









一、Ensemble leraing
目录
来源
— 清华大学深研院袁博的数据挖掘课程

1.1 概念
-
集成学习不是一个算法
- Bagging
- Boosting
-
集成学习:

-
重点
- 如何找到C1, C2…这些分类器
- 如何Combiner
1.2 Model Selection

- 对于模型选择:
- 集成学习将三个分类器全选并取平均, 实现较好的分类结果 ---- 不进行模型选择而是集成模型
1.3 Divide and Conquer
- 对于需要模型生成一个较复杂的分界面:

- 集成学习:
- 不由一个模型生成分界面, 而是由多个简单分界面组合成:

二、Bagging
2.1 Bagging原理及步骤
- Bagging是Bootstrap aggregating的缩写。中文意思是自助聚合
-
集成学习Combine方式:
-
Voting
- Majority Voting
- Random Forest
- Weighted Majority Voting
- AdaBoost
- Majority Voting
-
Learning Combiner
- General Combiner (通用集成)
- Stacking
- Piecewise Combiner(分段集成)
- RegionBoost
.
- RegionBoost
- General Combiner (通用集成)
-
No Free Lunch Theorem
没有免费的午餐定理(No Free Lunch Theorem),这个定理说明
若学习算法 L a L_a La在某些问题上比学习算法 L b L_b Lb 要好,
那么必然存在另一些问题,
在这些问题中 L b L_b Lb 比 L a L_a La表现更好。
证明: 机器学习周志华–没有免费的午餐定理 -
集成学习关键点:
- 分类器不同
- 分类器互补
-
注:
- 这里不同可以是模型不同, 也可模型相同训练集不同, 参数不同,或者特征不同
- 多个分类器可以很弱, 弱有好处----快, 不易过拟合, 计算复杂度低---- 例如Stumps
-
训练样本不同的方法(但又服从同一分布)
- Bootstrap(有放回抽样)

- Bootstrap(有放回抽样)
-
Bagging 算法步骤:
 1. 独立训练若干(如50)个分类器
1. 独立训练若干(如50)个分类器
2. 50个投票, 少数服从多数
- 例子

- K个分类器— 少数服从多数
2.2 随机森林
-
很多决策树------组成随机森林
-
Bootstrap中: 1 减去 中样本没被选择 获得大概2/3 被选择------训练集, 其余测试集
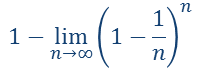
lim m ↦ ∞ ( 1 − 1 m ) m ↦ 1 e ≈ 0.368 \lim _{m \mapsto \infty}\left(1-\frac{1}{m}\right)^{m} \mapsto \frac{1}{e} \approx 0.368 limm↦∞(1−m1)m↦e1≈0.368 -
Bootstrap Aggregation (Bagging)
- Resample with Replacement
- Use around two third of the original data.
→ RF的特点: (为了生成不同的决策树)
- 随机抽样---- 样本训练集不一样
- 决策树根据属性分割----- RF每颗树取部分属性 如原来100属性,取根号100个即 10个属性.

-
树的数量:

-
1/3测试集: —类似交叉验证 —天然分开, 数据充分利用
 oob(Out - of - Bag)
oob(Out - of - Bag)
-
定义:放回取样导致一部分样本很有可能没有取到,这部分样本平均大约有 37% ,把这部分没有取到的样本称为 oob 数据集;
-
根据这种情况,不对数据集进行 train_test_split,也就是不适用 测试数据集,而使用这部分没有取到的样本做测试 / 验证;
-
RF 的优点:

-
总的来说 — 数据利用充分, 精度高, 不易过拟合, 不需要特征选择(已经随机选择100选10个)
三、Stacking和Boosting
3.1 Stacking
- stacking由两层分类器组成, 第二层以第一层的输出为输入, 寻找出一层的权重.

本节的示意图基本引用自xgboost原作者陈天奇的讲义PPT中















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









