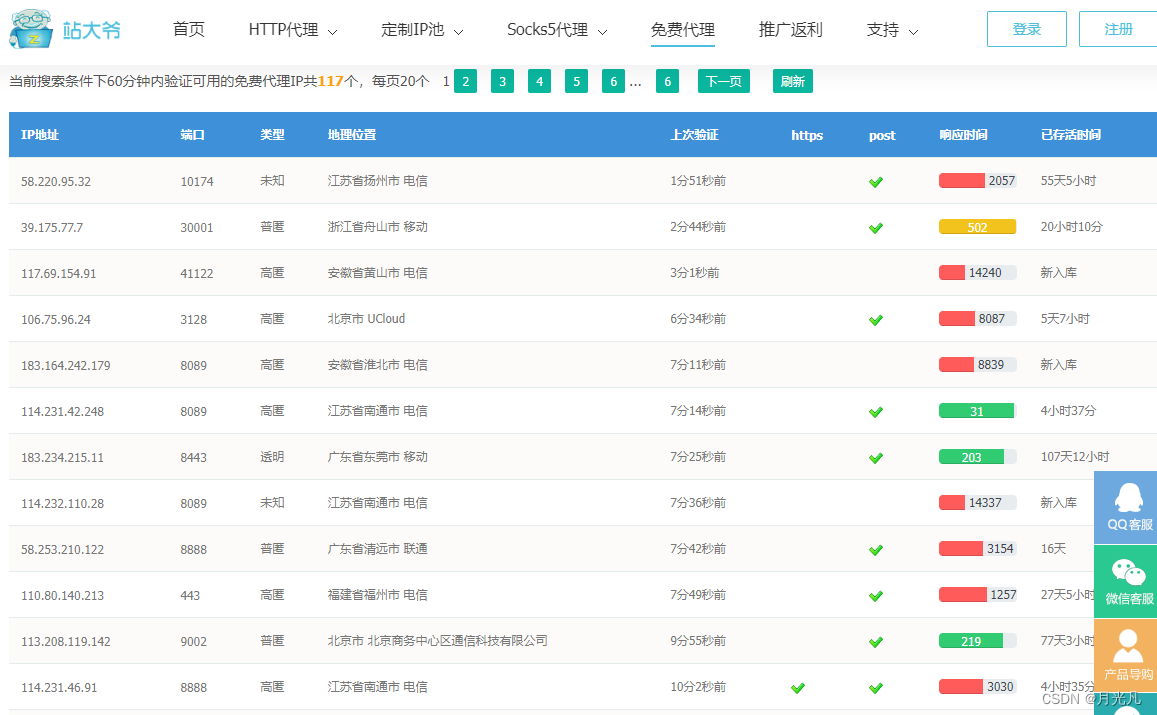
2.免费代理ip使用实现
代码如下(示例):
def getProxies():
# 根据上述免费代理ip网址挑选ip,组成ip池,以下为样例列表
ipList = ["58.220.95.32:10174","39.175.77.7:30001"]
ip = random.choice(ipList )
#
proxies = {
"http": ip,
"https": ip
}
return proxies
其余业务代理实现与第一节业务代码一样。
当然免费代理ip不稳定,且上述操作需人为进入代理ip网址,并在代码中写死ip组成ip池,基本无法保证可靠性,最佳方式是使用爬虫,先去上述众多免费代理ip网站自动获取免费ip,组成ip池,再自动ip是否可用,如果ip池中ip皆不可用,再重新爬取ip组成ip池,重复上述操作,直到获取可用ip。
总结
希望上述关于付费代理ip模式和免费代理ip模式的讲解对大家能有所帮助,下一篇文章博主将实现如何使用爬虫,先去上述众多免费代理ip网站自动获取免费ip,组成ip池,再自动ip是否可用,如果ip池中ip皆不可用,再重新爬取ip组成ip池,重复上述操作,直到获取可用ip。并且优化业务代码,封装重复代码,并处理运行中可能出现的各种bug。

















 4537
4537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











