







大家好,我是东哥。
本篇来介绍风控模型中KS评估指标,包括KS的定义、计算步骤、应用标准、上线后效果评估、以及Python代码实操,内容节选自👉《100天风控专家》评分卡模型篇。
1. 什么是KS?
KS(Kolmogorov-Smirnov)统计量由两位苏联数学家A.N.Kolmogorov和N.V.Smirnov提出。
在风控中,KS常用于评估模型或者变量的区分度,业内通用的定义为:好坏客户累积分布差异的最大值。
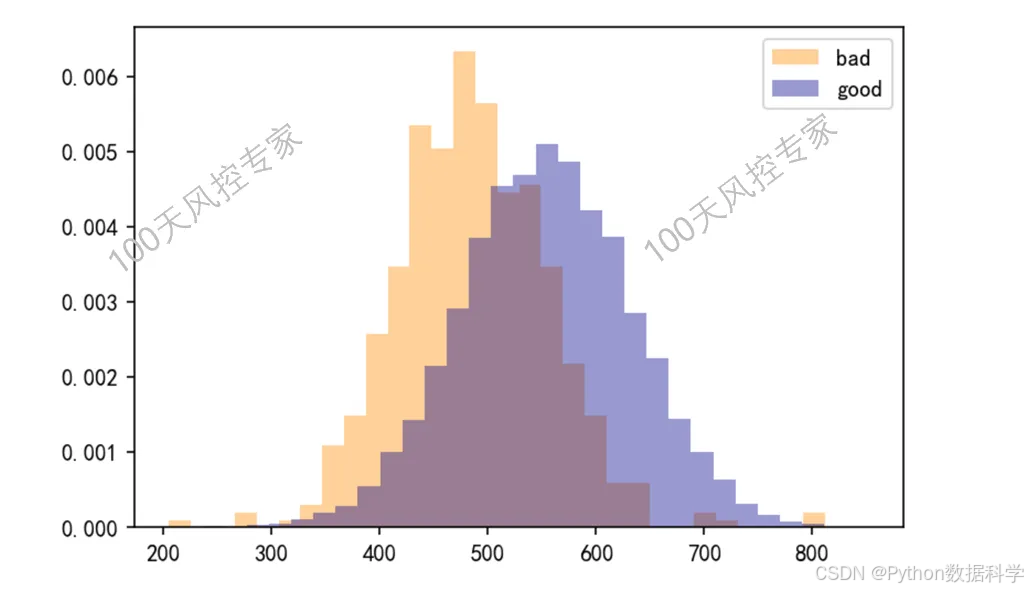
2. KS计算步骤
具体计算步骤如下:
①变量分箱,可以选择等频、等距、决策树或者自定义均可
②计算每个分箱区间的好客户数(good_count)和坏客户数(bad_count)
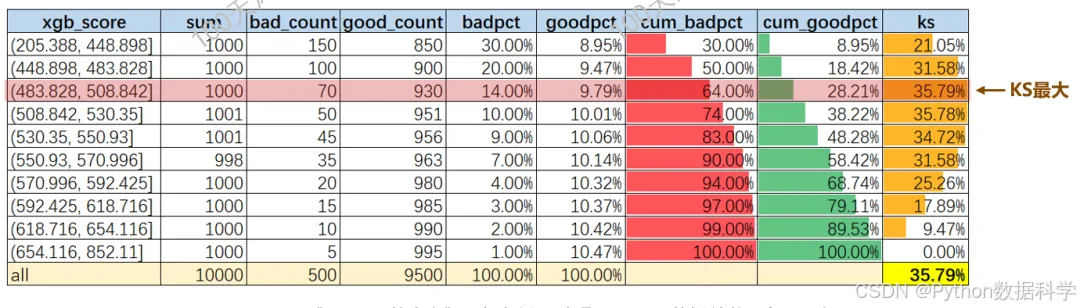
③计算每个分箱区间的好/坏客户占比(goodpct/badpct)、累计好/坏客户数占比(cum_goodpct/cum_badpct)
④计算每个分箱区间累计好/坏客户数占比差的绝对值,得到KS
⑤在所有分箱的KS中取最大值,得到该变量最终的KS值
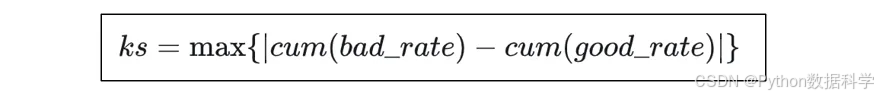
3. KS应用和评估标准
1)应用对象
KS指标可以应用在模型或规则上,一般用于模型上较多,规则上通常看Lift提升度。
当应用于模型时,KS可以辅助设定cutoff阈值。理论上可以将分箱的KS最大值对应的取值作为cutoff,但实际还需要考虑对通过率的影响,二者之间做个平衡,所以一般不一定会设置在理想值。
2)评估标准
KS的取值范围是[0,1],可以用小数或者以%形式的表示,比如KS=0.3或者30%。通常来说,KS越大代表好坏客户的区分度越高。具体多少算高要看使用场景,就贷前/中/后的模型来说,KS也有不同的衡量标准。
贷前A卡模型通常KS大于0.3就视为有较强的区分度了,但一般至少要求0.2以上,0.2以下不建议使用;贷中B卡模型的KS一般要求大于0.4以上;贷后C卡模型的KS一般要求大于0.5以上。如果是子模型或者单一维度模型,可以适当下降标准。
另外如果KS值高的离谱,比如贷前A卡模型高于50以上,需要怀疑模型是否存在过拟合,或者数据泄露。
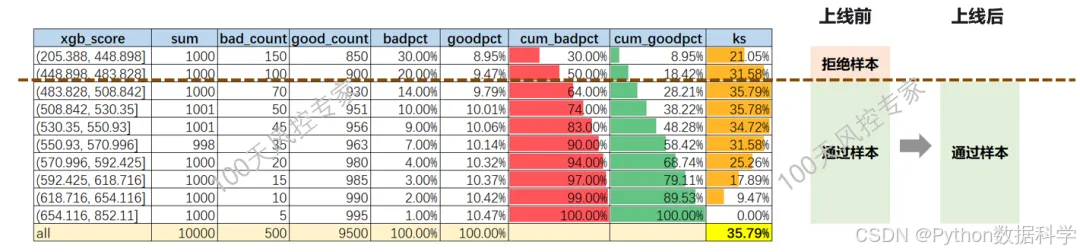
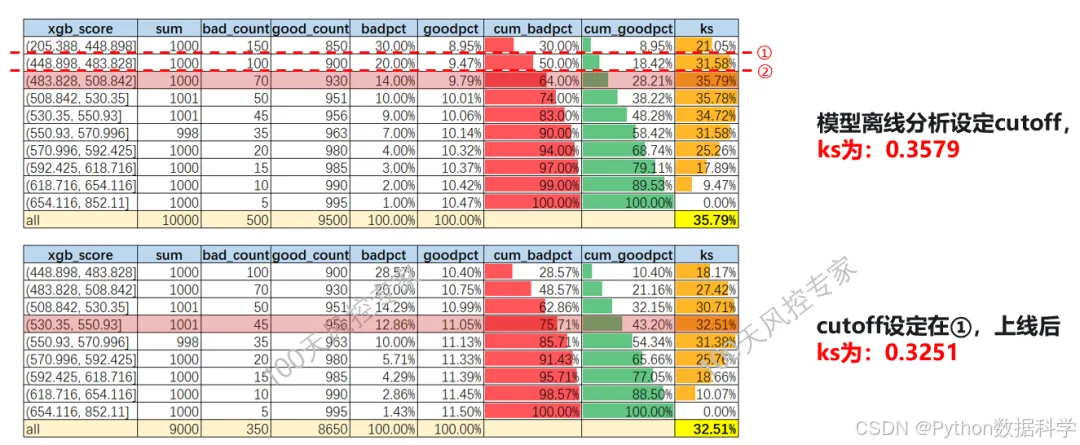
4. 模型上线后KS评估
模型上线后KS一定下降,这属于正常现象。
① 为什么KS会下降?
由于模型上线后只能观测到“通过的样本”来计算KS,相对于离线分析的整体样本而言(通过和拒绝样本)是缺少了拒绝样本的,也就是上线前后统计的样本分布是发生了变化的,这就导致了KS值的不同。
那具体下降的原因是什么?原因在于,拒绝样本的坏客户浓度高于通过样本的坏客户浓度。离线分析时,因为拒绝样本坏客户浓度高时,好坏的区分相对更简单,也就导致KS会更高。而一旦拒绝样本不在了(在线上被拒掉了),好坏的区分能力也就下降了。
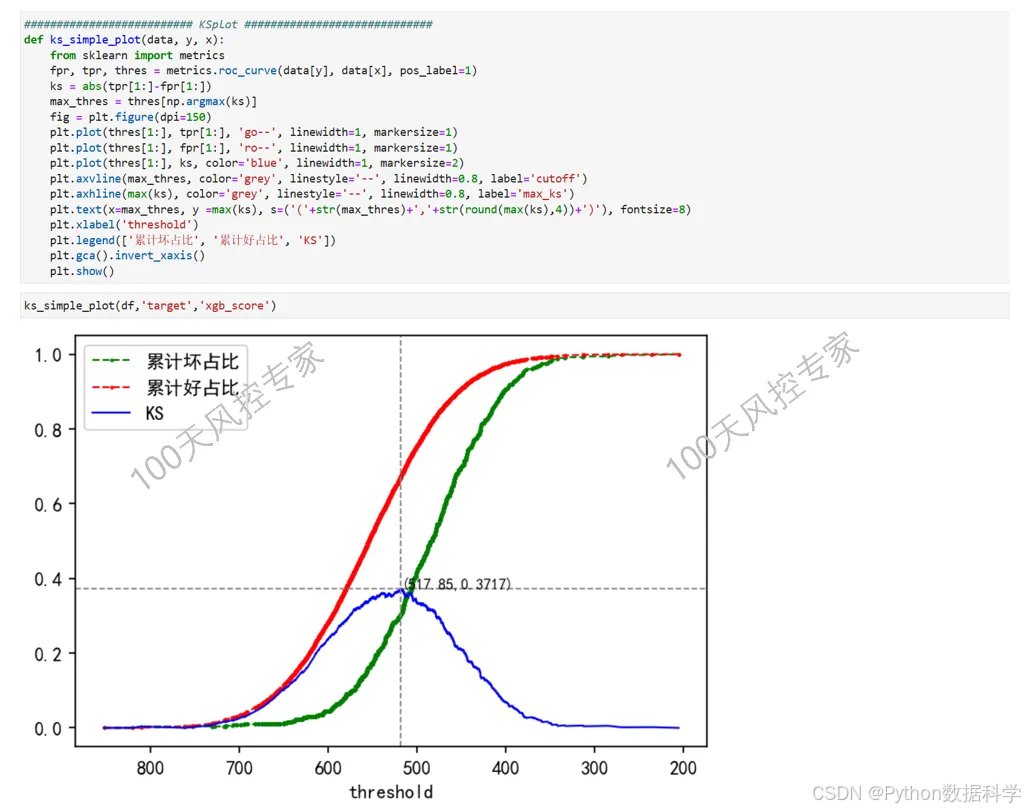
5. KS计算的Python代码

感兴趣可VX搜:100天风控专家
或者👉《100天风控专家》

















 9035
9035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









