







 本文介绍如何利用牛顿法而非梯度上升法来求解逻辑斯谛回归的最佳参数。通过牛顿法,通常只需迭代10次左右即可达到收敛,相比梯度上升法效率更高。文章详细阐述了牛顿法的原理和逻辑斯谛回归的参数更新规则,并提供了测试数据集的实验结果。
本文介绍如何利用牛顿法而非梯度上升法来求解逻辑斯谛回归的最佳参数。通过牛顿法,通常只需迭代10次左右即可达到收敛,相比梯度上升法效率更高。文章详细阐述了牛顿法的原理和逻辑斯谛回归的参数更新规则,并提供了测试数据集的实验结果。
逻辑斯谛回归
关于逻辑斯谛回归,这篇文章http://blog.csdn.net/zouxy09/article/details/20319673 讲的很好;Andrew Ng的机器学习公开课也很不错(中文笔记也很好http://blog.csdn.net/stdcoutzyx );还有《机器学习实战》,都是不错资料。
在逻辑斯谛回归中,因为使用梯度上升(gradient ascent)收敛较慢,固本文采用牛顿法(Newton’s Method)进行参数求解,试验发现通常迭代10次左右就可达到收敛,而梯度上升法则需要迭代上百甚至上千次,当然实际的迭代次数也要视实际数据而定。
牛顿法
牛顿法与梯度下降法的功能一样,都是最优化的常用方法。
对于一个函数,如果要求函数值为0时的值,如图所示:
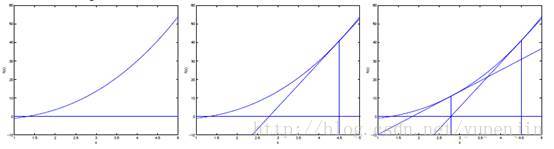
先随机选一个点,然后求出该点的切线,即导数,延长切线与横轴相交,以相交时的的值作为下一次迭代的值,更新规则如下

对于逻辑斯谛回归,需要求的是似然函数L(θ)的最大值,当L(θ)的导数L’(θ)为0时即为L(θ)的最大值,即求L’(θ)=0的参数,则可使用牛顿法进行求解,此时参数更新规则为
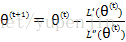
使用牛顿法的另一个好处是不需要像梯度法一样指定学习率(即步长)。但是牛顿法需要对二阶导(Hessian矩阵)进行求逆,不过随着拟牛顿法(BFGS)以及限域拟牛顿法(LBFGS)的提出,大大减少了求逆的计算量,不过在本文还是使用牛顿法进行参数求解。
牛顿法求解逻辑斯谛回归参数
迭代中需要进行的主要步骤包括如下:
(1) 初始化参数θ
(2) 获取数据x
(3) 对数据进行预测h
(4) 得到对数似然函数L(θ)
(5) 根据L(θ)计算梯度g
(6) 根据L(θ)计算Hessian矩阵H
(7) 更新参数θ
具体计算
(1) 初始化θ=(b, θ(1), θ(2), …, θ(n))T,初始时θ=(0, 0, 0, …, 0)T
(2) 获取x=(1, x(1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









