







✨ Yumuing 博客
🚀 探索技术的每一个角落,解码世界的每一种可能!
💌 如果你对 AI 充满好奇,欢迎关注博主,订阅专栏,让我们一起开启这段奇妙的旅程!

最近,武汉的萝卜快跑可成了热门话题!你知道吗,萝卜快跑是一款自动驾驶出行服务平台,它在武汉的道路上穿梭,为人们提供着便捷的出行体验。但是,自动驾驶可没那么简单,其中一个关键技术就是新颖视角合成(novel view synthesis)。
就像我们看东西,从不同的角度看会有不同的画面。自动驾驶汽车也需要这样的能力,来更好地理解周围的环境。而今天我们要介绍的这篇论文《WayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving》,就像是给自动驾驶汽车提供了一个超级丰富的“视角库”。
这个“视角库”,也就是WayveScenes101数据集,里面有101个各种各样的驾驶场景,就像萝卜快跑在武汉遇到的不同路况一样。这些场景包含了各种环境条件和驾驶情况,能帮助研究人员更好地训练和测试自动驾驶汽车的新颖视角合成能力。
比如说,在武汉的道路上,可能会有突然出现的行人、快速变化的光线,还有各种复杂的交通情况。这篇论文的数据集就能模拟这些场景,让自动驾驶汽车学会如何准确地重建这些场景,就像我们的眼睛能清晰地看到周围的一切一样。
所以,通过研究这篇论文,我们可以更好地了解如何利用这样的数据集来提升自动驾驶汽车的能力,让萝卜快跑这样的自动驾驶服务变得更加安全和可靠。是不是很有趣呢?接下来,我们就来深入了解一下这篇论文的具体内容吧!
📜 文献卡
| 英文题目: WayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving; |
|---|
| 作者: Jannik Zürn; Paul Gladkov; Sofía Dudas; Fergal Cotter; Sofi Toteva; Jamie Shotton; Vasiliki Simaiaki; Nikhil Mohan |
| DOI: 10.48550/arXiv.2407.08280 |
| 论文摘要 : WayveScenes101是一个旨在帮助社区在新颖的视图合成中推进最先进水平的数据集,专注于具有挑战性的驾驶场景,其中包含许多动态和可变形元素,具有不断变化的几何形状和纹理。该数据集包含101个驾驶场景,涵盖广泛的环境条件和驾驶场景。该数据集旨在对野外驾驶场景的重建进行基准测试,场景重建方法面临许多固有挑战,包括图像眩光、快速曝光变化和具有显着遮挡的高度动态场景。除了原始图像,该数据集包括标准数据格式的COLMAP派生相机姿势。我们提出了一个评估协议,用于评估与训练视图偏离轴的突出相机视图上的模型,特别是测试方法的泛化能力。最后,我们为所有场景提供详细的元数据,包括天气、一天中的时间和交通状况,以允许跨场景特征进行详细的模型性能细分。 |
| GitHub: https://github.com/wayveai/wayve_scenes |
⚙️ 内容
这篇论文主要介绍了WayveScenes101数据集,该数据集旨在帮助研究社区推进新颖视角合成技术的发展,特别是在具有挑战性的驾驶场景中。这些场景包含许多动态和可变形元素,其几何形状和纹理会发生变化。数据集涵盖了101个驾驶场景,跨越了各种环境条件和驾驶场景。
该数据集的设计目的是为了在野外驾驶场景中进行基准测试,其中存在许多对场景重建方法的固有挑战,例如图像眩光、快速曝光变化和高度动态的场景以及大量遮挡。除了原始图像,还包括了从COLMAP衍生的标准数据格式的相机姿态。此外,论文还提出了一种评估协议,用于评估在训练视图之外的离轴相机视图上的模型,专门测试方法的泛化能力。最后,提供了所有场景的详细元数据,包括天气、一天中的时间和交通状况,以便对模型性能进行详细的场景特征分析。
💡 创新
- 专注驾驶场景:以往许多用于新颖视角合成的数据集要么专注于合成场景或对象中心场景,对驾驶场景的适用性有限。而WayveScenes101数据集专门针对驾驶场景,能更好地应对自动驾驶中实际遇到的挑战。
- 全面的场景信息:提供了丰富的场景元数据,包括天气、时间、交通状况等,这使得可以对模型在不同场景特征下的性能进行详细分析,有助于更精准地优化模型。
- 独特的相机设置和评估协议:相机RIG的设计和使用前向相机进行离轴重建质量评估的协议,能够更准确地评估模型的泛化能力,对场景几何形状的高精度建模提出了要求,有助于推动模型在实际应用中的性能提升。
🧩 不足
- 数据规模相对较小:虽然WayveScenes101数据集包含了101个场景,但与一些大规模的自动驾驶数据集相比,数据规模可能相对较小。在面对复杂多变的自动驾驶环境时,可能需要更大规模的数据来训练出更稳健的模型。
- 场景多样性的拓展:尽管数据集涵盖了一定范围的环境条件和驾驶场景,但未来可能需要进一步拓展场景的多样性,以涵盖更多极端或罕见的情况,从而更好地应对各种突发状况。
- 对动态元素的处理挑战:虽然数据集包含了动态和可变形元素,但目前的技术在准确重建这些元素方面仍然面临挑战,需要进一步研究和改进算法来提高对动态元素的处理能力。
🔁 实验卡
💧 数据
- 数据来源:WayveScenes101数据集的101个场景来自各种驾驶环境,如城市、郊区和高速公路,涵盖了不同的天气和光照条件。
- 数据组成:每个20秒的场景包括来自五个车辆安装相机的时间同步视图和相关的相机姿态,这些相机姿态是从COLMAP获得的。此外,还为每个图像提供了掩码,指示不应用于场景重建的图像区域(如模糊的面孔、车牌和自我车辆掩码)。以下为该数据集的关键组成:
- 101 种高度多样化的驾驶场景,每个场景 20 秒
- 101,000 张图像(101 个场景 x 5 台摄像机 x 20 秒 x 每秒 10 帧)
- 场景录制地点:美国和英国
- 5 个时间同步摄像机
- 用于离轴重建测量的独立评估相机
- 用于细粒度模型评估的场景级属性
- 与 NerfStudio 框架轻松集成
- 数据特点:数据集的场景选择具有代表性,旨在反映在现实世界中部署新颖视角合成方法时面临的挑战,例如动态变化的交通灯、太阳眩光或移动的行人等。同时,提供了详细的场景元数据,如天气、时间、交通状况等,以便进行定制化的模型评估。以下为该数据集的主要特点:
- 天气:晴、多云、阴、雨、雾
- 道路类型:公路、城市、住宅、农村、道路工程
- 一天中的时间:白天,太阳低下,晚上
- 动态智能体:车辆、行人、骑自行车的人、动物
- 动态照明:交通信号灯、曝光变化、镜头眩光、反射
- 下载地址: Google Drive 上提供了WayveScenes101 数据集。您可以决定下载所有提供的场景,也可以仅下载其中的一部分。
👩🏻💻 实现
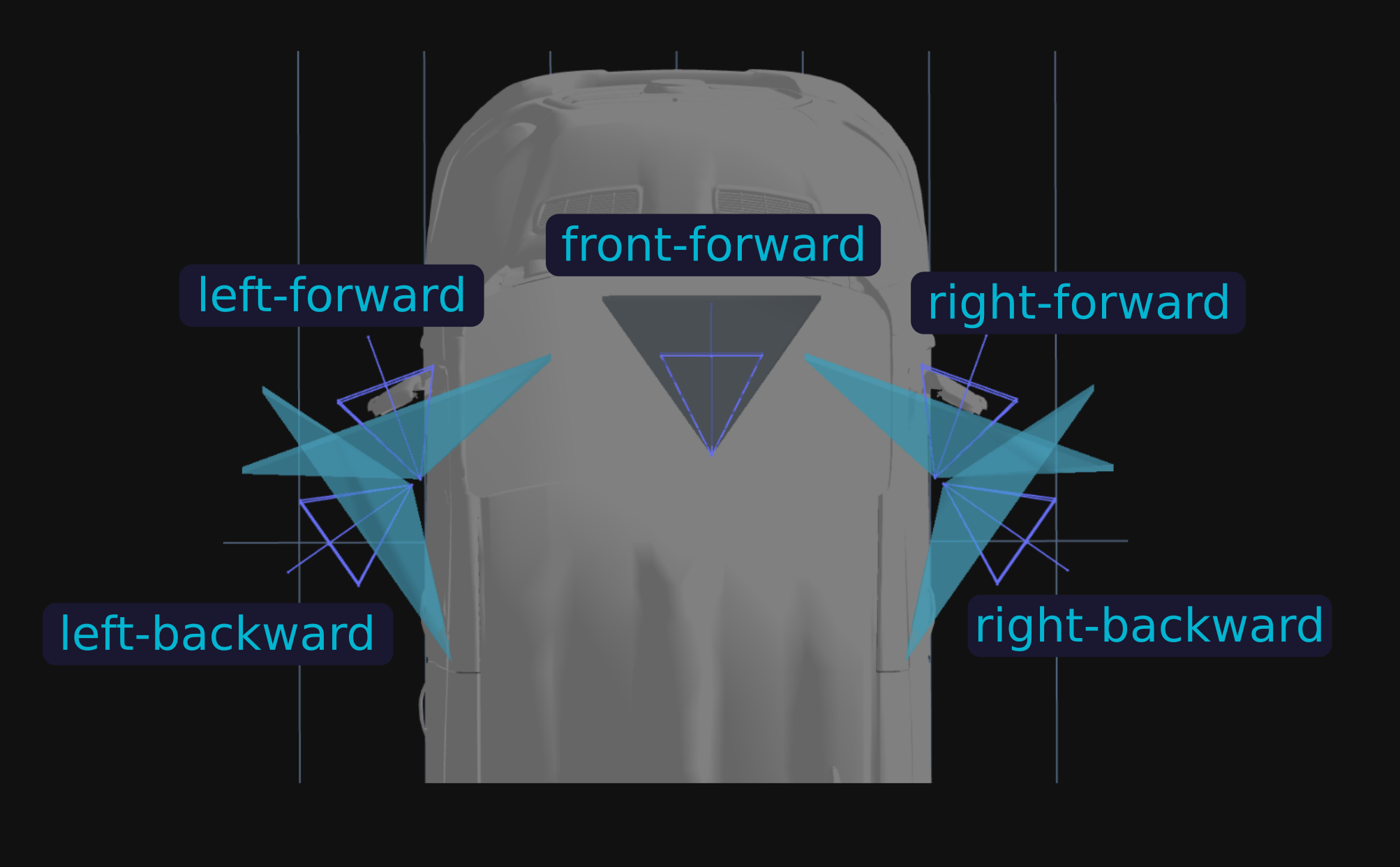
相机RIG设计:相机RIG由四个广角相机(左后、左前、右前、右后)和一个中心前向相机(前向)组成,前向相机的视野较小。相机参数如下:
| ff(前向) | 左前 (lf)、右前 (rf)、左后 (lb) 和右后 (rb) | |
|---|---|---|
| 分辨率 | 1920x1080 | 1920x1080 |
| Nominal H - FOV | 70° | 120° |
📜 结论
WayveScenes101数据集在一些方面具有独特的优势,例如专门设计了离轴测试相机来评估模型的泛化能力,并且提供了详细的场景元数据,用于定制评估特定科学中的新型视图合成模型,即下雨的场景、完全静态的场景或夜间场景。此元数据可用于计算特定场景类型的特定模型性能指标。此外,每个场景时长为20秒,包含来自五个车辆安装相机的时间同步视图和相关相机姿态,还提供了图像区域的掩码。并且选择的场景具有代表性,能反映实际部署novel view synthesis方法时面临的挑战,如动态变化的交通灯、太阳眩光或移动的行人等。
| 数据集名称 | 发布年份 | 场景数量 | 场景定义 | 图像数量 | RGB 相机数量 | COLMAP 姿势信息 | 离轴测试相机 | 场景元数据 | 场景位置 |
|---|---|---|---|---|---|---|---|---|---|
| KITTI | 2012 | 22 个 | 各不相同 | 15000 张 | 2 个 | 无 | 无 | 无 | 德国卡尔斯鲁厄 |
| KITTI - 360 | 2021 | 11 个 | 各不相同 | 300000 张 | 4 个 | 无 | 无 | 无 | 德国卡尔斯鲁厄 |
| Waymo Open | 2019 | 1150 个 | 每个场景 20 秒 | 1000000 张 | 5 个 | 无 | 无 | 无 | 美国 |
| nuScenes | 2019 | 1000 个 | 每个场景 20 秒 | 1400000 张 | 6 个 | 无 | 无 | 无 | 波士顿、新加坡 |
| Argoverse | 2019 | 113 个 | 15 - 30 米 | 490000 张 | 9 个 | 无 | 无 | 无 | 美国多个城市(奥斯汀、底特律、迈阿密、帕洛阿尔托、匹兹堡和华盛顿特区) |
| WayveScenes101 | 2024 | 101 个 | 每个场景 20 秒 | 101000 张 | 5 个 | 有 | 有 | 有 | 伦敦、旧金山湾区 |
评估指标:
使用峰值信噪比(PSNR)、结构相似性指数测量(SSIM)、学习感知图像块相似性(LPIPS)和弗雷切特初始距离(FID)来量化模型性能。对于PSNR、SSIM和LPIPS指标,针对所有图像分别计算,对于给定场景S,指标M通过公式 M S = 1 ∣ S ∣ ∑ I m a g e ∈ S M I m a g e M_{S}=\frac{1}{|S|}\sum_{Image\in S}M_{Image} MS=∣S∣1∑Image∈SMImage进行平均。对于整个数据集D,指标通过对所有场景S进行平均计算,每个场景具有相同权重,即 M D = 1 ∣ D ∣ ∑ S ∈ D M S M_{\mathcal{D}}=\frac{1}{|\mathcal{D}|}\sum_{S\in\mathcal{D}}M_{S} MD=∣D∣1∑S∈DMS。FID指标在一个场景中对所有预测和真实图像进行一次计算,因为它比较的是图像分布而不是单个图像。根据提出的离轴评估相机(前向),指标可以分为训练指标(不包括前向相机在S中)和测试指标(仅包括前向相机在S中)。还可以针对特定场景子集进行评估,如所有夜间场景或仅完全静态场景,通过从给定子集 { S i } ⊂ D \{S_{i}\}\subset\mathcal{D} {Si}⊂D中采样S,并对 S i {S_{i}} Si中的场景数量进行平均。
🤔 总结卡
👍 论文优点
- 针对性强:专门针对自动驾驶中的新颖视角合成任务设计数据集,解决了现有数据集在驾驶场景适用性方面的不足。
- 数据丰富:提供了大量的驾驶场景图像和相关的相机姿态信息,以及详细的场景元数据,为深入研究提供了丰富的数据支持。
- 评估全面:提出了一套全面的评估指标和协议,能够更准确地评估模型在不同场景下的性能和泛化能力。
🎓 方法创新
- 数据集设计创新:WayveScenes101数据集的设计考虑了自动驾驶中实际遇到的各种挑战,为研究提供了更真实的场景。
- 相机rig和评估协议创新:相机rig的独特设计和使用前向相机进行离轴重建质量评估的协议,能够更好地评估模型对场景几何形状的建模能力和泛化能力。
⌚ 未来展望
- 数据扩展:未来可以进一步扩大数据集的规模,增加更多的场景和数据,以提高模型的训练效果和泛化能力。
- 技术改进:针对目前在处理动态和可变形元素方面的挑战,需要进一步研究和改进相关算法,提高模型对这些元素的重建准确性。
- 多模态融合:可以考虑融合其他传感器的数据,如激光雷达等,以提供更全面的环境信息,提高自动驾驶的安全性和可靠性。
- 应用拓展:除了在自动驾驶中的应用,可以探索该数据集在其他领域的应用,如智能交通系统、城市规划等。
💭 思考启发
🎯利用WayveScenes101数据集如何应对自动驾驶中动态和可变形物体的重建挑战?
- 场景选择:在选择场景时,考虑包含各种交通状况和行人活动的场景,以确保数据集中包含这些动态和可变形物体的信息。例如,选择具有动态变化的交通灯、太阳眩光或移动行人的场景,这些场景能代表实际驾驶中遇到的挑战。
- 数据提供:数据集提供了大量的驾驶场景图像和相关的相机姿态信息,这些信息有助于模型学习和重建动态和可变形物体。通过从多个角度拍摄同一场景,模型可以更好地理解物体的几何形状和运动模式。
- 技术应用:可能采用先进的机器学习技术和算法,来提高对动态和可变形物体的重建准确性。例如,使用深度学习模型来学习物体的特征和行为模式,从而能够更准确地预测它们在不同场景中的表现。
💡利用WayveScenes101数据集在处理驾驶场景中的动态光照条件方面有哪些措施?
- 数据记录:数据集记录了驾驶场景中出现的镜头眩光、反射和快速相机曝光变化等动态光照条件的信息。通过车辆安装的相机,能够捕捉到这些光照变化的瞬间,为后续的处理和分析提供了原始数据。
- 图像处理:可能使用一些图像处理技术和算法,来应对这些光照变化。例如,采用图像增强技术来改善在眩光或低光照条件下的图像质量,使物体的特征更加清晰可辨。
- 场景元数据利用:数据集提供的场景元数据,如天气和时间信息,有助于理解光照条件的背景。在处理数据时,可以根据这些元数据对图像进行分类和分析,从而更好地应对不同光照条件下的挑战。
📷WayveScenes101数据集的相机RIG设计如何影响数据采集和novel view synthesis?
- 数据采集:相机RIG由四个广角相机(左后、左前、右前、右后)和一个中心前向相机(前向)组成。这种设计能够从多个角度捕捉驾驶场景的信息,提供更全面的场景视角。不同相机的参数设置,如分辨率和视野角度,有助于获取高质量的图像数据。
- novel view synthesis:前向相机与侧向前向相机有完整的视锥重叠,但保持了较大的基线距离(约0.9米和约1.2米)。这要求场景重建模型必须高精度地建模场景几何形状,以考虑在评估相机上的视角变化。这种设计能够更准确地评估模型对场景几何形状的建模能力和泛化能力,从而推动novel view synthesis在实际应用中的性能提升。
📝如何利用WayveScenes101数据集来推进novel view synthesis在自动驾驶领域的发展?
- 利用该数据集进行模型训练和评估,以提高novel view synthesis模型在自动驾驶场景中的性能,特别是针对驾驶场景中的各种挑战,如动态和变形物体的重建、动态照明条件的处理以及遮挡情况下的重建。
- 结合数据集提供的场景多样性和详细元数据,优化模型对各种复杂驾驶环境的适应能力,例如根据不同的天气、时间、交通条件等元数据进行针对性的训练和评估。
- 基于该数据集开展进一步的研究,探索新的算法和技术,以更好地解决自动驾驶中novel view synthesis面临的问题,例如开发更有效的模型来处理动态对象和光照变化。
- 利用该数据集生成的合成数据,可用于评估驾驶模型在模拟中的表现,以及为驾驶模型的训练提供更多的数据支持。
















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











