







神经网络这么牛掰,归功于其强大的学习能力,而神经网络模型的好坏则依赖于Error Back Propagation 算法的强力支撑,现在对其进行一下推导,知其然知其所以然~
神经网络简介
神经网络,顾名思义是尝试去模仿动物神经系统的一种网络模型。举个例子,如下图:
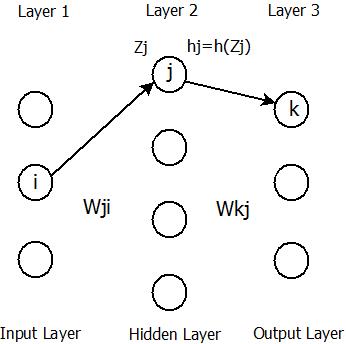
Zj 表示单元 j 的输入,
具体的神经网络的一些优势劣势之类的就不在这里细说了,大家可以自己去看,现在重点讲一下,神经网络里面的参数调整与误差的关系, 为什么叫误差后传,以及Error Back Progapation的推导核心。
Error Back Propagation
优化的目标函数
BPNN模型
f(x;w)
的好坏是用误差的期望
E[(f(x;w)−y)2]
来评估的。
这样模型最优参数的计算,就成了
woptimal=minw{E[(f(x;w)−y)2]}
,于是抽象为数学中的最值问题。
之前也有讲过,参数寻优的方法中,有借助于梯度来不断迭代找到最优参数的。详细见:http://blog.csdn.net/yujianmin1990/article/details/47461287
现在,也想对神经网络模型函数的参数
w
求导,以期望能够不断迭代
不同于一般模型的是,神经网络是多层参数递进叠加到一起的,后面一层输入量与前面一层的输出量紧密联系。因此,妄图直接对所有层间的权重
WL
同时求偏导不是明智的做法.
如果前后两层间的权重偏导数存在着一点关系,岂不是很美妙,BP的设想正是基于此~
神经网络的最小化目标函数是:
其中Error(xi)=12∑k(dk(xi)−yk(xi))2 是单样本误差期望的衡量, k 表示输出单元个数。
逐层求导过程
1)先计算一下单个样本误差对上面图中第三层权重
Wkj
的偏导:
∂E∂W(L)kj=∂∂W(L)kj[12∑k(dk−yk)2]=(dk−yk)∗∂dk∂W(L)kj
已知:
d(L)k(zk)=h(L)k(zk)=h(∑jWkj∗h(L−1)j+b(L)k)
=(dk−yk)∗∂h(L)k(zk)∂W(L)kj=(dk−yk)∗∂h(L)k(zk)∂zk∗∂zkW(L)kj
=(dk−yk)∗h′(L)k(zk)∗h(L−1)j
2)再计算一下误差期望对上面图中第二层权重
Wji
的偏导:
Error缩写为E
∂E∂W(L−1)ji=∂∂W(L−1)ji[12∑k(dk−yk)2]
=∑k(dk−yk)∗∂∂W(L−1)ji[h(L)k(zk)]=∑k(dk−yk)∗∂h(L)k(zk)∂zk∗∂zk∂W(L−1)ji
zk=∑jW(L)kjh(L−1)j(zj)+b(L)k
;于是
∂zk∂W(L−1)ji=W(L)kj⋅∂h(L−1)j(zj)∂zj⋅∂zj∂W(L−1)ji
zj=∑iW(L−1)jihL−2i(zi)+b(L−1)j
;于是
∂zj∂W(L−1)ji=hL−2i(zi)
得到最终:
∂E∂W(L−1)ji=∑k(dk−yk)∗∂h(L)(zk)∂zk∗[W(L)kj⋅∂h(L−1)(zj)∂zj⋅h(L−2)i(zi)]
3)我们将两层参数的偏导放到一块比较异同
⎧⎩⎨⎪⎪⎪⎪∂E∂W(L)kj=(dk−yk)∗h′(L)k∗h(L−1)j ∂E∂W(L−1)ji=∑k(dk−yk)∗h′(L)k∗[W(L)kj⋅h′(L−1)j⋅h(L−2)i]
假设:
⎧⎩⎨δ(L)k=(dk−yk)∗h′(L)kδ(L−1)j=∑k[δ(L)kWkj]⋅h′(L−1)j将δ通过Wkj向输入的方向传递
再放到一起比较一下,则两者更像了:
δ(L)k 与 δ(L−1)j 的关系,可以明确地看到,是将后面的 δ(L) 经过神经网络直接往输入方向计算得到之前的 δ(L−1) 的。
对偏移 b 求导数,得到
继续往下推, δ(L−2)n=∑j[δ(L−1)jWjn]⋅h′(L−2)n ,可以推广到更多层。
这样我们看到在最后一层的误差 d−y 通过层间权重和 h′ 逐层往前传递,这也是 误差后传的出处。
4)推导规律总结:notice
=========================================================
W(L) 记做第 L 层的权重,连接
a)计算 L+1 层的输出误差:
a.1) δ′(L+1)={∑W(L+2)δ(L+2)h−y,后层传递过来的δ,本层直接差h−y(最后一层时)
a.2) δ(L+1)=δ′(L+1)∗h′(L+1) 乘以本层的激活函数的导数。
b)更新权重: ΔW(L)=h(L)∗δ(L+1) 本层输出*下层的 δ 。
c)更新偏 : Δb(L)=δ(L+1)
=========================================================
小结
1) BPNN主要是想通过参数求偏导数,然后迭代的方法寻找最优参数解。
逐层求偏导,结果发现层间的权重偏导是存在逐层递进关系的。
2) 另,一个隐层的BPNN最好调,两个隐层的BPNN稍微难调点,三层就开始难了。
代码仅附单隐层和双隐层的BPNN的参数,BP类是支持n层的。
附:Error Back Propagation 对梯度加上动量优化后的伪码。
对所有的层2≤l≤L,设ΔW(l),这里ΔW(l)为全零矩阵;
For i=1:m,
使用反向传播算法,计算各层神经元权值的梯度矩阵?W(l)(i);
计算ΔW(l)=ΔW(l)+?W(l)(i);
(在Rumelhart的论文[1]中建议对ΔW(l)如下处理,以加快下降速度)
(ΔW(l):=−εΔW(l)currentIter+αΔW(l)previousIter)
更新权值和偏置:
计算W(l)=W(l)+1mΔW(l);
参考文献
[1] Learning Representations by Back-propagating Errors 这个文章里并没有给出误差后传的样子,是不是我看得不细致啊。
[2] A Gentle Introduction to Backpropagation
[3] http://www.cnblogs.com/biaoyu/archive/2015/06/20/4591304.html
BPNN的实现对手写字体的识别,python代码实现(96%准确率):https://github.com/jxyyjm/test_nn/blob/master/src/mine_bpnn_epoch.py
sklearn的NN代码(不是BPNN),对手写字体识别(98%准确率):https://github.com/jxyyjm/test_nn/blob/master/src/sklearn_nn.py
#!/usr/bin/python
# -*- coding:utf-8 -*
## @time : 2017-06-17
## @author : yujianmin
## @reference : http://blog.csdn.net/yujianmin1990/article/details/49935007
## @what-to-do : try to make a any-layer-nn by hand (one-input-layer; any-hidden-layer; one-output-layer)
from __future__ import division
from __future__ import print_function
import logging
import numpy as np
from sklearn import metrics
from tensorflow.examples.tutorials.mnist import input_data
## =========================================== ##
'''
== input-layer == | == hidden-layer-1 == | == hidden-layer-2 == | == output-layer ==
I[0]-W[0]B[0]-P[0] | I[1]-W[1]B[1]-P[1] | I[2]-W[2]B[2]-P[2] | I[3]-W[3]B[3]-P[3]
E[0]-DH[0]-D[0] | E[1]-DH[1]-D[1] | E[2]-DH[2]-D[2] | E[3]-DH[3]-D[3]
DW[0]-DB[0] | DW[1]-DB[1] | DW[2]-DB[2] | DW[3]-DB[3]
'''
# I--input; W--weight; P--probabilty
# E--error; DH-delt_active_function; D--delt
# DW--delt_W; DB--delt_B
## =========================================== ##
class CMyBPNN:
def __init__(self, hidden_nodes_list=[10, 10], batch_size=100, epoch=100, lr=0.5):
self.train_data = ''
self.test_data = ''
self.model = ''
self.W = []
self.B = []
self.C = []
self.middle_res = {}
self.lr = lr
self.epoch = epoch
self.batch_size = batch_size
self.layer_num = len(hidden_nodes_list)+2
self.hidden_nodes_list = hidden_nodes_list
self.middle_res_file = './middle.res1'
def __del__(self):
self.train_data = ''
self.test_data = ''
self.model = ''
self.W = []
self.B = []
self.C = []
self.middle_res = {}
self.lr = ''
self.epoch = ''
self.batch_size = ''
self.layer_num = ''
self.hidden_nodes_list = []
self.middle_res_file = ''
def read_data(self):
mnist = input_data.read_data_sets('./MNIST_data', one_hot=True)
self.train_data = mnist.train
self.test_data = mnist.test
def sigmoid(self, x):
return 1/(1+np.exp(-x))
def delt_sigmoid(self, x):
#return -np.exp(-x)/((1+np.exp(-x))**2)
return self.sigmoid(x) * (1-self.sigmoid(x))
def get_label_pred(self, pred_mat):
return np.argmax(pred_mat, axis=1)
def compute_layer_input(self, layer_num):
input = self.middle_res['layer_prob'][layer_num-1]
return np.dot(input, self.W[layer_num-1]) + self.B[layer_num-1]
def compute_layer_active(self, layer_num):
return self.sigmoid(self.middle_res['layer_input'][layer_num])
def compute_layer_delt(self, layer_num):
return self.delt_sigmoid(self.middle_res['layer_input'][layer_num])
def compute_diff(self, A, B):
if len(A) != len(B):
print ('A.shape:', A.shape, 'B.shape:', B.shape)
return False
error_mean= np.mean((A-B)**2)
if error_mean>0:
print ('(A-B)**2 = ', error_mean)
return False
else: return True
def initial_weight_parameters(self):
input_node_num = self.train_data.images.shape[1]
output_node_num = self.train_data.labels.shape[1]
## 构造各层W (输入, 输出) node-num-pair 的 list ##
node_num_pair = [(input_node_num, self.hidden_nodes_list[0])]
for i in xrange(len(self.hidden_nodes_list)):
if i == len(self.hidden_nodes_list)-1: node_num_pair.append((self.hidden_nodes_list[i], output_node_num))
else: node_num_pair.append((self.hidden_nodes_list[i], self.hidden_nodes_list[i+1]))
for node_num_i, node_num_o in node_num_pair:
W = np.reshape(np.array(np.random.normal(0, 0.001, node_num_i*node_num_o)), (node_num_i, node_num_o))
B = np.array(np.random.normal(0, 0.001, node_num_o)) ## 正向时的 Bias ##
self.W.append(W)
self.B.append(B)
## W,B,C len is self.layer_num-1 ##
def initial_middle_parameters(self):
self.middle_res['delt_W'] = [np.zeros_like(i) for i in self.W] ## 层与层之间的连接权重 #
self.middle_res['delt_B'] = [np.zeros_like(i) for i in self.B] ## 前向传播时的偏倚量 #
self.middle_res['layer_input'] = ['' for i in xrange(self.layer_num) ] ## 前向传播时的每层输入 #
self.middle_res['layer_prob'] = ['' for i in xrange(self.layer_num) ] ## 前向传播时的每层激活概率 #
self.middle_res['layer_delt'] = ['' for i in xrange(self.layer_num) ] ## 每层误差回传时,的起始误差 #
self.middle_res['layer_wucha'] = ['' for i in xrange(self.layer_num) ] ## 每层由后层传递过来的误差 #
self.middle_res['layer_active_delt'] = ['' for i in xrange(self.layer_num) ] ## 前向传播的激活后导数 #
def forward_propagate(self, batch_x):
## 前向依层,计算 --> output ## 并保存中间结果 ##
## 0-layer ====== 1-layer; ====== 2-layer; ===== output-layer ##
## I[0]-W[0]-B[0] I[1]-W[1]-B[1] I[2]-W[2]-B[2]
for layer_num in xrange(self.layer_num):
if layer_num == 0:
self.middle_res['layer_input'][layer_num] = batch_x
self.middle_res['layer_prob'][layer_num] = batch_x
self.middle_res['layer_active_delt'][layer_num] = batch_x
else:
self.middle_res['layer_input'][layer_num] = self.compute_layer_input(layer_num)
self.middle_res['layer_prob'][layer_num] = self.compute_layer_active(layer_num)
self.middle_res['layer_active_delt'][layer_num]= self.compute_layer_delt(layer_num)
def compute_output_prob(self, x):
for layer_num in xrange(self.layer_num):
if layer_num == 0:
output = x
else:
layer_num = layer_num -1
output = self.sigmoid(np.dot(output, self.W[layer_num])+self.B[layer_num])
return output
def backward_propagate(self, batch_y):
## 后向依层,计算 --> delt ## 并保存中间结果 ##
for layer_num in xrange(self.layer_num, 0, -1):
layer_num = layer_num - 1
if layer_num == (self.layer_num -1):
self.middle_res['layer_wucha'][layer_num] = self.middle_res['layer_prob'][layer_num] - batch_y
self.middle_res['layer_delt'][layer_num] = \
self.middle_res['layer_wucha'][layer_num] * self.middle_res['layer_active_delt'][layer_num]
else:
self.middle_res['layer_wucha'][layer_num] = \
np.dot(self.middle_res['layer_delt'][layer_num+1], self.W[layer_num].T)
self.middle_res['layer_delt'][layer_num] = \
self.middle_res['layer_wucha'][layer_num] * self.middle_res['layer_active_delt'][layer_num]
self.middle_res['delt_W'][layer_num] = \
np.dot(self.middle_res['layer_prob'][layer_num].T, self.middle_res['layer_delt'][layer_num+1])/self.batch_size
self.middle_res['delt_B'][layer_num] = np.mean(self.middle_res['layer_delt'][layer_num+1], axis=0)
def update_weight(self):
# for convient, compute from input to output dir #
for layer_num in xrange(self.layer_num-1):
self.W[layer_num] -= self.lr * self.middle_res['delt_W'][layer_num]
self.B[layer_num] -= self.lr * self.middle_res['delt_B'][layer_num]
def my_bpnn(self):
self.read_data()
self.initial_weight_parameters()
self.initial_middle_parameters()
iter_num= self.epoch*int(self.train_data.images.shape[0]/self.batch_size)
for i in xrange(iter_num):
batch_x, batch_y = self.train_data.next_batch(self.batch_size)
# 1) compute predict-y
self.forward_propagate(batch_x)
# 2) compute delta-each-layer
self.backward_propagate(batch_y)
# 3) update the par-w-B
self.update_weight()
# 4) training is doing...
if i%100 == 0:
batch_x_prob = self.middle_res['layer_prob'][self.layer_num-1]
test_x_prob = self.compute_output_prob(self.test_data.images)
batch_acc, batch_confMat = self.compute_accuracy_confusionMat(batch_y, batch_x_prob)
test_acc, test_confMat = self.compute_accuracy_confusionMat(self.test_data.labels, test_x_prob)
print ('epoch:', round(i/self.train_data.images.shape[0], 1), 'iter:', i, 'train_batch_accuracy:', batch_acc, 'test_accuracy', test_acc)
def save_middle_res(self, string_head):
handle_w = open(self.middle_res_file, 'aw')
for k, v in self.middle_res.iteritems():
handle_w.write(str(string_head)+'\n')
handle_w.write(str(k)+'\n')
if isinstance(v, list):
num = 0
for i in v:
try: shape = i.shape
except: shape = '0'
handle_w.write('v['+str(num)+'],'+str(shape)+'\n')
handle_w.write(str(i)+'\n')
num +=1
num = 0
for i in self.W:
try: shape = i.shape
except: shape = '0'
handle_w.write('W['+str(num)+'],'+str(shape)+'\n')
handle_w.write(str(i)+'\n')
num +=1
num = 0
for i in self.B:
try: shape = i.shape
except: shape = '0'
handle_w.write('B['+str(num)+'],'+str(shape)+'\n')
handle_w.write(str(i)+'\n')
num +=1
handle_w.close()
def print_para_shape(self):
for k, v in self.middle_res.iteritems():
str_save = ''
if isinstance(v, list):
num = 0
for i in v:
try: shape = i.shape
except: shape = '0'
str_save += str(k) +' v['+str(num)+'],'+str(shape)+'\t|\t'
num +=1
else: str_save = str(k)+':'+str(v)
print (str_save.strip('|\t'))
num = 0; str_save = ''
for i in self.W:
try: shape = i.shape
except: shape = '0'
str_save += 'W['+str(num)+'],'+str(shape)+'\t|\t'
num +=1
print (str_save.strip('|\t'))
num = 0; str_save = ''
for i in self.B:
try: shape = i.shape
except: shape = '0'
str_save += 'B['+str(num)+'],'+str(shape)+'\t|\t'
num +=1
print (str_save.strip('|\t'))
def compute_accuracy_confusionMat(self, real_mat, pred_mat):
pred_label= self.get_label_pred(pred_mat)
real_label= self.get_label_pred(real_mat)
accuracy = metrics.accuracy_score(real_label, pred_label)
confu_mat = metrics.confusion_matrix(real_label, pred_label, np.unique(real_label))
return accuracy, confu_mat
if __name__=='__main__':
CTest = CMyBPNN(hidden_nodes_list=[128], batch_size=100, epoch=100, lr=0.5)
CTest.my_bpnn()
# epoch: 100 iter: 549800 train_batch_accuracy: 0.98 test_accuracy 0.9717 # [100], batch_size=100, lr=0.05 #
# epoch: 3 iter: 201500 train_batch_accuracy: 1.0 test_accuracy 0.9788 # [100], batch_size=100, lr=0.5 #
#CTest = CMyBPNN(hidden_nodes_list=[250, 100], batch_size=150, epoch=50, lr=2.0)
#CTest.my_bpnn() ## 两层以上hidden-layer就不是特别好调了 ##
# epoch: 50 iter: 54900 train_batch_accuracy: 1.0 test_accuracy 0.9796 # [250, 100], batch_size=50, lr==2.0 #














 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









