






1
分类问题
在分类问题中,我们尝试预测的是结果是否属于某一个类(例如正确或错误)。分类问
题的例子有:判断一封电子邮件是否是垃圾邮件;判断一次金融交易是否是欺诈等等。
我们从二元的分类问题开始讨论。 我们将因变量
可能属于的两个类分别称为负向类
和 正向类,则因变量
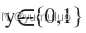 其中
0
表示负向类,
1
表示正向类。
其中
0
表示负向类,
1
表示正向类。
2
假说表示
回顾在一开始提到的乳腺癌分类问题,我们可以用线性回归的方法求出适合数据的一条
直线:

根据线性回归模型我们只能预测连续的值,然而对于分类问题,我们需要输出
0
或
1
,
我们可以预测:
1.当
h
θ
大于等于
0.5
时,预测
y=1
2.当
h
θ
小于
0.5
时,预测
y=0
对于上图所示的数据,这样的一个线性模型似乎能很好地
完成分类任务。假使我们又观测到一个非常大尺寸的恶性肿瘤,将其作为实例加入到我们的
训练集中来,这将使得我们获得一条新的直线。
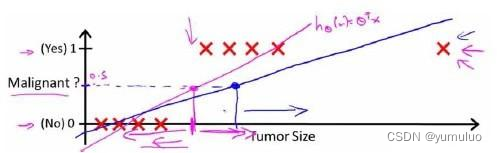
这时,再使用 0.5 作为阀值来预测肿瘤是良性还是恶性便不合适了。可以看出,线性回 归模型,因为其预测的值可以超越[0,1]的范围,并不适合解决这样的问题。
我们引入一个新的模型,逻辑回归,该模型的输出变量范围始终在 0 和 1 之间。 逻辑 回归模型的假设是:hθ(x)=g(θTX) 其中: X 代表特征向量 g 代表逻辑函数是一个常用的逻辑函数为 S 形函数,公式为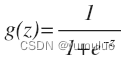
该函数的图像为:
合起来,我们得到逻辑回归模型的假设:
对模型的理解:
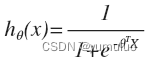
h
θ
(x)
的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1 的可能性即
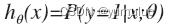
例如,如果对于给定的
x
,通过已经确定的参数计算得出
h
θ
(x)=0.7
,则表示有
70%
的几
率
y
为正向类,相应地
y
为负向类的几率为
1-0.7=0.3















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









