







目录
1、前言
作为第一个练手的题目,代码规范上有很多不清楚的地方,参考了好多其他大佬的分析流程和代码,在此做一下记录。
目前为止学过的(或者还在学)的网课:
小甲鱼python课程:link1
小土堆深度学习快速入门课程:link2
李宏毅机器学习课程:link3
李沐动手学深度学习课程:link4
李沐的书:link5
2、问题描述
这是Kaggle上的一个经典问题了,loss已经被人刷到0了。训练集给出了房屋的各种属性,比如:装修水平、建造日期、地段、地皮面积等,同时给出了房屋的售价;测试集则是只给出了房屋的各种属性。我们要做的就是根据训练集数据训练模型,并通过模型预测测试集中房屋的售价会是多少。
Kaggle链接:link6
3、代码实作
3.1 导入数据
3.1.1 导入需要的模块
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
3.1.2 导入数据
# 导入数据集
data_train = pd.read_csv(r'./house-prices-advanced-regression-techniques/train.csv')
data_test = pd.read_csv(r'./house-prices-advanced-regression-techniques/test.csv')
# 查看训练数据(前5行数据)
data_train.head()
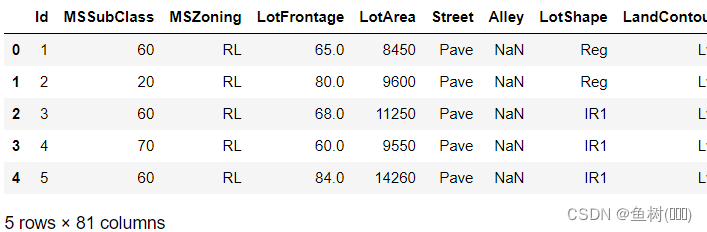
可以看到这里训练集数据一共有81列,也就是说一共有80个特征(features),其中最后一列为房价也就是测试集中我们需要预测的(labels)。
3.2 查看各项主要特征与房屋售价的关系
这里我主要是练习一下数据分析的一些常用方法,并没有对数据进行修改
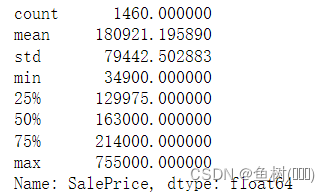
3.2.1 查看房屋售价统计信息
data_train['SalePrice'].describe()
3.2.2 查看缺失值
data_train.isnull().sum()
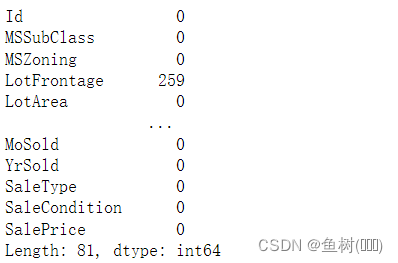
查看缺失值信息可以对数据集的缺失情况有一定的了解,同时根据具体数据的情况决定对缺失数据的处理方案,我现在了解的有三种:对于数据缺失比较严重的特征,可以将该特征直接舍弃;将平均值作为缺失的数据填入;对于较连续的数据可以将插值填入
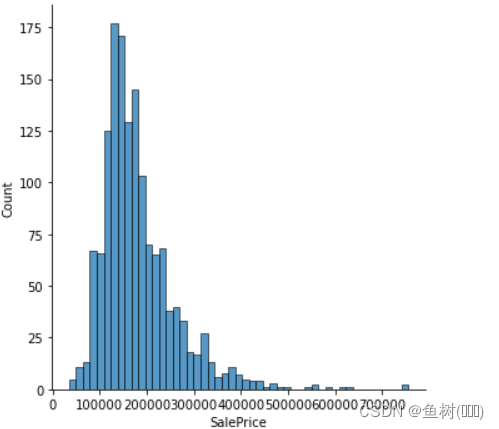
3.2.3 查看房屋售价的分布
sns.displot(data_train['SalePrice'])
plt.show()
3.2.4 查看生活面积与房价的关系
data = pd.concat([data_train['SalePrice'], data_train['GrLivArea']], axis=1)
data.plot.scatter(x='GrLivArea', y='SalePrice', ylim=(0, 800000))
plt.show()

绘制生活面积与房屋售价的关系我们就可以看出有些数据是不太合理的,绝大多数都是生活面积越大,房屋售价越贵,但是x=5000左右时出现两个点不符合实际情况,生活面积较大而房屋售价反而很低,这样的数据是不利于整体预测的,实作时需要去除。其他特征数据的分析应该类似。
3.2.5 查看数据之间的关联性
corramt = data_train.corr()
f, ax =plt.subplots(figsize=(20, 9))
sns.heatmap(corramt, vmax=0.8, square=True)
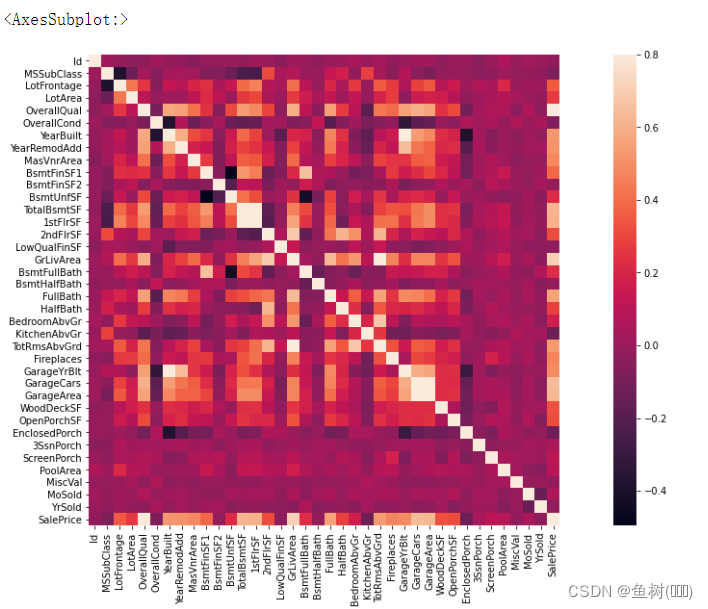
查看与房屋售价关联性较强的数据之间的关联,当数据特征数量非常庞大而模型复杂程度(计算资源)有限时,我们可以只选择关联性较强的特征进行训练
cols = corramt.nlargest(10, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(data_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, \
square=True, fmt='.2f', \
annot_kws={'size':10}, \
yticklabels=cols.values, \
xticklabels=cols.values)
plt.show()
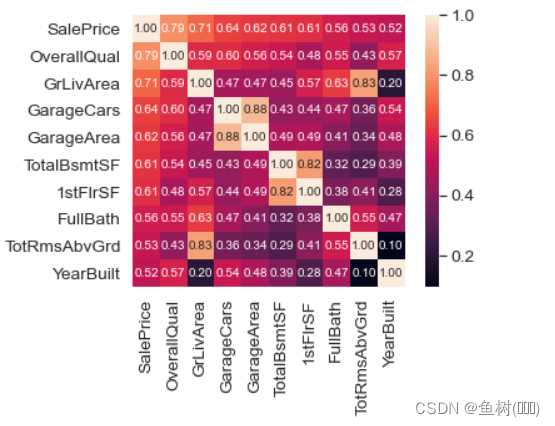
3.3 数据预处理
all_featues = pd.concat([data_train.iloc[:,1:-1], data_test.iloc[:,1:]], axis=0)
display(all_featues.head())
all_featues.info()
这里先将训练集和测试集数据合并到一起进行处理,之后在根据数量进行划分。对于第一列的“Id”信息,在训练时肯定是没有什么作用的,所以从第二列开始合并;训练集最后一列是房价信息,这一列将作为labels来计算loss,所以不将训练集最后一列合并进去。
3.3.1 对连续的特征做标准化
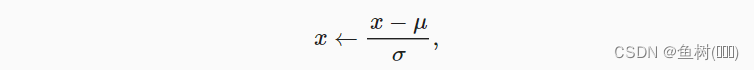
numeric_features = all_featues.dtypes[all_featues.dtypes != 'object'].index
all_featues[numeric_features] = all_featues[numeric_features].apply(
lambda x:(x - x.mean())/(x.std()))
all_featues = all_featues.fillna(0)
根据均值和方差将所有数值型数据缩放到0均值和单位方差(这是因为不同特征的数据值之间的差别较大,比如有些特征可能平均是3000而有些可能平均是3,在模型训练时可能导致有些特征的影响效果不那么明显,这里将不同特征拉到差不多的尺度),那么每列数据的均值就是0,之后用0填充空值位置即可
3.3.2 对离散的特征替换成独热点码
all_featues = pd.get_dummies(all_featues, dummy_na=True)
all_featues.shape
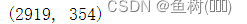
转为独热点码是处理离散的特征一种常用的方法,这样一来,文本类的特征也能作为数值类型传入模型进行训练,比如空调情况可能是Y和N两个文本,转为独热点码后,有空调的房屋的特征是(Y:1,N:0),无空调的房屋特征是(Y:0,N:1),当然了,这样会导致特征数量膨胀很多,这里就由原本的80个特征增加到了354个,同样的,在资源有限的情况下,我们可以只选择相对重要的特征进行处理。
3.3.3 转成tensor格式数据
n_train = data_train.shape[0]
train_features = torch.tensor(all_featues[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_featues[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(data_train.SalePrice.values.reshape(-1,1), dtype=torch.float32)
3.4 网络模型
def get_net(num_features):
'''
输入特征数量,返回网络模型
'''
ret_net = nn.Sequential(
nn.Linear(num_features, 64),
nn.ReLU(),
nn.Linear(64, 1))
return ret_net
模型的复杂程度是要与数据集的复杂程度相匹配的,这里数据集并不算复杂数据集,所以简单的线性层即可。
3.5 损失函数
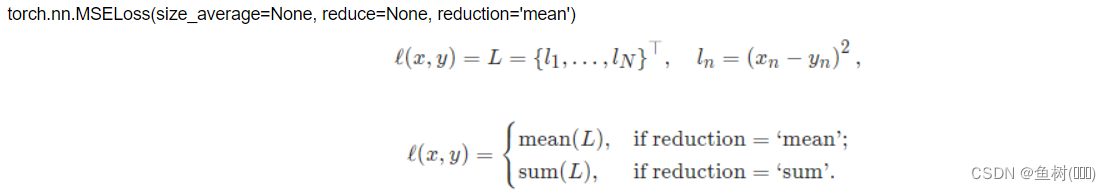
loss = nn.MSELoss()
3.6 评价函数
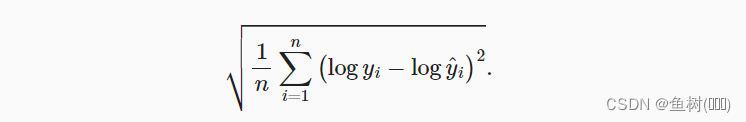
def log_rmse(net, features, labels):
'''
对数均方根误差来衡量差异
'''
with torch.no_grad():
# 小于1的值设为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
ret_rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return ret_rmse.item()
这里没有用MSELoss()计算的结果直接作为误差是因为,在做房价预测这个问题时,我们关注的更多的是相对误差而非绝对误差,可能A地的房价平均在10万元,那么1万元的差别就是很大的了;同样的1万元在房价平均100万元的B地却算很小的误差,所以在误差的评价时,我们另外定义一个评价函数均方根误差来评价误差的大小
3.7 训练函数
def train(net, train_features, train_labels, test_features,
test_labels, num_epochs, learning_rate,
weight_decay, batch_size):
'''
给定训练、测试数据,进行num_epochs轮的训练
'''
train_ls, test_ls = [], []
dataset = TensorDataset(train_features, train_labels)
train_iter = DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate, weight_decay=weight_decay)
net.train()
for epoch in range(num_epochs):
for x, y in train_iter:
optimizer.zero_grad()
l = loss(net(x), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
3.8 K折交叉验证
def get_k_fold_data(k, i, x, y):
'''
返回k折数据中的第i折
'''
fold_size = x.shape[0] // k
x_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
x_part, y_part = x[idx,:], y[idx]
if j == i:
x_valid, y_valid = x_part, y_part
elif x_train is None:
x_train, y_train = x_part, y_part
else:
x_train = torch.cat((x_train, x_part), dim=0)
y_train = torch.cat((y_train, y_part), dim=0)
return x_train, y_train, x_valid, y_valid
def k_fold(k, x_train, y_train, num_epochs, learning_rate,
weight_decay, batch_size):
'''
K折交叉验证训练
'''
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, x_train, y_train)
net = get_net(x_train.shape[1])
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
print(f'{i+1}折,训练 rmse:{float(train_ls[-1]):f},'
f'验证 rmse:{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
K折交叉验证,有助于模型的选择和超参数的调整,比如将训练集分成5等份,第一次将第一份作为验证集,其余4份作为训练用;第二次将第二份作为验证集,其余4份作为训练用…
3.9 训练
k = 5
num_epochs = 500
lr = 0.01
weight_decay = 0.1
batch_size = 256
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs,
lr, weight_decay, batch_size)
print(f'{k}-折交叉验证:平均训练 rmse:{float(train_l):f},'
f'平均验证 rmse:{float(valid_l):f}')

通过训练确定效果较好的那些超参数
3.10 预测
使用刚才确定的超参数,不划分验证集,将所有的训练集数据全部用来训练,得到用于预测的模型
def train_and_pred(train_features, test_features, train_labels,
data_test, num_epochs, lr, weight_decay, batch_size):
net = get_net(train_features.shape[1])
train_ls, _ = train(net, train_features, train_labels,
None, None, num_epochs, lr,
weight_decay, batch_size)
print(f'训练 rmse:{float(train_ls[-1]):f}')
preds = net(test_features).detach().numpy()
data_test['SalePrice'] = pd.Series(preds.reshape(1,-1)[0])
submission = pd.concat([data_test['Id'], data_test['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels,
data_test, num_epochs, lr, weight_decay, batch_size)

3.11 提交

4、总结
大部分参考了李沐《动手学深度学习》那本书中的代码,对模型训练的基本流程有了整体的认识,数据集的处理、模型的搭建、训练策略的选择、超参数的选择对最终训练的结果都将产生影响。经过这一段的学习,觉得机器学习、深度学习这些真的很神奇,但又好像没有想象中的那么神秘,应该有大力出奇迹的可能,但人的智慧却是必不可少的。
参考:
https://www.kaggle.com/code/adarshmalviy/house-prices-prediction-part-2-with-fe
https://blog.csdn.net/weixin_41790863/article/details/119218444
https://blog.csdn.net/coffeetogether/article/details/118459816















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











