







AI取代不了人,但不用AI的人将被用AI的人取代
一、AIGC 是什么
-
AIGC 简介
AIGC(AI Generated Content,人工智能生成内容)是指利用人工智能技术自动生成各种类型的内容,包括文本、图像、音频、视频等。AIGC 技术的发展为内容创作带来了革命性的变化,极大地提高了创作效率,降低了创作成本,并拓展了创作的可能性。
-
AIGC 的应用领域
| 应用领域 | 具体应用 | 产品 |
| 文本生成 | 自动生成文章、新闻、对话、代码等。 | ChatGPT、DeepSeek、豆包、文心一言 |
| 图像生成 | 自动生成图像、艺术创作、设计、广告等。 |
|
| 音频生成 | 自动生成语音、音乐、音效等。 | Amper Music、AIVA、Descript、Murf.ai |
| 视频生成 | 自动生成视频、动画、广告等。 | Sora、Runway ML、Pictory、Lumen5 |
| 代码生成 | 软件开发、自动化脚本、代码生成、补全、优化等。 | GitHub Copilot、Cursor、Codex、Codeium、 MarsCode |
-
AIGC 的发展趋势
-
多模态融合:实现文本、图像、音频、视频等多种模态的联合生成。
-
实时生成:提高生成速度,支持实时应用(如直播、游戏)。
-
个性化定制:根据用户需求生成个性化内容,提升用户体验。
-
伦理与监管:制定相关法律法规,规范 AIGC 的应用和发展。
二、AIGC 图像生成发展史
文生图技术主要基于深度学习和自然语言处理技术。它通过分析输入的文本描述,提取关键信息,然后利用生成对抗网络(GAN)或卷积神经网络(CNN)等深度学习模型生成相应的图像。这种技术的出现,使得人们可以通过简单的文本描述,快速生成高质量的图像,大大提高了内容创作的效率。
AIGC图像生成技术的发展经历了多个阶段,从早期的简单图像处理到如今的高质量、多模态生成。以下是 AIGC 图像生成技术的主要发展阶段和里程碑:
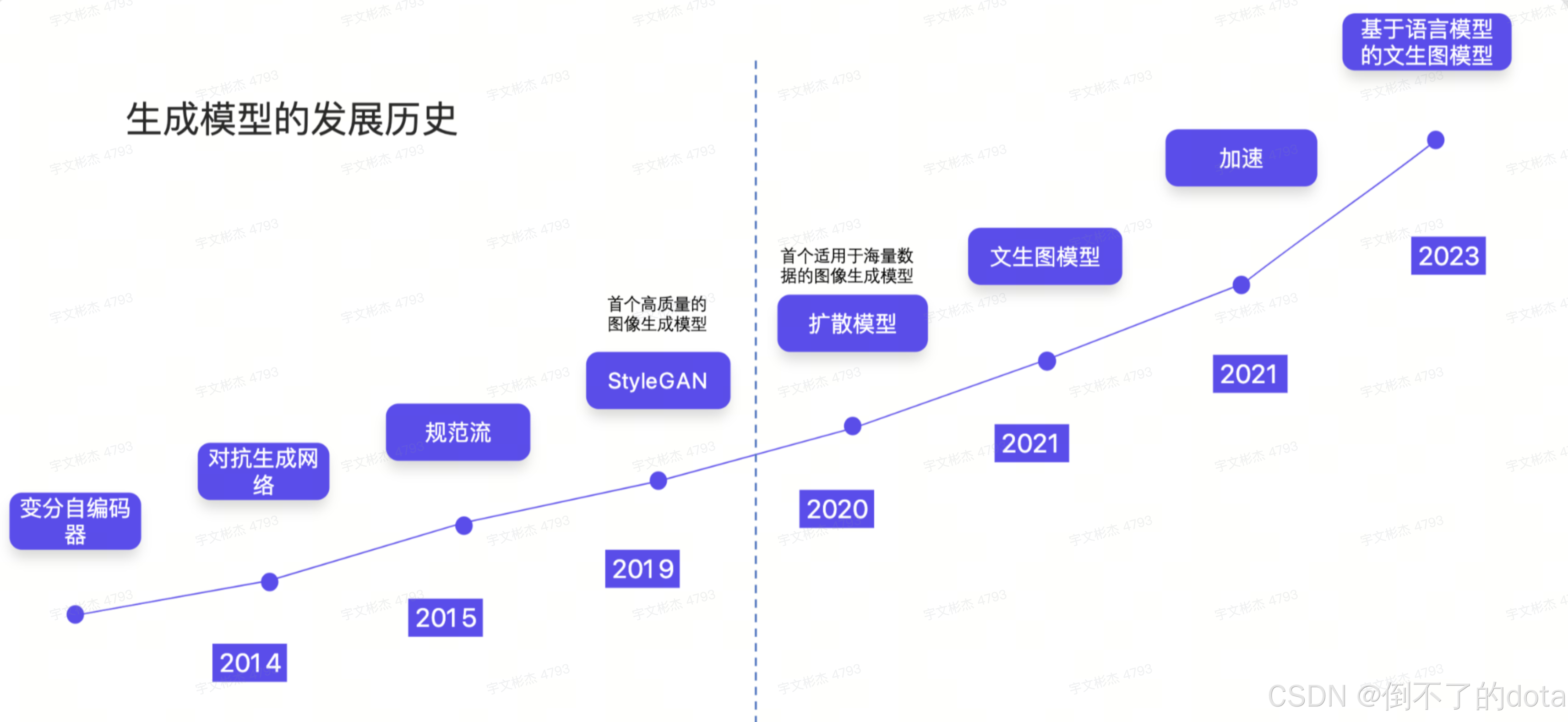
1. 深度学习初期(2000-2014 年)
a. 生成对抗网络(GAN)的提出
特点:2014 年 Ian Goodfellow 提出,GAN 是一种生成模型,由两个神经网络组成:生成器和判别器。生成器负责生成假数据,而判别器则判断数据是真实的还是生成的
原理:生成器和判别器通过对抗的方式进行训练,生成器试图生成更真实的图像,而判别器则试图提高识别假图像的能力。
应用:主要用于生成基础图像
影响:为图像生成技术带来了革命性的突破,是AIGC领域一个重要基础。
b. 卷积神经网络(CNN)
特点:CNN 是一种专门用于处理图像数据的深度学习模型,主要通过卷积层、池化层和全连接层来提取图像特征。
原理:特征提取-通过卷积操作提取局部特征,池化层用于降低维度和计算复杂度,最终通过全连接层进行分类或回归。
应用:主要用于分析和分类图像
2. GAN 快速发展阶段(2015-2018 年)
生成对抗网络(GAN)自提出以来,衍生出许多变种和改进模型
a. DCGAN(深度卷积生成对抗网络)
时间:2015 年
特点:将卷积神经网络(CNN)引入 GAN,作为生成器和判别器,生成更高质量的图像。
应用:人脸生成、图像修复等。
b. CycleGAN
时间:2017 年
特点:实现无监督图像到图像的转换,能够在没有成对样本的情况下进行训练。可以将一种风格的图像转换为另一种风格,如马变成斑马,夏天变成冬天等。
应用:图像翻译、风格迁移等。
c. StyleGAN
时间:2018 年
特点:引入风格控制机制,通过不同层次的特征生成逼真的人脸图像,支持图像插值和风格迁移。
应用:人脸生成、虚拟角色设计等。
3. 多模态生成阶段(2019 年至今)
a. DALL·E⭐️
时间:2021 年
特点:通过 OpenAI API 使用,支持文本到图像生成,生成图像风格多样,标志着AIGC在图像生成方面取得了显著进步。
应用:创意设计、广告、教育等。


b. MidJourney⭐️⭐️⭐️
时间:2022 年
特点:专注于艺术风格图像生成,生成图像具有独特的艺术感,可通过WEB 和 Discord 平台使用,交互友好。
应用:艺术创作、设计、娱乐等。

c. Stable Diffusion⭐️⭐️⭐️⭐️⭐️
时间:2022 年
特点:基于扩散模型,生成高质量图像,支持文本到图像生成、图像修复等任务,完全开源其算法和预训练模型,支持本地部署。
应用:艺术创作、设计、游戏开发等。
影响:这是第一个开源的AI图像生成模型,迅速在社区中流行,推动了AIGC技术的普及和应用,真正改变了游戏规则,形成了庞大的社区生态。
三、 Stable Diffusion模型(简称SD)
1. 文生图原理
Stable Diffusion 的文生图功能是通过 文本条件引导 的扩散模型实现的。其核心原理是将文本描述作为生成过程的控制条件,从而逐步扩散生成与文本内容匹配的图像。以下是其详细原理:
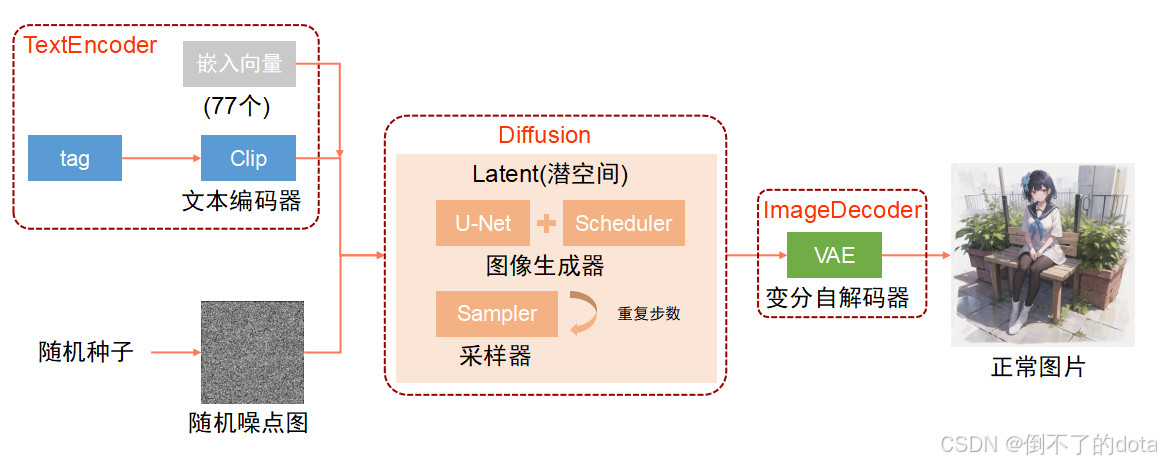
-
输入文本:用户提供文本描述,CLIP模型将文本描述编码为文本嵌入
-
我们输入的描述 prompt自然语言机器是无法直接理解,所以首先需要经过一次文本编码,将自然语言编程成机器能够理解的字节码,Stable-Diffusion模型采用了Clip中文本编码器,通过图像与文本两个分支的特征向量的相似度计算来构建训练目标,形成图像-文本对,以达到Text-to-Image的技术实现
-
通俗来说,Clip干的活就是将文本解析成机器能理解的语言,然后机器根据自己的理解搜索文本在机器的记忆中对应的画面图像,然后向Diffusion提供生成图像的条件。
-
-
初始化噪点图:从潜在空间中随机生成噪声图
-
Stable Diffusion是以去噪的形式来绘制一张图片,在WebUI中的随机种子(seed)就是用来产生一张随机噪点图的,噪点图包含了大量的无规则的像素信息,Diffusion出图的过程就是将随机噪点图中按照Clip给出的出图条件给噪点图去噪的过程
-
-
逐步去噪:将噪声图像和文本嵌入输入 UNet,并预测噪声
-
去噪的过程先是通过U-Net模型根据图像的生成条件从数据集中提取符合要求像素特征
-
然后在特征提取完成之后,通过Sampler(采样器)对特征相关的图像数据进行采样,完成一次采样之后模型就会根据采样结果来调整像素在噪点图中分布,经过多次采样调整的重复,形成新的潜在图像
-
-
生成图像:最终得到与文本描述匹配的高质量图像
-
VAE解码器将潜在图像转换回像素空间,这是运行Stable Diffusion后获得的图像。
-

图生图原理同上,只是将输入的图片被VAE编码为潜在空间噪点图,替换文生图的随机seed
2. CLIP模型
作用:一种多模态模型(文本编码器和图像编码器),能够理解文本和图像之间的关系,用于图像分类、描述生成等任务
过程:
-
使用预训练的文本编码器 CLIP 将文本描述编码为文本嵌入(Text Embedding),文本嵌入是一个高维向量,包含了文本的语义信息
-
文本嵌入作为条件信息输入到扩散模型中,引导图像生成过程,通过 CLIP,Stable Diffusion 能够生成与文本描述语义匹配的图像。
3. VAE模型(变分自编码器)
作用:
-
图像压缩:将高维图像数据压缩到低维潜在空间,减少计算量。
-
图像解码:将潜在空间中的表示还原为高维图像。
过程:
-
Stable Diffusion 在潜在空间中进行扩散过程,最后由VAE解码为像素空间
-
VAE可以将图像压缩到更小的潜在空间而不会丢失信息。原因是自然图像不是随机的,它们具有很高的规律性(面部遵循眼睛、鼻子、脸颊和嘴巴之间的特定空间关系;狗有 4 条腿,是一种特殊的形状等等)。自然图像可以很容易地压缩到更小的潜在空间中,而不会丢失任何信息。这在机器学习中被称为流形假设(高维数据的本质结构位于一个低维流型上)
-
数据降维:通过流型假设,可以将高维数据压缩到低维空间,减少计算复杂度。
-
特征提取:在低维流型中,数据的本质特征更容易被捕捉和表示。
-
生成模型:如 Stable Diffusion,利用流型假设在潜在空间中进行扩散过程,提高生成效率。
-
### **潜在空间与像素空间的维度对比**
在 Stable Diffusion 中,潜在空间(Latent Space)的维度远低于像素空间(Pixel Space),这是为了提高计算效率并减少内存占用。以下是两者的具体对比:
---
#### **1. 像素空间(Pixel Space)**
- **定义**:像素空间是图像在原始分辨率下的表示,每个像素由 RGB 值(或灰度值)组成。
- **维度计算**:
- 对于一张分辨率为 \( H \times W \) 的 RGB 图像,其维度为:
\[
H \times W \times 3
\]
- 例如,一张 512x512 的 RGB 图像的维度为:
\[
512 \times 512 \times 3 = 786,432
\]
- 这意味着像素空间中的每个图像是一个 786,432 维的向量。
---
#### **2. 潜在空间(Latent Space)**
- **定义**:潜在空间是图像经过 VAE 编码器压缩后的低维表示。
- **维度计算**:
- 在 Stable Diffusion 中,潜在空间的维度通常为:
\[
\frac{H}{f} \times \frac{W}{f} \times C
\]
其中:
- \( f \) 是下采样因子(通常为 8)。
- \( C \) 是潜在空间的通道数(通常为 4)。
- 例如,对于一张 512x512 的图像,潜在空间的维度为:
\[
\frac{512}{8} \times \frac{512}{8} \times 4 = 64 \times 64 \times 4 = 16,384
\]
- 这意味着潜在空间中的每个图像是一个 16,384 维的向量。
---
#### **3. 优势**
- **计算效率**:潜在空间的维度远低于像素空间,显著减少了计算量和内存占用。
- **生成质量**:尽管维度降低,VAE 的解码器仍能有效还原高质量图像。
- **灵活性**:在潜在空间中进行扩散过程,使模型更易于训练和优化。
---
### **总结**
在 Stable Diffusion 中,潜在空间的维度通常比像素空间小48倍。例如,对于 512x512 的图像:
- 像素空间维度:786,432
- 潜在空间维度:16,384
这种大幅度的维度压缩是 Stable Diffusion 高效运行的关键之一。4. UNet模型
作用:UNet 是 Stable Diffusion 的核心模型,负责反向扩散过程中的噪声预测
过程:
-
在扩散过程中,预测每一步的噪声,用于逐步去噪。
-
结合文本嵌入等条件信息,实现可控生成。
-
扩散模型(Diffusion Model)
-
前向扩散过程:将真实图像逐步添加噪声,转化为随机噪声。
-
反向扩散过程:从随机噪声开始,逐步去除噪声,生成图像。
-
5. Lora模型
作用:一种用于优化大规模预训练语言模型的技术,主要用于减少模型在特定任务上的微调所需的参数量和计算资源
过程:
-
LoRA 通过仅调整少量参数来适应特定任务,显著减少了训练时间和资源消耗。
-
Lora 用于对 Stable Diffusion 模型进行微调,使其适应特定任务或风格。
四、 可视化生图工具安装
1. 社区开源工具
-
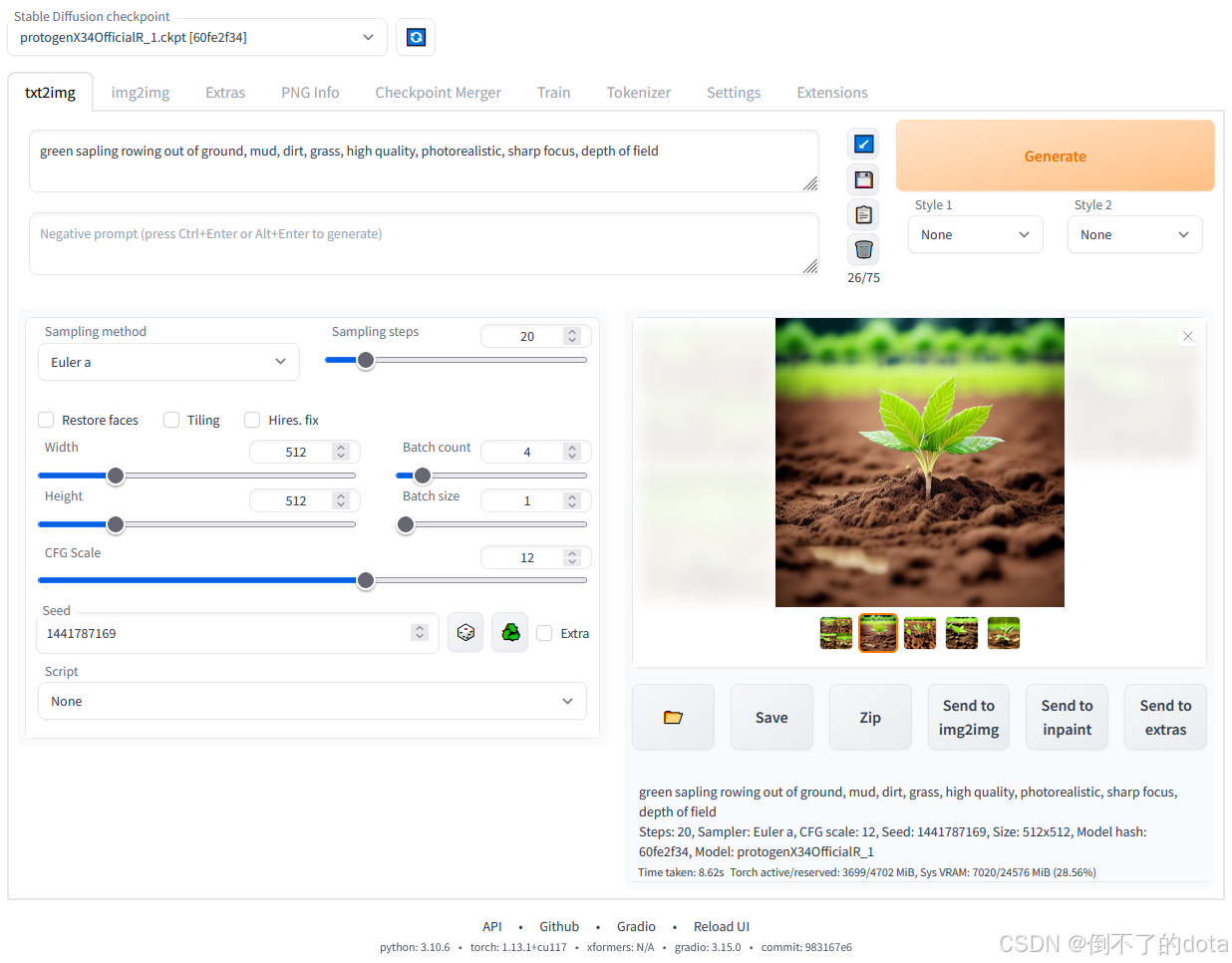
WebUI:https://github.com/AUTOMATIC1111/stable-diffusion-webui
-
优点:生图操作便捷,参数简单,初学者很容易上手
-
缺点:在自定义操作方面有一定限制
-
-
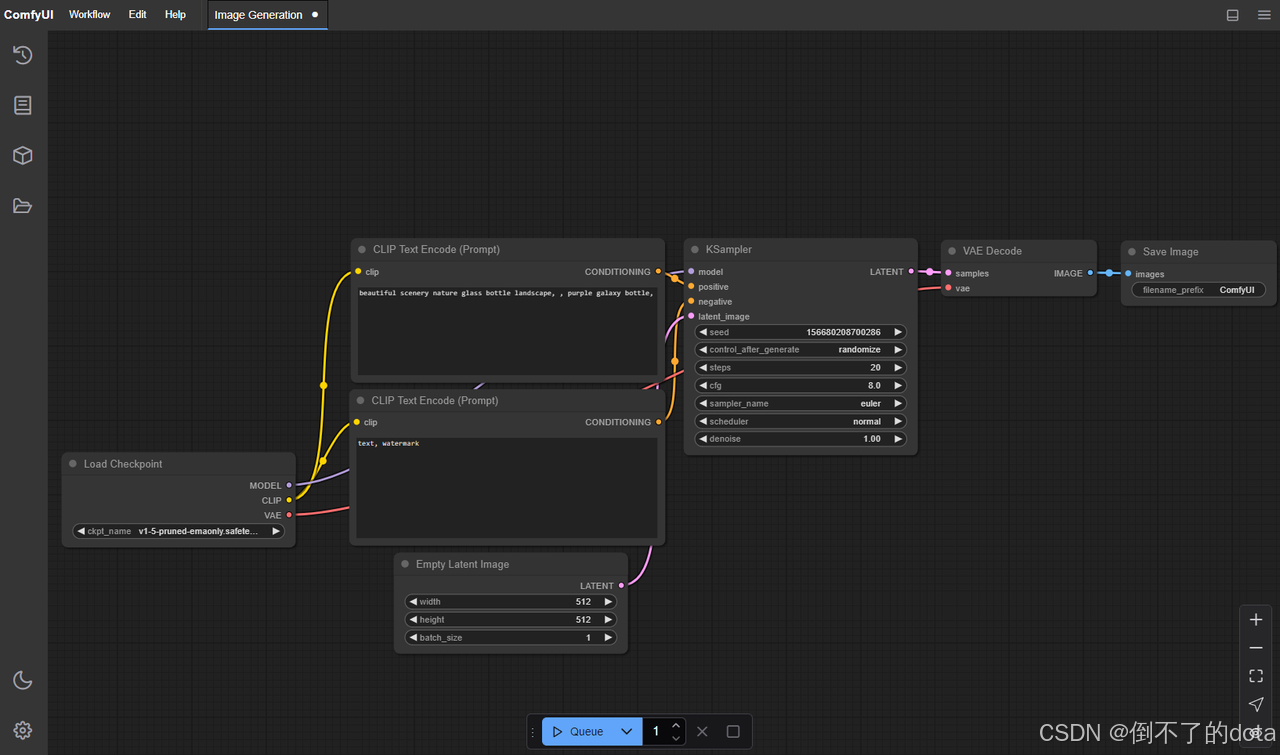
ComfyUI:https://github.com/comfyanonymous/ComfyUI
-
优点:节点自定义,提供了极高的自由度和灵活性,支持高度的定制化和工作流复用,同时对系统配置的要求较低,并且能够加快原始图像的生成速度。
-
缺点:拥有很多的插件节点,以及较为复杂的操作流程,学习起来相对困难
-
2. 本地部署
-
git安装:
-
安装python运行环境
-
安装 PyTorch框架
-
git 拉取webui、comfyui项目:git clone https://github.com/comfyanonymous/ComfyUI.git
-
安装依赖文件:pip3 install -r requirements.txt
-
启动:python3 main.py
-
-
直接下载ComfyUI安装包:https://www.comfy.org/download(Beta版)
五、 开启梦幻之旅
-
丰富的模型社区资源
-
LiblibAI:https://www.liblib.art/
-
国外C站:https://civitai.com
-
国外Huggingface: https://huggingface.co
-
以上网站可以下载各类模型,工作流,查看参数等。
-
下载对应模型到comfuUI指定目录下
-
tips:生成图片中尽量关闭其他占内存的服务,否则卡死
-
-
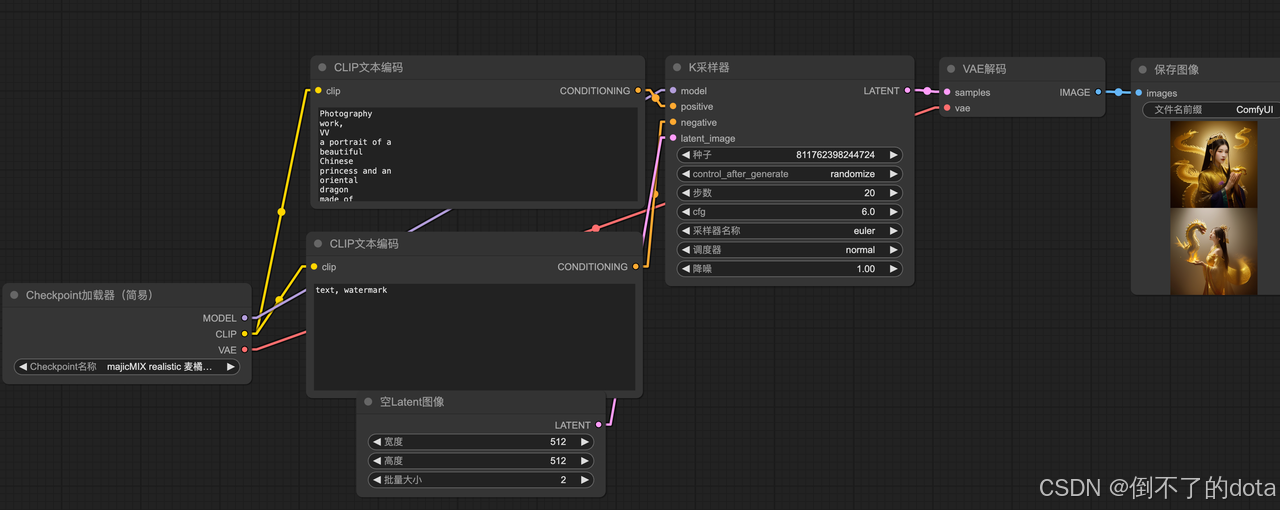
SD基础工作流搭建
-
引入checkpoint加载器节点,选择底模:sd1.5
-
引入2个clip文本编码器,输入正向负向提示词
-
引入空潜在图像节点,控制生成图像大小和数量
-
引入采样器,设置随机seed、训练步数、降噪等参数
-
引入VAE解码,生成图像
-
-
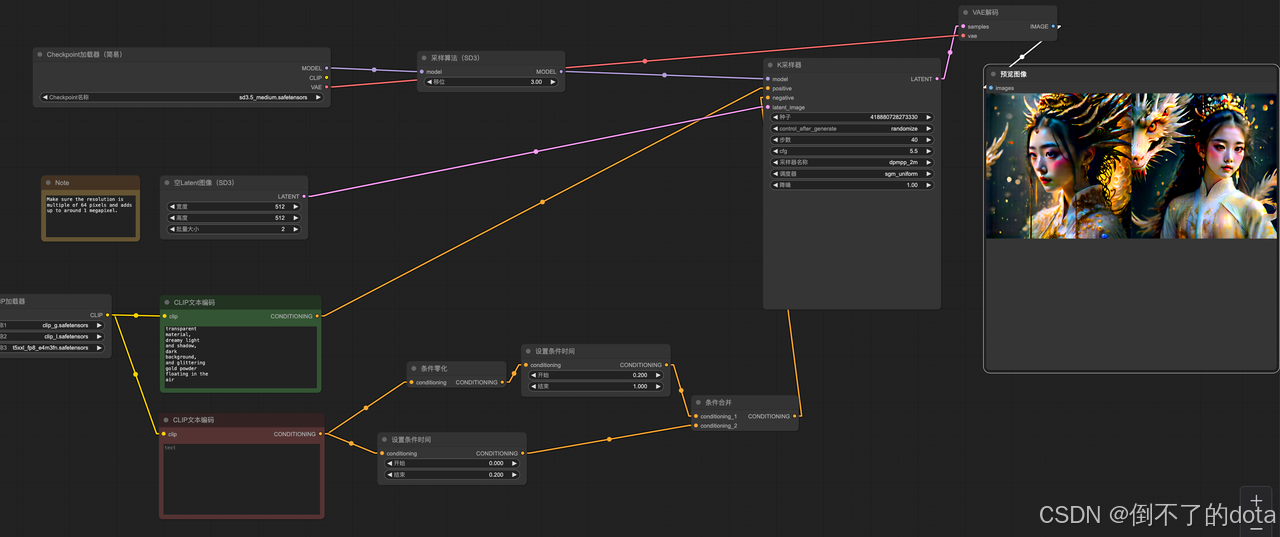
SD3.5工作流搭建
-
引入checkpoint加载器节点,选择底模:sd3.5
-
引入三重clip文本加载器,分别下载clip_g、clip_l、t5xxl_fp8_e4m3fn模型到clip目录,用于解析文本
-
引入2个clip文本编码器,输入正向负向提示词
-
引入空潜在图像节点,控制生成图像大小和数量
-
引入采样器,设置随机seed、训练步数、降噪等参数
-
引入VAE解码,生成图像
-
-
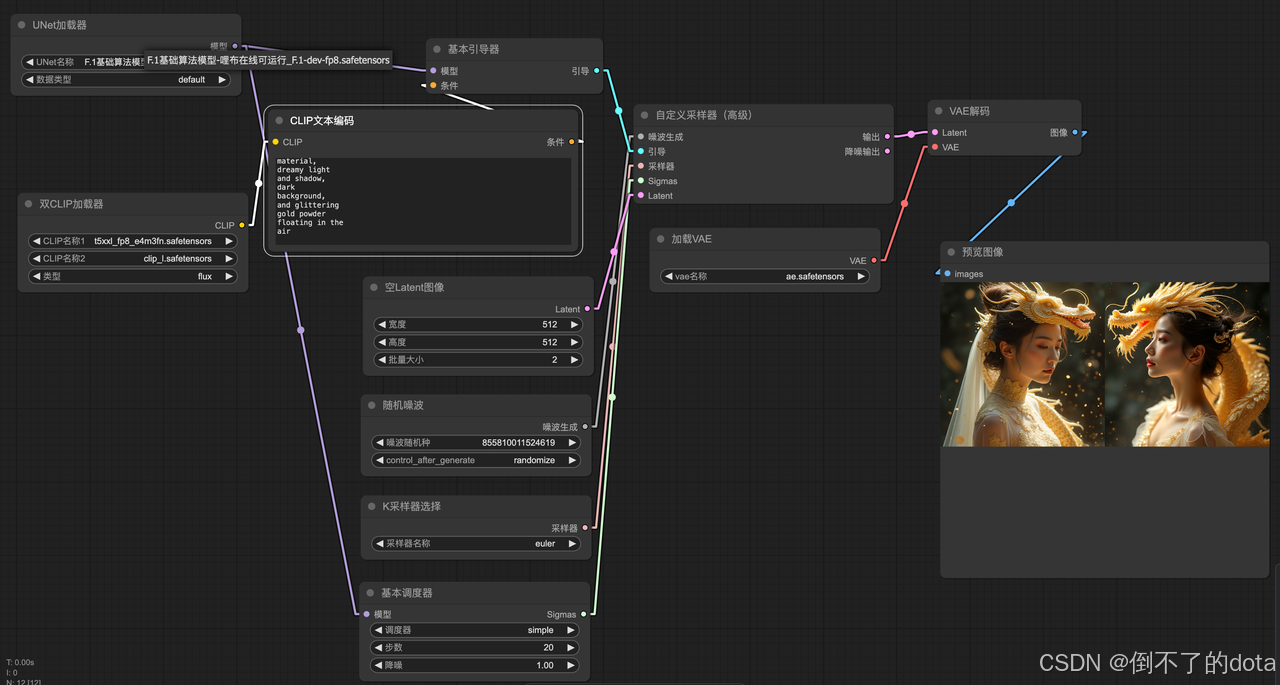
FLUX工作流搭建
-
引入unet加载器节点,选择底模:flux-dev-fp8
-
引入双clip文本加载器,分别下载clip_l、t5xxl_fp8_e4m3fn模型到clip目录,用于解析文本
-
引入2个clip文本编码器,输入正向负向提示词
-
引入空潜在图像节点,控制生成图像大小和数量
-
引入采样器,设置随机seed、训练步数、降噪等参数
-
引入VAE解码,生成图像
-
-
不同模型,生成效果不同
| <SD3模型 | 衍生模型(麦橘写实) | >=SD3 | 提示词 | |
 |  |
|
| Photography work, VV, a portrait of a beautiful Chinese princess and an oriental dragon made of transparent material, dreamy light and shadow, dark background, and glittering gold powder floating in the air. 摄影作品,VV,一幅由透明材料、梦幻般的光影、黑暗的背景和漂浮在空中的闪闪发光的金色粉末制成的美丽的中国公主和东方龙的肖像。 |
 |  |  |  | An Asian female cyborg wearing a white mecha, in a sci-fi style "passage, she" holds up a fluorescent board with the words "Coze". 一位穿着白色机甲的亚洲女性机器人,在科幻风格的“通道”中,她举起了一块写着“Coze”的荧光板。 |
| 期待你的探索... | ||||


-
Lora微调模型
只需在模型和采样器之间添加一个lora加载器即可,即可生成特定样式风格的图片
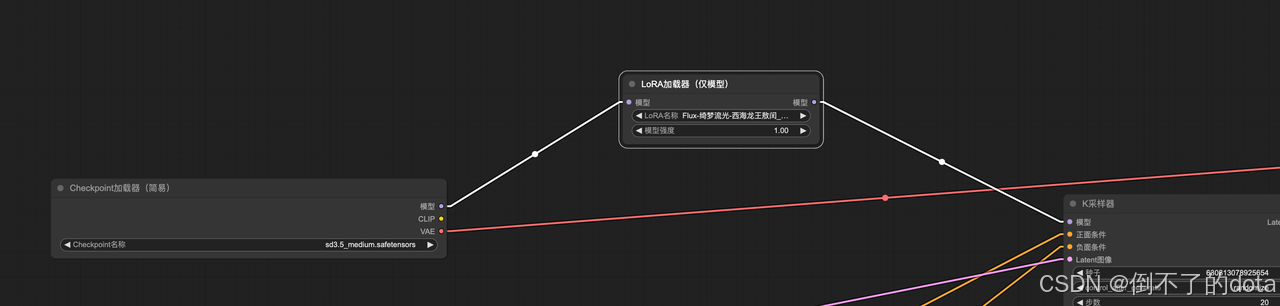
| 无lora | 西海龙王lora模型 | 光影插画lora模型 | 提示词 |
  |
|   | pl, The image is a digital painting of a woman. The woman has long blue hair that is wavy and cascades over her shoulders. Her hair is also blue and has horns on the top of her head. Her eyes are red and she has red lipstick on. She is wearing a dress that is blue and white. The dress has fish scales on it. There are pink flowers in the background. pl(触发词),这幅图像是一幅女性的数字绘画。这位女士有一头波浪形的蓝色长发,垂在肩上。她的头发也是蓝色的,头顶有角。她的眼睛是红色的,涂着红色的口红。她穿着一件蓝白相间的衣服。这件衣服上有鱼鳞。背景中有粉红色的花朵。 |
| 去探索,发现更多好玩模型... | |||


-
应用场景
-
同人动漫创作
-
真人AI生成
-
广告电商图
-
小说插画设计......
-
END
彩蛋:由于大模型是部署在本地的,所以没有审核要求,可以随意发挥想象力去创作图片。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









