







B-Tree详解
B-Tree由来
我们前面已经了解了平衡二叉查找树,如果100w条数据放入到二叉查找树中,假设树的高度为n,则2^0+2^1+2^2+2^3...+2^(n-1)=(2^n)-1=1000000,计算出来n为20,因此查找100w条数据中的一个数据时最多需要查询20次即可。如果是在内存操作的话,查询效率还是蛮高的,但是数据库中的数据都是存放在磁盘上的,每读取一个节点就需要一次磁盘IO,这样子的话查找100w条数据中的一个数据时最多需要20次磁盘IO,20次磁盘IO,这个性能对于磁盘来说太慢了。那么有什么好的方法来解决这个问题呢?答案就是使用B-Tree,即将这棵树压缩一下,减少树的高度,每层上可以容纳更多的节点,这样子就会减少磁盘IO次数从而提高性能
B-Tree特性
假如有一颗 m 阶的B-Tree,则有如下特性:
1、每个节点最多有 m 个子节点
2、除了根节点和叶子结点外,每个节点至少有 m/2 (向上取整,例如 3/2 = 1.5,这里取 2) 个子节点
3、若根节点不是叶子节点,那么根节点至少有2个子节点
4、所有的叶子都在同一层上
5、每个节点都包含 n 个 key,其中 m/2-1 <= n <= m-1
6、每个节点中的元素 key 从小到大排列,元素 key 的左节点的所有元素 key 值都小于等于元素 key,右节点的所有元素 key 值都大于等于元素 key
从上述特性中可知 B-Tree 和其他树结构相比, B-Tree 每个节点可以容纳多个元素。这些特性理解起来比较费事,下面通过示例来让大家对 B-Tree 有一个清晰的认知
B-Tree示例
假如我们要生成一颗 4 阶的 B-Tree树,其过程如下
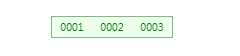
1、先插入 1、2、3,如下图:
2、当插入4 元素时,根据特性5可知,4/2-1 <= n <= 3,即 1<=n<=3,也就是说每个节点最多可以包含 3个元素,此时树的结构需要裂变了,裂变的原则是:节点中的中间元素上移,例如节点中有4个元素,那么第2个或者第3个元素上移都可以,如果有5个元素时,则第3个元素上移就可以了,其他元素按照特性6排列。具体过程如下图:

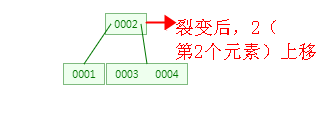
裂变之后,根节点有2个子节点,符合特性3,当根节点不是叶子节点的时候肯定是发生了裂变
3、插入5、6之后,同理步骤2:
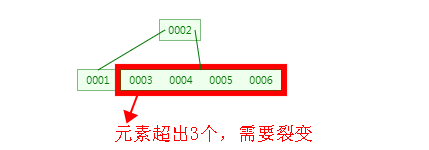
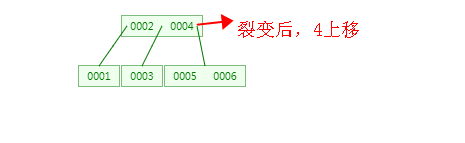
4、插入7、8之后,同理,步骤2:
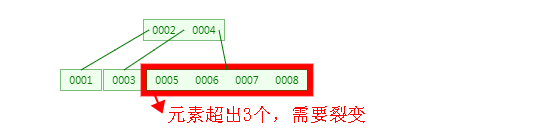
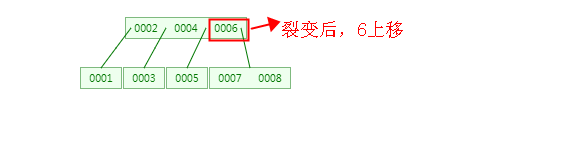
5、插入9、10之后会怎么样呢?同样是同理步骤2,如下图:
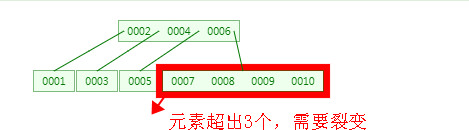
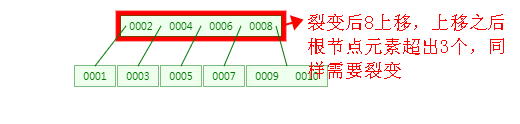
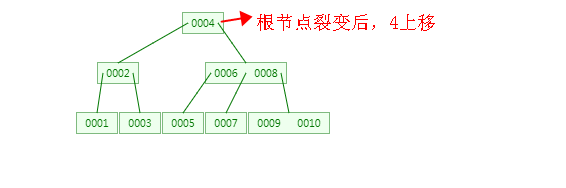
从上述过程可以看出,B-Tree 是从下往上形成的,而二叉树是从上往下形成的。
B-Tree树特性详解
特性1:当父节点元素达到m-1个时,其子节点个数达到m个时,同时这些子节点中的元素达到 m 个时,节点将会裂变,裂变之后父节点元素达到了m个,父节点继续裂变,裂变之后其子节点数量为 m-1 个,因此每个节点最多有 m 个子节点,即特性1
下面就特性1简单演示一下,以便于理解:

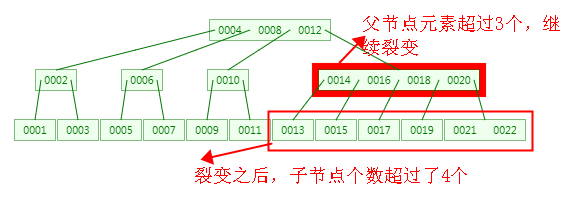
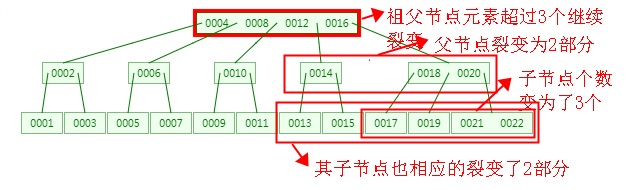

特性2:当节点中的元素达到 m 个时,节点将会裂变,裂变之后子节点个数最少是 m/2 (向上取整) 个,即特性2
特性5:当节点中的元素达到 m 个时,节点将会裂变,裂变之后每个子节点中的元素最少是 m/2-1(原节点元素平分) 个,那么为什么不是 m/2,而是 m/2-1呢,-1是因为有一个节点裂变之后上移成为父节点了,裂变之后每个子节点中的元素最多则是 m-1 个,即特性5
B-Tree高度计算
若一颗 m 阶B-Tree,总元素有 N 个,高度为 h,则有如下推导公式:
1、树的高度:1,2,3,4,.........,h
2、高度对应的节点数:1,2*(m/2)^0,2*(m/2)^1,2*(m/2)^2,.........,2*(m/2)^(h-2)
3、总结点数 s = 1 + 2*((m/2)^(h-1) -1)/((m/2) -1)
4、总元素 N = 1 + (s -1) * ((m/2) - 1) = 2*((m/2)^(h-1)) - 1
5、高度 h = log[m/2]((N+1)/2) + 1
数据库怎么使用B-Tree存储数据
从上面介绍我们知道B-Tree中都是存储的数值,而数据库中存储的却是一条条的数据,那么若某数据库是以B-Tree数据结构存储数据的,那么数据是怎么存放的呢?看下图所示:

上图中,我们把元素拆分成了 key-data 的形式,Key 就是数据的主键,Data 就是具体的数据。
这样我们在查找一条数据的时候,就沿着根结点往下找 key 就 OK 了,效率是比较高的,查找到key就直接可以获取对应的数据data了
B+Tree详解
B+Tree由来
B+Tree 是 B-Tree 基础上的一种优化,使其更适合实现外存储索引结构,InnoDB(mysql存储引擎)存储引擎就是使用 B+Tree 存储索引结构的。既然已经有了B-Tree,那么为什么还需要有B+Tree呢?主要是由于同等数据量的数据存储到 B+Tree 中时,树的高度更低,查询效率更高,这个后面讲解
B+Tree特性
1、所有非叶子节点只存储 key 信息,不存储 data(数据信息)
2、所有 data (数据信息)都存储在叶子节点中
3、所有叶子节点之间都有一个链指针
4、所有叶子节点包含了全部元素(key+data)的信息
B+Tree 示例
这里将 B-Tree 的数据存储图变成 B+Tree 之后,如下图:

图上可以看出:
非叶子节点只存储了 key(关键字)信息,即特性1
所有的 data(数据)信息都保存在了叶子节点中,即特性2
所有的叶子节点之间都有一个链指针,即特性3
所有叶子节点包含所有的数据(key + data)信息
特性3(节点链指针)优点:为了提高区间访问的性能,上图中如果要查询key为[3,7]之间的所有数据记录,当找到3后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率
B+Tree 和 B-Tree 对比
1、同等树高时,B-Tree 查询效率比 B+Tree 高,由于 B-Tree 节点中存储了 key+data 的整个信息,找到 key 就等于是获取到了数据,而 B+Tree 的 data 只存储在叶子节点, 因此必须要遍寻到叶子节点才能获取到 data 信息
2、同等数据量时,B+Tree 的查询效率比 B-Tree 高,由于 B+Tree 的非叶子节点只存储 key 信息,而 B-Tree 的节点存储了 key + data,而每个页(一个节点)的大小是固定的,所以 B+Tree 的树高会更低一些
为了更直观的让大家理解,下面通过两张图来对比一下:


从上图可以看出 同样的 22 个数据,B-Tree 的树高是 4,而 B+Tree 的树高是 3
结论:数据量越大,B+Tree的层高优势就越明显了
3、查找大于或者小于某一个 key(关键字) 的数据时,B+Tree 的效率远远高于 B-Tree,由于 B+Tree 的叶子节点存储了所有 key+data 信息,而且叶子节点之间有链指针,所有查询的时候 B+Tree 只需要找到 key 然后沿着链表遍历就可以了,而 B-Tree就需要一遍遍的从根节点开始查找
为了更直观的让大家理解,下面也通过两张图来对比一下:
B-Tree查询大于8的数据:

B+Tree 查询大于8的数据:

从上图对比可知,B+Tree 的效率远远高于 B-Tree
结论:通过以上3点对比可以得知常用的关系型数据库中,都是会选择 B+Tree来存储数据的
B-Tree和B+Tree网页版生成链接地址
B-Tree:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+Tree:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html















 3900
3900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









