







R语言实战-电信用户流失
一、提出问题
- 分析用户特征与流失的关系
- 流失用户普遍具有哪些特征?
- 建立模型预测流失用户。
- 针对性给出增加用户黏性、降低流失率的建议。
本文数据使用kaggle上的 telco-customer-churn 数据集
二、数据描述
| 分类 | 变量 | 变量名称 | 备注 |
|---|---|---|---|
| customerID | 客户ID | ||
| 用户属性 | gender | 性别 | male & female |
| 用户属性 | SeniorCitizen | 老年用户 | 是为1,否为0 |
| 用户属性 | Partner | 伴侣用户 | Yes or No |
| 用户属性 | Dependents | 亲属用户 | Yes or No |
| 用户属性 | tenure | 在网时长 | 0-72月 |
| 服务属性 | PhoneService | 是否开通电话服务 | Yes or No |
| 服务属性 | MultipleLines | 是否有多条线路 | Yes 、No or No phoneservice (无电话服务)三种 |
| 服务属性 | InternetService | 是否开通互联网服务 | No, DSL数字网络,fiber optic光纤网络 |
| 服务属性 | OnlineSecurity | 是否开通网络安全服务 | Yes,No,No internetserive(无互联网服务) |
| 服务属性 | OnlineBackup | 是否开通在线备份服务 | Yes,No,No internetserive(无互联网服务) |
| 服务属性 | DeviceProtection | 是否开通设备保护服务 | Yes,No,No internetserive(无互联网服务) |
| 服务属性 | TechSupport | 是否开通技术支持服务 | Yes,No,No internetserive(无互联网服务) |
| 服务属性 | StreamingTV | 是否开通网络电视 | Yes,No,No internetserive(无互联网服务) |
| 服务属性 | StreamingMovies | 是否开通网络电影 | Yes,No,No internetserive(无互联网服务) |
| 合同属性 | Contract | 签订合同方式 | 按月,一年,两年 |
| 合同属性 | PaperlessBilling | 是否开通电子账单 | Yes or No |
| 合同属性 | PaymentMethod | 付款方式 | bank transfer银行转账,credit card信用卡,electronic check电子支票,mailed check邮寄支票 |
| 合同属性 | MonthlyCharges | 月租费 | 18.85-118.35 |
| 合同属性 | TotalCharges | 累计付费 | 18.85-8684.8 |
| 合同属性 | Churn | 该用户是否流失 | Yes or No |
三、数据预处理
1. 提前加载所需程序包
library(ggplot2)
library(scales)
library(grid)
library(GGally)
library(rpart)
library(mice)
2. 数据连接
data <- read.csv("C://Users/dell/Desktop/WA_Fn-UseC_-Telco-Customer-Churn.csv"
,header = T)
attach(data)
class(data)

3. 查看数据
dim(data)
head(data)
str(data)
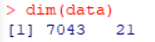
- 该数据集有7043行,21列,即有21个变量,7043行数据,初步预览数据:


4. 缺失值处理
#查看缺失值
is.null(data)
md.pattern(data)

- 由结果可以看出数据无空值,但有11个缺失值,均出现在TotalCharges列,查看缺失值占比:
#计算缺失值个数占比
na<-is.na(data$TotalCharges)
na[na==FALSE]<-0
na[na==TRUE]<-1
na.rate<-as.numeric(sum(na)/length(na))
na.rate

- 可以看出缺失值占比为1.56%,占比较小,因此剔除缺失值
#剔除缺失值
data<-na.omit(data)
#再次检验是否有缺失值
md.pattern(data)

- 结果显示数据处理后已无缺失值
5. 调整数据类型
str(data)#查看数据类型

- 我们可以发现SeniorCitizen数据类型为int,且它与其他分类变量表现形式不一致,因此我们需要把"0"转换成"No",“1"转换成"Yes”
- 同时数据集中分类变量数据类型均为字符串,我们需要把它们的数据类型转换成因子类型
data$SeniorCitizen[data$SeniorCitizen==0]<-"No"
data$SeniorCitizen[data$SeniorCitizen==1]<-"Yes"
#转换为因子变量
for(i in c(2:5,7:18,21)) {
data[i]<-as.factor(unlist(data[i]))
}
str(data)
6. 调整变量
- 在服务属性中,变量中均有"No internetserive"类别,观察其分布,我们发现其流失比例均一致,因此我们可以简化类别,把"No internetserive"并入"No"类别中

for(i in 10:15){
print(xtabs(~ Churn + get(names(data)[i]), data = data))
}
# 将"No internetserive"并入"No"这一属性值
levels(data$OnlineSecurity)[2] <- "No"
levels(data$OnlineBackup)[2] <- "No"
levels(data$DeviceProtection)[2] <- "No"
levels(data$TechSupport)[2] <- "No"
levels(data$StreamingTV)[2] <- "No"
levels(data$StreamingMovies)[2] <- "No"
四、 观察数据
- 数据清洗后观查数据,流失用户有1869人,留存用户有5174人,流失率为26.58%
options(digits=4)
#饼图
ggplot(data, aes(x = "" ,fill = Churn))+
geom_bar(stat = "count", width = 0.5, position = 'stack')+
coord_polar(theta = "y", start=0)+
geom_text(stat="count",
aes(label = scales::percent(..count../nrow(data), 0.01)),
size=4, position=position_stack(vjust = 0.5)) +
theme(
panel.background = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank()
)
#条形图
ggplot(data , aes(x =Churn , y =..count.. ,fill=Churn)) +
geom_bar(stat = "count", width = 0.5, position = 'identity')
#表格
table(Churn)
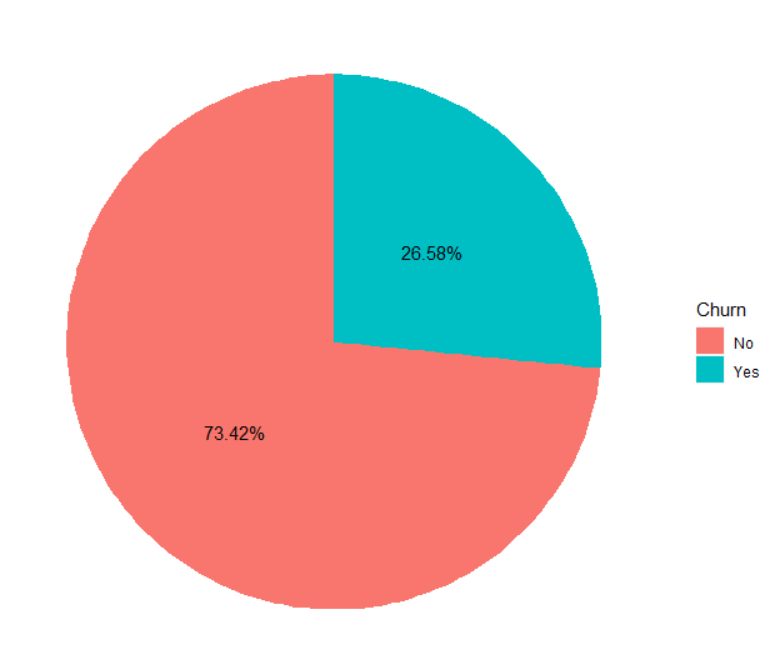

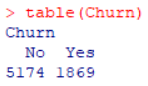
五、探索用户特征与流失的关系
1. 用户属性
用户属性的变量有:gender,SeniorCitizen,Partner,Dependents,tenure
从图中可以得出以下结论:
- 性别对用户流失并无显著影响
- 老年群体相较于其他群体,用户流失率较高
- 无伴侣的用户流失率高于有伴侣的用户流失率
- 无亲属的用户流失率高于有亲属的用户流失率
- 流失人群在网时长呈右偏分布,在网时长的流失中位数为10小时,且概率密度函数的峰值点小于5小时


#用户属性:gender,SeniorCitizen,Partner,Dependents,tenure
library(plyr)
cdata <- ddply(data, "Churn", summarise, tenure.median=median(tenure))
cdata
ggplot(data, aes(x=tenure, fill=Churn)) + geom_density(alpha=.3)+
geom_vline(data=cdata, aes(xintercept=tenure.median, colour=Churn),
linetype="dashed", size=1)
Percentage<- matrix(rep(1,nrow(data)),nrow=(nrow(data)),ncol=1)
plot1<-ggplot(data, aes(x=gender, y=Percentage, fill=Churn))+geom_col(position="fill")
plot2<-ggplot(data, aes(x=SeniorCitizen, y=Percentage, fill=Churn))+geom_col(position="fill")
plot3<-ggplot(data, aes(x=Partner, y=Percentage, fill=Churn))+geom_col(position="fill")
plot4<-ggplot(data, aes(x=Dependents, y=Percentage, fill=Churn))+geom_col(position="fill")
grid.newpage()
pushViewport(viewport(layout = grid.layout(2,2)))
vplayout <- function(x,y)
viewport(layout.pos.row = x, layout.pos.col = y)
print(plot1, vp = vplayout(1, 1))
print(plot2, vp = vplayout(1, 2))
print(plot3, vp = vplayout(2, 1))
print(plot4, vp = vplayout(2, 2))
2. 服务属性
服务属性的变量有:
PhoneService, MultipleLines, InternetService, OnlineSecurity, OnlineBackup, DeviceProtection,
TechSupport, StreamingTV, StreamingMovies
从图中可以得出以下结论:
- 电话服务:PhoneService电话服务对用户流失并无显著影响,有多条通话线路的客户流失率相对较高
- 互联网服务:开通光纤网络的用户流失率较为明显
- 互联网服务支持:OnlineSecurity(网络安全)、OnlineBackup(在线备份)、DeviceProtection(设备保护)、TechSupport(技术支持)等,开通的用户流失率较整体用户的流失率低,未开通的则高于整体的用户流失率
- 媒体服务:开通StreamingTV(网络电视)与StreamingMovies(网络电影)的流失率较未开通的要高

#服务属性:PhoneService,MultipleLines,InternetService,OnlineSecurity,OnlineBackup,
#DeviceProtection,TechSupport,StreamingTV,StreamingMovies
#流失率对比
plot4<-ggplot(data, aes(x=PhoneService, y=Percentage, fill=Churn))+geom_col(position="fill")
plot5<-ggplot(data, aes(x=MultipleLines, y=Percentage, fill=Churn))+geom_col(position="fill")
plot6<-ggplot(data, aes(x=InternetService, y=Percentage, fill=Churn))+geom_col(position="fill")
plot7<-ggplot(data, aes(x=OnlineSecurity, y=Percentage, fill=Churn))+geom_col(position="fill")
plot8<-ggplot(data, aes(x=OnlineBackup, y=Percentage, fill=Churn))+geom_col(position="fill")
plot9<-ggplot(data, aes(x=DeviceProtection, y=Percentage, fill=Churn))+geom_col(position="fill")
plot10<-ggplot(data, aes(x=TechSupport, y=Percentage, fill=Churn))+geom_col(position="fill")
plot11<-ggplot(data, aes(x=StreamingTV, y=Percentage, fill=Churn))+geom_col(position="fill")
plot12<-ggplot(data, aes(x=StreamingMovies, y=Percentage, fill=Churn))+geom_col(position="fill")
grid.newpage()
# pushViewport函数提供了添加视图以及在树中的视图之间导航的方法。
pushViewport(viewport(layout = grid.layout(3,3)))
# viewport函数创建视图,描述图形设备上的矩形区域,并在这些区域中定义许多坐标系统。
vplayout <- function(x,y)
viewport(layout.pos.row = x, layout.pos.col = y)
print(plot4, vp = vplayout(1, 1))
print(plot5, vp = vplayout(1, 2))
print(plot6, vp = vplayout(1, 3))
print(plot7, vp = vplayout(2, 1))
print(plot8, vp = vplayout(2, 2))
print(plot9, vp = vplayout(2, 3))
print(plot10, vp = vplayout(3, 1))
print(plot11, vp = vplayout(3, 2))
print(plot12, vp = vplayout(3, 3))
3. 合同属性
合同属性的变量有:
MonthlyCharges,TotalCharges,Contract,PaperlessBilling,PaymentMethod
从图中可以得出以下结论:
- 支付费用:a. 流失用户的月租费的中位数高于留存用户,且月租费位于70-100元之间的流失概率最高
b. 流失用户的累计付费中位数低于留存用户 - 按月签订合同的流失率相对较高,签订合同时间越长,流失率越低
- 开通电子账单的用户流失率高于未开通的用户流失率
- 电子支票付费的流失率相对其他付款方式相对较高


#合同属性:MonthlyCharges,TotalCharges,Contract,PaperlessBilling,PaymentMethod
#流失率对比
cdata1 <- ddply(data, "Churn", summarise, MonthlyCharges.median=median(MonthlyCharges))
cdata2 <- ddply(data, "Churn", summarise, TotalCharges.median=median(TotalCharges))
plot13<-ggplot(data, aes(x=MonthlyCharges, fill=Churn)) + geom_density(alpha=.3)+
geom_vline(data=cdata1, aes(xintercept=MonthlyCharges.median, colour=Churn),
linetype="dashed", size=1)
plot14<-ggplot(data, aes(x=TotalCharges, fill=Churn)) + geom_density(alpha=.3)+
geom_vline(data=cdata2, aes(xintercept=TotalCharges.median, colour=Churn),
linetype="dashed", size=1)
plot15<-ggplot(data, aes(x=Contract, y=Percentage, fill=Churn))+geom_col(position="fill")
plot16<-ggplot(data, aes(x=PaperlessBilling, y=Percentage, fill=Churn))+geom_col(position="fill")
plot17<-ggplot(data, aes(x=PaymentMethod, y=Percentage, fill=Churn))+geom_col(position="fill")
grid.newpage()
# pushViewport函数提供了添加视图以及在树中的视图之间导航的方法。
pushViewport(viewport(layout = grid.layout(1,2)))
# viewport函数创建视图,描述图形设备上的矩形区域,并在这些区域中定义许多坐标系统。
vplayout <- function(x,y)
viewport(layout.pos.row = x, layout.pos.col = y)
print(plot13, vp = vplayout(1, 1))
print(plot14, vp = vplayout(1, 2))
grid.newpage()
# pushViewport函数提供了添加视图以及在树中的视图之间导航的方法。
pushViewport(viewport(layout = grid.layout(3,1)))
# viewport函数创建视图,描述图形设备上的矩形区域,并在这些区域中定义许多坐标系统。
vplayout <- function(x,y)
viewport(layout.pos.row = x, layout.pos.col = y)
print(plot15, vp = vplayout(1, 1))
print(plot16, vp = vplayout(2, 1))
print(plot17, vp = vplayout(3, 1))
4.流失用户普遍具有的特征
- 用户属性:老年、无伴侣、无亲属群体,在网时长小于10小时的用户流失率较高
- 服务属性:多条通话线路、开通光纤网络、未开通互联网服务支持、开通媒体服务的用户流失率较高
- 合同属性:月租费位于70-100元、按月签订合同、开通电子账单、电子支票付费
六、相关性分析
1.分类变量相关性分析
- 分类变量的相关性分析用卡方检验,由下图得出,gender(性别)、PhoneService(电话服务)与Churn(是否流失)的p值大于显著性水平0.05,即gender(性别)、PhoneService(电话服务)与Churn(是否流失)不相关,因此可以筛选掉gender与PhoneService

2.连续变量相关性分析
- 可以观察到TotalCharges分别与tenure、MonthlyCharges相关系数较高,分别为0.826、0.651,而tenure与MonthlyCharges的相关系数较低,所以筛掉TotalCharges变量

3. 筛选变量
- customerID是区分用户的变量,因此也可以筛选掉
- 因此最后去掉customerID、gender、PhoneService和TotalCharges变量

#相关性分析:1.分类变量2.连续变量
#1.分类变量
myFUN<- function(x){chisq.test(data$Churn,x ,correct = TRUE)}
#apply(数据库,循环数据库3到6列,按列,函数)
colnames(data)
xx = c("customerID","tenure","MonthlyCharges","TotalCharges")
dataset = data[,!names(data) %in% xx]
result<- apply (dataset,2, myFUN)
#创建功能,提取list每个循环的p.value
p<- function(x){x$p.value}
#转化成数据,sapple(数据框,函数)
p2<-as.data.frame(sapply(result,p))
#保留小数点后面3位小数
result=as.data.frame(round(p2$`sapply(result, p)`,3))
#添加比较组的行名
A<-names(dataset)
A
rownames(result)=A
result
#2.连续变量
ggpairs(data,columns=c(6,19:20),ggplot2::aes(color=data$Churn))
#3.去掉不相关变量
xx = c("customerID","gender","TotalCharges")
data1 = data[,!names(data) %in% xx]
head(data1)
七、建立分类预测模型
1. 划分训练集与测试集
- 按7:3的比例划分训练集和测试集
#划分训练集和测试集
set.seed(1234) #随机抽样设置种子
train<-sample(nrow(data),0.7*nrow(data)) #抽样函数,第一个参数为向量,nrow()返回行数 后面的是抽样参数前
tdata<-data1[train,] #训练数据集
vdata<-data1[-train,] #测试数据集
2. 建立决策树预测模型
| 算法 | 区分要点 | R包 |
|---|---|---|
| ID3 | 使用信息增益 | rpart包中rpart函数 |
| C4.5 | 使用信息增益 | RWeka包中J48() |
| CART | 使用gini | rpart包中rpart函数 |
| C5.0 | C4.5的改进,比较适合于大规模数据 | c50包 |
- 本文使用CART算法建模
#CART
dtree<-rpart(Churn~.,data=tdata,method="class",parms=list(split="gini"))#运用二分类决策树CART算法
- 查看cp参数复杂度
printcp(dtree)#查看cp参数复杂度,cp越大数分裂规模越小
- cp是参数复杂度(complexity parameter)作为控制树规模的惩罚因子,简而言之,就是cp越大,树分裂规模(nsplit)越小。输出参数(rel error)指示了当前分类模型树与空树之间的平均偏差比值。xerror为交叉验证误差,xstd为交叉验证误差的标准差。可以看到,当nsplit为3的时候,即有四个叶子结点的树,交叉误差最小。决策树剪枝的目的就是为了得到更小交叉误差(xerror)的树。

- 进行剪枝
tree<-prune(dtree,cp=dtree$cptable[which.min(dtree$cptable[,"xerror"]),"CP"])#剪枝,自动选择最小exerror的cp值来剪枝
opar<-par(no.readonly = T)
par(mfrow=c(1,2))
library(rpart.plot)
png(file = "G://R/tree1.png")
rpart.plot(dtree,branch=1,type=2, fallen.leaves=T,cex=0.8, sub="剪枝前")
png(file = "G://R/tree2.png")
rpart.plot(tree,branch=1, type=4,fallen.leaves=T,cex=0.8, sub="剪枝后")
par(opar)
dev.off()
- 剪枝前后模型并无差异


- 该决策树模型说明若一个用户按月签订合同、网络服务为光纤上网,且在网时长小于15小时,则该用户会流失
predtree<-predict(tree,newdata=vdata,type="class") #利用预测集进行预测
table(vdata$Churn,predtree,dnn=c("真实值","预测值")) #输出混淆矩阵
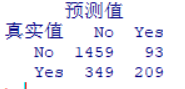
- 模型正确率=(1459+209)/(1459+93+349+209)* 100%=79.05%
八、运营建议
- 运用预测模型,构建一个高流失率的用户列表,通过对这批用户进行用户调研,了解产品缺陷
1. 用户层面
- 针对老年用户、无亲属、无伴侣用户,制定个性化专属服务,如推出亲属套餐、关爱套餐等,加强这类用户粘性的同时,也加强了与其他用户的关联度,从而加强了其他用户的粘性,形成良性闭环。
2. 服务层面
- 针对光纤网络,随机挑选一批流失用户,发放调查问卷(填问卷赠消费券,提升用户的积极性),调查光纤网络服务体验,针对调查结果改善服务
- 针对新用户,降低第一年月租费,免费试用三个月的互联网服务支持(网络安全服务、在线备份服务、设备保护服务、技术支持服务),试用期结束即可获得首月开通互联网服务支持半价,后续月租85折的优惠,鼓励用户开通互联网服务支持的同时,也提升了用户的在网时长,降低了月租费,以此度过用户的流失高峰期
- 优化媒体服务的网络体验,并对用户提供增值服务,如提供首月免费体验VIP等服务
3. 合同层面
- 针对单月合同用户,建议推出年合同付费折扣活动,将月合同用户转化为年合同用户,提高用户在网时长,以达到更高的用户留存;同时可以加大签订两年合同的优惠力度,通过折扣购手机或者送流量、送家庭宽带,分月返话费的方式引导用户签订2年合同
- 针对电子账单,需考虑是否是电子账单的用户体验不好,或者电子账单呈现的消费明细角度有问题,优化电子账单
- 针对电子支票付费,建议推出使用其他支付方式随机立减的活动,以减少用户流失
本文参考了以下文章















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









