






简化的成本函数和梯度下降
多类分类问题中,我们的训练集中有多个类(
>2
),我们无法仅仅用一个二元变量(
0
或
1
) 来做判断依据。例如我们要预测天气情况分四种类型:晴天、多云、下雨或下雪。
下面是一个多类分类问题可能的情况:

一种解决这类问题的途径是采用一对多
方法。在一对多方法中,我们将多 类分类问题转化成二元分类问题。 为了能实现这样的转变,我们将多个类中的一个类标记为正向类(y=1),然后将其他
所有类都标记为负向类,这个模型记作
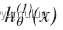
接着,类似地第我们选择另一个类标记为 正向类(y=2),再将其它类都标记为负向类,将这个模型记作
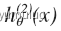
依此类推。 最后我们得到一系列的模型简记为:
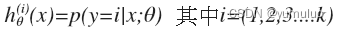

最后,在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,
都选择最高可能性的输出变量。
多类分类:一个对所有

"""Add polynomial features to the features set"""
import numpy as np
from .normalize import normalize
def generate_polynomials(dataset, polynomial_degree, normalize_data=False):
"""变换方法:
x1, x2, x1^2, x2^2, x1*x2, x1*x2^2, etc.
"""
features_split = np.array_split(dataset, 2, axis=1)
dataset_1 = features_split[0]
dataset_2 = features_split[1]
(num_examples_1, num_features_1) = dataset_1.shape
(num_examples_2, num_features_2) = dataset_2.shape
if num_examples_1 != num_examples_2:
raise ValueError('Can not generate polynomials for two sets with different number of rows')
if num_features_1 == 0 and num_features_2 == 0:
raise ValueError('Can not generate polynomials for two sets with no columns')
if num_features_1 == 0:
dataset_1 = dataset_2
elif num_features_2 == 0:
dataset_2 = dataset_1
num_features = num_features_1 if num_features_1 < num_examples_2 else num_features_2
dataset_1 = dataset_1[:, :num_features]
dataset_2 = dataset_2[:, :num_features]
polynomials = np.empty((num_examples_1, 0))
for i in range(1, polynomial_degree + 1):
for j in range(i + 1):
polynomial_feature = (dataset_1 ** (i - j)) * (dataset_2 ** j)
polynomials = np.concatenate((polynomials, polynomial_feature), axis=1)
if normalize_data:
polynomials = normalize(polynomials)[0]
return polynomials















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









