









- 代码包来源:https://github.com/scar-on/Landslide-sensitivity-mapping
样本处理:shp切割栅格
- 运行环境:Python 2.7
- 下述注释为原代码自带
# coding=utf-8
# 多个矢量要裁剪多个栅格文件,裁剪后自动生成文件夹保存。
import arcpy
import os
import glob
import arcpy
from arcpy.sa import *
arcpy.CheckOutExtension("ImageAnalyst") # 检查许可
arcpy.CheckOutExtension("spatial")
from arcpy.sa import *
arcpy.env.workspace = r"D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp/" #个人:最后文件夹后要有 / 且文件夹下须有合成的tif
# 定义工作空间及数据路径,路径下有不同区域矢量文件和被裁剪的全部TIFF文件;例如河北省、山东省各省shp,全国多年份 tiff文件(2000-2020)
rasters = arcpy.ListRasters("*", "tif") # 遍历工作空间中的tif格式数据
inMasks = arcpy.ListFeatureClasses() # 遍历工作空间中的shp格式数据
for inMask in inMasks:
for raster in rasters:
outpath = r"D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\raster/"#个人:最后文件夹后要有 /
#if not os.path.exists(outpath + os.sep + str(inMask).replace('.', '_')): # 如果储存路径下没有以矢量文件命名的文件夹
# os.mkdir(outpath + os.sep + str(inMask).replace('.', '_')) # 生成以矢量文件命名的文件夹(注意.shp中的点要替换)
outCJ = ExtractByMask(raster, inMask) # 批量裁剪文件
#print (outpath + os.sep + str(inMask).replace('.', '_') + os.sep + str(raster))
outCJ.save(outpath + str(str(inMask)+raster)) # 输出存储裁剪的栅格数据,存储到新建文件夹里
#print(str(raster)) # 输出读取并裁剪的栅格数据名称
print("over!!!!!!!!")样本改名:Landslide/ NoLandslide
- 位于代码包下,如E:\Downloads\20221024Landslide-sensitivity-mapping-main\Landslide-sensitivity-mapping-main\data_process\changename.py
import os
import shutil
#待处理数据路径
path=r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\NoLandslide' #路径下无其他文件夹/文件干扰
#
path1=r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\NoLandslide\rename'
#1. 首先挑出后缀为tif的文件,单独存入一个文件夹
#2. 将挑出的tif文件进行重新命名 ,例如00000000.tif------>>Landslide.0.tif
i=0
for filename in os.listdir(path):
print(filename)
#temp=filename.split(".")[2]
#print(temp)
#if temp=='tif':
newname="NoLandslide."+str(i)+".tif" #记得修改!!!Landslide 或 NoLandslide
os.rename(path+'/'+filename,path1+'/'+newname)
i+=1
CNN模型训练
train.py:适用于11×11×11样本
from matplotlib.pyplot import draw
from sklearn.utils import shuffle
from sklearn.utils.extmath import softmax
from sklearn.utils.validation import check_non_negative
import torch
import sys
from torch import optim
from torch.functional import Tensor
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.modules.pooling import MaxPool2d
from torch.utils import data
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from osgeo import gdal
from torchvision.transforms.functional import resize
from logger import Logger
from sklearn.metrics import roc_curve, auc, confusion_matrix, f1_score
import pylab as plt
import numpy as np
import os
import csv
import math
import cv2
#torch.cuda.set_device(0)
# 读取多波段tif图像,将其转换为ndarray
def Myloader(path):
dataset = gdal.Open(path) # 读取栅格数据
#print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
#print(img_array)
return img_array
# 得到一个包含路径与标签的列表
def init_process(path, lens):
data = []
name = find_label(path)
for i in range(lens[0], lens[1]):
data.append([path % i, name])
return data
# 重写dataset
class MyDataset(Dataset):
def __init__(self, data, transform, loder):
self.data = data
self.transform = transform
self.loader = loder
def __getitem__(self, item):
img, label = self.data[item]
img = self.loader(img)
# 将图片转化为tensor
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data)
# 得到对应图像的标签
def find_label(str):
first, last = 0, 0
for i in range(len(str) - 1, -1, -1):
if str[i] == '%' and str[i - 1] == '.':
last = i - 1
if (str[i] == 'N' or str[i] == 'L') and str[i - 1] == '/':
first = i
break
name = str[first:last]
if name == 'Landslide':
return 1
else:
return 0
# 将数据送入模型
def load_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
#数据路径
path1 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples\all11×11Landslide\all_rename/Landslide.%d.TIF'
path2 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples\all11×11NoLandslide\some_rename/NoLandslide.%d.TIF'
path3 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples\all11×11Landslide\all_rename/Landslide.%d.TIF'
path4 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples\all11×11NoLandslide\some_rename/NoLandslide.%d.TIF'
data1= init_process(path1, [0, 5])
data2 = init_process(path2, [0, 5])
data3 = init_process(path3, [6, 9])
data4 = init_process(path4, [6,9])
#print(data2)
#580个 训练
train_data = data2[0:5]+data2[0:5]
train = MyDataset(train_data, transform=transform, loder=Myloader)
#146个 测试
test_data = data3[0:5]+data4[0:3]
test = MyDataset(test_data, transform=transform, loder=Myloader)
#print(train_data)
train_data = DataLoader(dataset=train, batch_size=1, shuffle=True, num_workers=0)
test_data = DataLoader(dataset=test, batch_size=1, shuffle=False, num_workers=0)
return train_data, test_data
def drawAUC_train(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f%%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./Train_AUC') == False:
os.makedirs('./Train_AUC')
plt.savefig('Train_AUC/train_aucx.png', format='png')
def drawAUC_TwoClass(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f %%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./resultphoto') == False:
os.makedirs('./resultphoto')
print("AUC:", roc_auc)
plt.savefig(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples/AUC_TwoClassx.png', format='png')
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples/train.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
# 定义softmax
# 注意力机制
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class cnn_std(nn.Module):
def __init__(self):
super(cnn_std, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=156,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(),
nn.BatchNorm2d(num_features=156),
nn.MaxPool2d(kernel_size=2),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=156 * 4 * 4, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=2)
def forward(self, x):
x = x.type(torch.cuda.FloatTensor)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.fc1(x)
output = self.fc2(x)
return output, x
class cnn_s(nn.Module):
def __init__(self):
super(cnn_s, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
# stride=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=156,
kernel_size=3,
# stride=1,
# padding=0
),
nn.ReLU(),
nn.BatchNorm2d(num_features=156),
nn.MaxPool2d(kernel_size=2),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=156 * 2 * 2, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=2)
def forward(self, x):
x = x.type(torch.cuda.FloatTensor)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
output = self.fc2(x)
x = self.dropout(x)
return output, x
class cnn_s1(nn.Module):
def __init__(self):
super(cnn_s1, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
)
self.se1 = SELayer(channel=64, reduction=16)
self.pool1 = nn.MaxPool2d(kernel_size=2)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=256,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=256),
)
self.se2 = SELayer(channel=128, reduction=16)
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.se3 = SELayer(channel=256, reduction=16)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=256 * 2 * 2, out_features=2)
# self.fc2 = nn.Linear(in_features=120, out_features=64)
# self.fc3 = nn.Linear(in_features=64,out_features=2)
def forward(self, x):
x = x.type(torch.cuda.FloatTensor)
x = self.conv1(x)
x = self.se1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.se2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.se3(x)
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
output = self.fc1(x)
return output, x
class cnn_mul(nn.Module):
def __init__(self):
super(cnn_mul, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=11, #改为in_channels=17
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
self.se1 = SELayer(channel=64, reduction=16)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
nn.MaxPool2d(kernel_size=2),
)
self.se2 = SELayer(channel=128, reduction=16)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=196,
kernel_size=3,
stride=1,
padding=1,
),
nn.BatchNorm2d(num_features=196),
nn.ReLU(),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=196 * 2 * 2, out_features=784) #改
self.fc2 = nn.Linear(in_features=784, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.se1(x)
x = self.conv2(x)
x = self.se2(x)
x = self.conv3(x)
x=self.dropout(x)
x = x.view(x.size(0), -1)
x=self.fc1(x)
#x = x.view(-1, 196 * 2 * 2) #改
#self.fc1 = nn.Linear(196 * 2 * 2, 784)
output = self.fc2(x)
return output, x
# 训练及相关超参数设置
def train():
train_log_path = r"./log/train_log"
train_logger = Logger(train_log_path)
train_loader, test_loader = load_data()
epoch_num = 10
# GPU计算
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = cnn_mul().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss().to(device)
output_list = []
labels_list = []
for epoch in range(epoch_num):
model.train()
running_loss = 0.0
running_corrects = 0.0
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = Variable(data).to(device), Variable(target.long()).to(device)
optimizer.zero_grad() # 梯度清0
output = model(data)[0] # 前向传播s
_, preds = torch.max(output.data, 1)
_, argmax = torch.max(output, 1)
output_list.extend(output.detach().cpu().numpy())
labels_list.extend(target.cpu().numpy())
accuracy = (target == argmax.squeeze()).float().mean()
loss = criterion(output, target) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算一个epoch的值
running_loss += loss.item() * data.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == target.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = float(running_corrects) / len(train_loader.dataset)
# scheduler.step()
print('{} Loss: {:.4f} Acc: {:.4f} Acc1:{:.4f}'.format('train', loss.item(), epoch_acc, accuracy))
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
for tag, value in info.items():
train_logger.scalar_summary(tag, value, epoch)
score_array = np.array(output_list)
drawAUC_train(labels_list, score_array[:, 0]) #改
save_log(labels_list, score_array[:, 0])
torch.save(model, 'cnn202210222.pkl')
def test():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('cnn202210222.pkl') # load model
# print(model)
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
TP = 0
TN = 0
FN = 0
FP = 0
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)[0] #个人:效果同outputs = model(images)
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
# TP predict 和 label 同时为1
TP += ((predicted == 1) & (labels.data == 1)).cpu().sum()
# TN predict 和 label 同时为0
TN += ((predicted == 0) & (labels.data == 0)).cpu().sum()
# FN predict 0 label 1
FN += ((predicted == 0) & (labels.data == 1)).cpu().sum()
# FP predict 1 label 0
FP += ((predicted == 1) & (labels.data == 0)).cpu().sum()
total += labels.size(0)
current += (predicted == labels).sum()
precision = TP / (TP + FP)
recall = TP / (TP + FN)
F1_score = (2 * precision * recall) / (precision + recall)
MCC = (TP * TN - FP * FN) / (math.sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN)))
print("precision:", precision)
print("recall:", recall)
print("F1_score:", F1_score)
print("MCC:", MCC)
print('Accuracy: %d %%' % (100 * current / total))
score_array = np.array(outputs_list)
drawAUC_TwoClass(labels_list, score_array[:, 0]) #改
# save_log(labels_list,score_array[:,1])
def predicted_tif(): #所用数据为 test_data = data3[0:2]
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('cnn202210222.pkl') # load model
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)[0]
print('outputs:',outputs)
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data #dim=1表示输出所在行的最大值,若改写成dim=0则输出所在列的最大值
outputs = outputs.data.cpu().numpy()
result = softmax(outputs)
print('outputs:',outputs)
print('result:',result)
print('predicted:',predicted)
print('\n')
total += labels.size(0)
current += (predicted == labels).sum()
print('current, total',current,total)
print('Accuracy: %d %%' % (100 * current / total))
def save_log(data1, data2):
m = zip(data1, data2)
with open('D:/Desktop/geological_disaster/DL_LandslideSusceptibility/20221019samples/temp1111/ROC85.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
def img_preprocess():
# 读取多波段tif图像,将其转换为ndarray
# dataset = gdal.Open("D:/CNN/cnn_datas2/testing_data/Landslide/Landslide.580.tif")
dataset = gdal.Open(r"D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples\all11×11NoLandslide\some_rename/NoLandslide.9.TIF") # 读取栅格数据
#D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221021samples\all11×11Landslide\all_rename/Landslide.5.TIF
#print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
print(img_array.shape)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
img_array = transform(img_array)
img_array = img_array.unsqueeze(0)
# print(img_array.size())
return img_array
# 定义获取梯度的函数
def backward_hook(module, grad_in, grad_out):
grad_block.append(grad_out[0].detach())
# 定义获取特征图的函数
def farward_hook(module, input, output):
fmap_block.append(output)
# 计算grad-cam并可视化
def cam_show_img(feature_map, grads):
# H, W, _ = img.shape
cam = np.zeros(feature_map.shape[1:], dtype=np.float32) # 4
grads = grads.reshape([grads.shape[0], -1]) # 5
weights = np.mean(grads, axis=1) # 6
for i, w in enumerate(weights):
cam += w * feature_map[i, :, :] # 7
cam = np.maximum(cam, 0)
cam = cam / cam.max()
cam = cv2.resize(cam, (17, 17))
heatmap = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
cam_img = heatmap
# path_cam_img = os.path.join(out_dir, "cam.jpg")
cv2.imwrite("cam1.jpg", cam_img)
return heatmap
if __name__ == '__main__':
train()
test()
predicted_tif()
# 存放梯度和特征图
fmap_block = list()
grad_block = list()
# 导入图像
img_input = img_preprocess()
# 加载训练好的pth文件
# pthfile = './cnn.pkl'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = torch.load('cnn202210222.pkl')
print(net)
net.eval() # 8
net.conv3[-1].register_forward_hook(farward_hook) # 9
net.conv3[-1].register_backward_hook(backward_hook)
# forward
img_input = img_input.to(device)
output = net(img_input)[0]
idx = np.argmax(output.cpu().data.numpy())
predicted = torch.max(output.data, 1)[1].data
print('idx:',idx)
print('predicted:',predicted) #输出最大概率的下标 所属类别0
# backward
net.zero_grad()
class_loss = output[0, idx]
class_loss.backward()
# 生成cam
grads_val = grad_block[0].cpu().data.numpy().squeeze()
fmap = fmap_block[0].cpu().data.numpy().squeeze()
cam_show_img(fmap, grads_val)
train.py:适用于12×16×16样本
- 将上述代码用至12×16×16样本时,出现若干错误,主要关于向量维度不匹配,报错信息如:Expected input batch_size (1) to match target batch_size (2). /// The size of tensor a (2) must match the size of tensor b (6) at non-singleton dimension 0
- 主要修改①:通过设置断点调试,发现过程中图像维度竟为(16, 12, 16),而正常的变换也就(12, 16, 16)或(16, 16, 12),不太可能通道数在中间,故修改transforms.py:添加 “img = img.permute(1, 0, 2)”
permute(2, 0, 1)在pytorch的tensor处理中有什么用吗
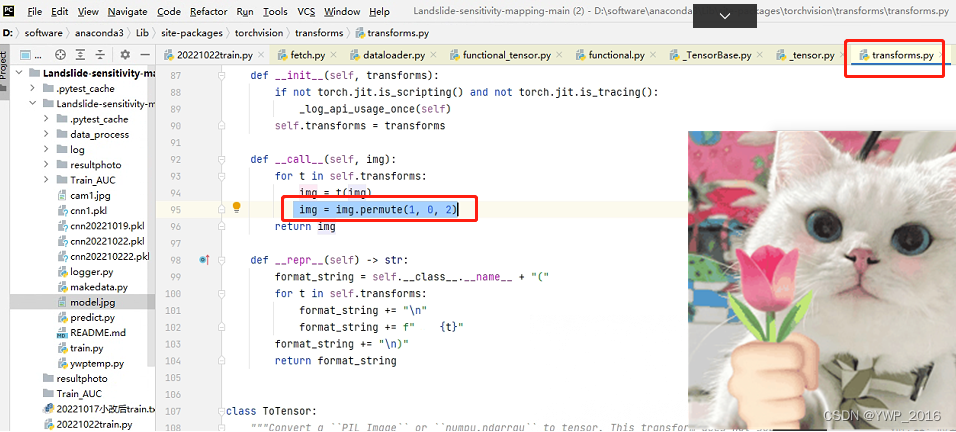
- 主要修改②:仍然是针对图像维度问题,在训练取数据时,添加维度变换语句:
data = data.permute(0, 2, 1, 3)在主函数导入数据时,亦添加维度变换语句:
img_input= img_input.permute(0, 2, 1, 3)- 主要修改③:修改归一化维度(1.0个数),修改路径等
def load_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])- train.py 完整代码如下
from matplotlib.pyplot import draw
from sklearn.utils import shuffle
from sklearn.utils.extmath import softmax
from sklearn.utils.validation import check_non_negative
import torch
import sys
from torch import optim
from torch.functional import Tensor
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.modules.pooling import MaxPool2d
from torch.utils import data
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from osgeo import gdal
from torchvision.transforms.functional import resize
#from logger import Logger
from sklearn.metrics import roc_curve, auc, confusion_matrix, f1_score
import pylab as plt
import numpy as np
import os
import csv
import math
import cv2
#torch.cuda.set_device(0)
# 读取多波段tif图像,将其转换为ndarray
def Myloader(path):
dataset = gdal.Open(path) # 读取栅格数据
# print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
# print(img_array)
return img_array
# 得到一个包含路径与标签的列表
def init_process(path, lens):
data = []
name = find_label(path)
for i in range(lens[0], lens[1]):
data.append([path % i, name])
return data
# 重写dataset
class MyDataset(Dataset):
def __init__(self, data, transform, loder):
self.data = data
self.transform = transform
self.loader = loder
def __getitem__(self, item):
img, label = self.data[item]
img = self.loader(img)
# 将图片转化为tensor
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data)
# 得到对应图像的标签
def find_label(str):
first, last = 0, 0
for i in range(len(str) - 1, -1, -1):
if str[i] == '%' and str[i - 1] == '.':
last = i - 1
if (str[i] == 'N' or str[i] == 'L') and str[i - 1] == '/':
first = i
break
name = str[first:last]
if name == 'Landslide':
return 1
else:
return 0
# 将数据送入模型
def load_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
#数据路径
path1 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\Landslide\rename/Landslide.%d.tif'
path2 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\NoLandslide\rename/NoLandslide.%d.tif'
path3 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\Landslide\rename/Landslide.%d.tif'
path4 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\NoLandslide\rename/NoLandslide.%d.tif'
data1 = init_process(path1, [0, 6])
data2 = init_process(path2, [0, 6])
data3 = init_process(path3, [0, 6])
data4 = init_process(path4, [0, 6])
# print(data2)
# 580个 训练
train_data = data1 + data2
train = MyDataset(train_data, transform=transform, loder=Myloader)
# 146个 测试
test_data = data3 + data4
test = MyDataset(test_data, transform=transform, loder=Myloader)
# print(train_data)
train_data = DataLoader(dataset=train, batch_size=2, shuffle=True, num_workers=0)
test_data = DataLoader(dataset=test, batch_size=2, shuffle=False, num_workers=0)
return train_data, test_data
def drawAUC_train(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f%%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./Train_AUC') == False:
os.makedirs('./Train_AUC')
plt.savefig(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp/train_aucx.png', format='png')
def drawAUC_TwoClass(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f %%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./resultphoto') == False:
os.makedirs('./resultphoto')
print("AUC:", roc_auc)
plt.savefig(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp/AUC_TwoClassx.png', format='png')
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp/train.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
# 定义softmax
# 注意力机制
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class cnn_std(nn.Module):
def __init__(self):
super(cnn_std, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=156,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(),
nn.BatchNorm2d(num_features=156),
nn.MaxPool2d(kernel_size=2),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=156 * 4 * 4, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.fc1(x)
output = self.fc2(x)
return output, x
class cnn_s(nn.Module):
def __init__(self):
super(cnn_s, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
# stride=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=156,
kernel_size=3,
# stride=1,
# padding=0
),
nn.ReLU(),
nn.BatchNorm2d(num_features=156),
nn.MaxPool2d(kernel_size=2),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=156 * 2 * 2, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
output = self.fc2(x)
x = self.dropout(x)
return output, x
class cnn_s1(nn.Module):
def __init__(self):
super(cnn_s1, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
)
self.se1 = SELayer(channel=64, reduction=16)
self.pool1 = nn.MaxPool2d(kernel_size=2)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=256,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=256),
)
self.se2 = SELayer(channel=128, reduction=16)
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.se3 = SELayer(channel=256, reduction=16)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=256 * 2 * 2, out_features=2)
# self.fc2 = nn.Linear(in_features=120, out_features=64)
# self.fc3 = nn.Linear(in_features=64,out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.se1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.se2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.se3(x)
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
output = self.fc1(x)
return output, x
class cnn_mul(nn.Module):
def __init__(self):
super(cnn_mul, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12, #个人修改
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
self.se1 = SELayer(channel=64, reduction=16)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
nn.MaxPool2d(kernel_size=2),
)
self.se2 = SELayer(channel=128, reduction=16)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=196,
kernel_size=3,
stride=1,
padding=1,
),
nn.BatchNorm2d(num_features=196),
nn.ReLU(),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=196 * 4 * 4, out_features=384)
self.fc2 = nn.Linear(in_features=384, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.se1(x)
x = self.conv2(x)
x = self.se2(x)
x = self.conv3(x)
# x=self.dropout(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
output = self.fc2(x)
return output, x
# 训练及相关超参数设置
def train():
train_log_path = r"./log/train_log"
#train_logger = Logger(train_log_path)
train_loader, test_loader = load_data()
epoch_num = 20
# GPU计算
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = cnn_mul().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss().to(device)
output_list = []
labels_list = []
for epoch in range(epoch_num):
model.train()
running_loss = 0.0
running_corrects = 0.0
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = Variable(data).to(device), Variable(target.long()).to(device)
data = data.permute(0, 2, 1, 3) #个人修改
optimizer.zero_grad() # 梯度清0
output = model(data)[0] # 前向传播s
_, preds = torch.max(output.data, 1)
_, argmax = torch.max(output, 1)
output_list.extend(output.detach().cpu().numpy())
labels_list.extend(target.cpu().numpy())
accuracy = (target == argmax.squeeze()).float().mean()
loss = criterion(output, target) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算一个epoch的值
running_loss += loss.item() * data.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == target.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = float(running_corrects) / len(train_loader.dataset)
# scheduler.step()
print('{} Loss: {:.4f} Acc: {:.4f} Acc1:{:.4f}'.format('train', loss.item(), epoch_acc, accuracy))
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
#for tag, value in info.items():
# train_logger.scalar_summary(tag, value, epoch)
score_array = np.array(output_list)
drawAUC_train(labels_list, score_array[:, 1])
save_log(labels_list, score_array[:, 1])
torch.save(model, 'cnn20221026.pkl')
def test():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('cnn20221026.pkl') # load model
# print(model)
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
TP = 0
TN = 0
FN = 0
FP = 0
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)[0]
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
# TP predict 和 label 同时为1
TP += ((predicted == 1) & (labels.data == 1)).cpu().sum()
# TN predict 和 label 同时为0
TN += ((predicted == 0) & (labels.data == 0)).cpu().sum()
# FN predict 0 label 1
FN += ((predicted == 0) & (labels.data == 1)).cpu().sum()
# FP predict 1 label 0
FP += ((predicted == 1) & (labels.data == 0)).cpu().sum()
total += labels.size(0)
current += (predicted == labels).sum()
precision = TP / (TP + FP)
recall = TP / (TP + FN)
F1_score = (2 * precision * recall) / (precision + recall)
MCC = (TP * TN - FP * FN) / (math.sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN)))
print("precision:", precision)
print("recall:", recall)
print("F1_score:", F1_score)
print("MCC:", MCC)
print('Accuracy: %d %%' % (100 * current / total))
score_array = np.array(outputs_list)
drawAUC_TwoClass(labels_list, score_array[:, 1])
# save_log(labels_list,score_array[:,1])
def predicted_tif():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('cnn20221026.pkl') # load model
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)[0]
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
outputs = outputs.data.cpu().numpy()
result = softmax(outputs)
print(result)
print(predicted)
total += labels.size(0)
current += (predicted == labels).sum()
print('Accuracy: %d %%' % (100 * current / total))
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp/ROC85.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
def img_preprocess():
# 读取多波段tif图像,将其转换为ndarray
# dataset = gdal.Open("D:/CNN/cnn_datas2/testing_data/Landslide/Landslide.580.tif")
dataset = gdal.Open(r"D:\Desktop\geological_disaster\DL_LandslideSusceptibility\20221024samples\temp\NoLandslide\rename/NoLandslide.0.tif") # 读取栅格数据
# print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
print(img_array.shape)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
img_array = transform(img_array)
img_array = img_array.unsqueeze(0)
# print(img_array.size())
return img_array
# 定义获取梯度的函数
def backward_hook(module, grad_in, grad_out):
grad_block.append(grad_out[0].detach())
# 定义获取特征图的函数
def farward_hook(module, input, output):
fmap_block.append(output)
# 计算grad-cam并可视化
def cam_show_img(feature_map, grads):
# H, W, _ = img.shape
cam = np.zeros(feature_map.shape[1:], dtype=np.float32) # 4
grads = grads.reshape([grads.shape[0], -1]) # 5
weights = np.mean(grads, axis=1) # 6
for i, w in enumerate(weights):
cam += w * feature_map[i, :, :] # 7
cam = np.maximum(cam, 0)
cam = cam / cam.max()
cam = cv2.resize(cam, (17, 17))
heatmap = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
cam_img = heatmap
# path_cam_img = os.path.join(out_dir, "cam.jpg")
cv2.imwrite("cam1.jpg", cam_img)
return heatmap
if __name__ == '__main__':
train()
# test()
# predicted_tif()
# 存放梯度和特征图
fmap_block = list()
grad_block = list()
# 导入图像
img_input = img_preprocess()
img_input= img_input.permute(0, 2, 1, 3) #个人修改
# 加载训练好的pth文件
# pthfile = './cnn.pkl'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = torch.load('cnn20221026.pkl')
print(net)
# net.eval() # 8
net.conv3[-1].register_forward_hook(farward_hook) # 9
net.conv3[-1].register_backward_hook(backward_hook)
# forward
img_input = img_input.to(device)
output = net(img_input)[0]
idx = np.argmax(output.cpu().data.numpy())
predicted = torch.max(output.data, 1)[1].data
print(idx)
print(predicted)
# backward
net.zero_grad()
class_loss = output[0, idx]
class_loss.backward()
# 生成cam
grads_val = grad_block[0].cpu().data.numpy().squeeze()
fmap = fmap_block[0].cpu().data.numpy().squeeze()
# cam_show_img(fmap, grads_val)train.py:适用于13×32×32样本
- 将上述代码用至13×32×32样本时,出现若干错误,主要关于向量维度不匹配,报错信息如:The size of tensor a (2) must match the size of tensor b (32) at non-singleton dimension 0 /// The size of tensor a (512) must match the size of tensor b (8192) at non-singleton dimension 0
修改方式一
- 相应修改:通过设置断点调试,发现最后的output与target维度不一致,以“batch_size=512”为例,对应修改output维度如下;同时,如此修改后运行发现,还需确保数据集能被batch_size整除才行
output=output.reshape(512,32) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
- load_data函数
# 将数据送入模型
def load_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
#数据路径
path1 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\samples\landslides\raster\tif\rename/Landslide.%d.tif'
path2 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\samples\nonlandslides\raster\rename/NoLandslide.%d.tif'
path3 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\landslides\raster\tif\augmentation\rename/Landslide.%d.tif' #InSAR形变区中的滑坡隐患区
path4 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\nolandslides\raster\rename/NoLandslide.%d.tif'
data1 = init_process(path1, [0, 1058]) #Landslide
data2 = init_process(path2, [0, 1058]) #NoLandslide
data3 = init_process(path3, [0, 1058]) #Landslide
data4 = init_process(path4, [0, 1058]) #NoLandslide
# print(data2)
# 580个 训练
train_data = data1[0:1048] + data2[0:1000] #整除
train = MyDataset(train_data, transform=transform, loder=Myloader)
# 146个 测试
test_data = data3[0:380] + data4[0:470]
test = MyDataset(test_data, transform=transform, loder=Myloader)
train_data = DataLoader(dataset=train, batch_size=512, shuffle=True, num_workers=0)
test_data = DataLoader(dataset=test, batch_size=512, shuffle=False, num_workers=0)
return train_data, test_data
- train函数(test函数 及 predicted_tif函数的修改方式类似)
# 训练及相关超参数设置
def train():
train_log_path = r"./log/train_log"
#train_logger = Logger(train_log_path)
train_loader, test_loader = load_data()
epoch_num = 2
# GPU计算
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = cnn_mul().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss().to(device)
output_list = []
labels_list = []
for epoch in range(epoch_num):
model.train()
running_loss = 0.0
running_corrects = 0.0
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = Variable(data).to(device), Variable(target.long()).to(device)
data = data.permute(0, 2, 1, 3) #个人修改
optimizer.zero_grad() # 梯度清0
output = model(data)[0] # 前向传播s
output=output.reshape(512,32) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
_, preds = torch.max(output.data, 1)
_, argmax = torch.max(output, 1)
output_list.extend(output.detach().cpu().numpy())
labels_list.extend(target.cpu().numpy())
accuracy = (target == argmax.squeeze()).float().mean()
loss = criterion(output, target) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算一个epoch的值
running_loss += loss.item() * data.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == target.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = float(running_corrects) / len(train_loader.dataset)
# scheduler.step()
print('{} Loss: {:.4f} Acc: {:.4f} Acc1:{:.4f}'.format('train', loss.item(), epoch_acc, accuracy))
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
#for tag, value in info.items():
# train_logger.scalar_summary(tag, value, epoch)
score_array = np.array(output_list)
drawAUC_train(labels_list, score_array[:, 1])
save_log(labels_list, score_array[:, 1])
torch.save(model, r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl')-
train.py完整代码
from matplotlib.pyplot import draw
from sklearn.utils import shuffle
from sklearn.utils.extmath import softmax
from sklearn.utils.validation import check_non_negative
import torch
import sys
from torch import optim
from torch.functional import Tensor
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.modules.pooling import MaxPool2d
from torch.utils import data
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from osgeo import gdal
from torchvision.transforms.functional import resize
#from logger import Logger
from sklearn.metrics import roc_curve, auc, confusion_matrix, f1_score
import pylab as plt
import numpy as np
import os
import csv
import math
import cv2
#torch.cuda.set_device(0)
# 读取多波段tif图像,将其转换为ndarray
def Myloader(path):
dataset = gdal.Open(path) # 读取栅格数据
# print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
# print(img_array)
return img_array
# 得到一个包含路径与标签的列表
def init_process(path, lens):
data = []
name = find_label(path)
for i in range(lens[0], lens[1]):
data.append([path % i, name])
return data
# 重写dataset
class MyDataset(Dataset):
def __init__(self, data, transform, loder):
self.data = data
self.transform = transform
self.loader = loder
def __getitem__(self, item):
img, label = self.data[item]
img = self.loader(img)
# 将图片转化为tensor
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data)
# 得到对应图像的标签
def find_label(str):
first, last = 0, 0
for i in range(len(str) - 1, -1, -1):
if str[i] == '%' and str[i - 1] == '.':
last = i - 1
if (str[i] == 'N' or str[i] == 'L') and str[i - 1] == '/':
first = i
break
name = str[first:last]
if name == 'Landslide':
return 1
else:
return 0
# 将数据送入模型
def load_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
#数据路径
path1 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\samples\landslides\raster\tif\rename/Landslide.%d.tif'
path2 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\samples\nonlandslides\raster\rename/NoLandslide.%d.tif'
path3 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\landslides\raster\tif\augmentation\rename/Landslide.%d.tif' #InSAR形变区中的滑坡隐患区
path4 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\nolandslides\raster\rename/NoLandslide.%d.tif'
data1 = init_process(path1, [0, 1058]) #Landslide
data2 = init_process(path2, [0, 1058]) #NoLandslide
data3 = init_process(path3, [0, 1058]) #Landslide
data4 = init_process(path4, [0, 1058]) #NoLandslide
# print(data2)
# 580个 训练
train_data = data1[0:1048] + data2[0:1000] #得被batch_size整除
train = MyDataset(train_data, transform=transform, loder=Myloader)
# 146个 测试
test_data = data3[0:512] + data4[0:512] #得被batch_size整除
test = MyDataset(test_data, transform=transform, loder=Myloader)
train_data = DataLoader(dataset=train, batch_size=512, shuffle=True, num_workers=0)
test_data = DataLoader(dataset=test, batch_size=512, shuffle=False, num_workers=0)
return train_data, test_data
def drawAUC_train(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f%%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./Train_AUC') == False:
os.makedirs('./Train_AUC')
plt.savefig(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/train_aucx.png',format='png')
def drawAUC_TwoClass(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f %%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./resultphoto') == False:
os.makedirs('./resultphoto')
print("AUC:", roc_auc)
plt.savefig(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108AUC_TwoClassx.png', format='png')
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108train.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
# 定义softmax
# 注意力机制
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class cnn_std(nn.Module):
def __init__(self):
super(cnn_std, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=156,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(),
nn.BatchNorm2d(num_features=156),
nn.MaxPool2d(kernel_size=2),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=156 * 4 * 4, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.fc1(x)
output = self.fc2(x)
return output, x
class cnn_s(nn.Module):
def __init__(self):
super(cnn_s, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
# stride=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=156,
kernel_size=3,
# stride=1,
# padding=0
),
nn.ReLU(),
nn.BatchNorm2d(num_features=156),
nn.MaxPool2d(kernel_size=2),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=156 * 2 * 2, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
output = self.fc2(x)
x = self.dropout(x)
return output, x
class cnn_s1(nn.Module):
def __init__(self):
super(cnn_s1, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=12,
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
)
self.se1 = SELayer(channel=64, reduction=16)
self.pool1 = nn.MaxPool2d(kernel_size=2)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=256,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=256),
)
self.se2 = SELayer(channel=128, reduction=16)
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.se3 = SELayer(channel=256, reduction=16)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=256 * 2 * 2, out_features=2)
# self.fc2 = nn.Linear(in_features=120, out_features=64)
# self.fc3 = nn.Linear(in_features=64,out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.se1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.se2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.se3(x)
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
output = self.fc1(x)
return output, x
class cnn_mul(nn.Module):
def __init__(self):
super(cnn_mul, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=13, #个人修改
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
self.se1 = SELayer(channel=64, reduction=16)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
nn.MaxPool2d(kernel_size=2),
)
self.se2 = SELayer(channel=128, reduction=16)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=196,
kernel_size=3,
stride=1,
padding=1,
),
nn.BatchNorm2d(num_features=196),
nn.ReLU(),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=196 * 4 * 4, out_features=784)
self.fc2 = nn.Linear(in_features=784, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
x = self.se1(x)
x = self.conv2(x)
x = self.se2(x)
x = self.conv3(x)
# x=self.dropout(x)
# x = x.view(x.size(0), -1)
# x=self.fc1(x)
x = x.view(-1, 196 * 2 * 2)
self.fc1 = nn.Linear(196 * 2 * 2, 784)
output = self.fc2(x)
return output, x
# 训练及相关超参数设置
def train():
train_log_path = r"./log/train_log"
#train_logger = Logger(train_log_path)
train_loader, test_loader = load_data()
epoch_num = 200
# GPU计算
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = cnn_mul().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss().to(device)
output_list = []
labels_list = []
for epoch in range(epoch_num):
model.train()
running_loss = 0.0
running_corrects = 0.0
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = Variable(data).to(device), Variable(target.long()).to(device)
data = data.permute(0, 2, 1, 3) #个人修改
optimizer.zero_grad() # 梯度清0
output = model(data)[0] # 前向传播s
output=output.reshape(512,32) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
_, preds = torch.max(output.data, 1)
_, argmax = torch.max(output, 1)
output_list.extend(output.detach().cpu().numpy())
labels_list.extend(target.cpu().numpy())
accuracy = (target == argmax.squeeze()).float().mean()
loss = criterion(output, target) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算一个epoch的值
running_loss += loss.item() * data.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == target.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = float(running_corrects) / len(train_loader.dataset)
# scheduler.step()
print('{} Loss: {:.4f} Acc: {:.4f} Acc1:{:.4f}'.format('train', loss.item(), epoch_acc, accuracy))
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
#for tag, value in info.items():
# train_logger.scalar_summary(tag, value, epoch)
score_array = np.array(output_list)
drawAUC_train(labels_list, score_array[:, 1])
save_log(labels_list, score_array[:, 1])
torch.save(model, r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl')
def test():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl') # load model
# print(model)
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
TP = 0
TN = 0
FN = 0
FP = 0
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
images = images.permute(0, 2, 1, 3) # 个人修改
outputs = model(images)[0]
outputs = outputs.reshape(512, 32) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
# TP predict 和 label 同时为1
TP += ((predicted == 1) & (labels.data == 1)).cpu().sum()
# TN predict 和 label 同时为0
TN += ((predicted == 0) & (labels.data == 0)).cpu().sum()
# FN predict 0 label 1
FN += ((predicted == 0) & (labels.data == 1)).cpu().sum()
# FP predict 1 label 0
FP += ((predicted == 1) & (labels.data == 0)).cpu().sum()
total += labels.size(0)
current += (predicted == labels).sum()
precision = TP / (TP + FP)
recall = TP / (TP + FN)
F1_score = (2 * precision * recall) / (precision + recall)
MCC = (TP * TN - FP * FN) / (math.sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN)))
print("precision:", precision)
print("recall:", recall)
print("F1_score:", F1_score)
print("MCC:", MCC)
print('Accuracy: %d %%' % (100 * current / total))
score_array = np.array(outputs_list)
drawAUC_TwoClass(labels_list, score_array[:, 1])
# save_log(labels_list,score_array[:,1])
def predicted_tif():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl') # load model
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
images = images.permute(0, 2, 1, 3) # 个人修改
outputs = model(images)[0]
outputs = outputs.reshape(512, 32) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
outputs = outputs.data.cpu().numpy()
result = softmax(outputs)
#print(result)
#print('\npredicted:\n',predicted)
total += labels.size(0)
current += (predicted == labels).sum()
print('Accuracy: %d %%' % (100 * current / total))
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108ROC85.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
def img_preprocess():
# 读取多波段tif图像,将其转换为ndarray
# dataset = gdal.Open("D:/CNN/cnn_datas2/testing_data/Landslide/Landslide.580.tif")
dataset = gdal.Open(r"D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\nolandslides\raster\rename/NoLandslide.0.tif") # 读取栅格数据
# print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
print(img_array.shape)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
img_array = transform(img_array)
img_array = img_array.unsqueeze(0)
# print(img_array.size())
return img_array
# 定义获取梯度的函数
def backward_hook(module, grad_in, grad_out):
grad_block.append(grad_out[0].detach())
# 定义获取特征图的函数
def farward_hook(module, input, output):
fmap_block.append(output)
# 计算grad-cam并可视化
def cam_show_img(feature_map, grads):
# H, W, _ = img.shape
cam = np.zeros(feature_map.shape[1:], dtype=np.float32) # 4
grads = grads.reshape([grads.shape[0], -1]) # 5
weights = np.mean(grads, axis=1) # 6
for i, w in enumerate(weights):
cam += w * feature_map[i, :, :] # 7
cam = np.maximum(cam, 0)
cam = cam / cam.max()
cam = cv2.resize(cam, (32, 32))
heatmap = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
cam_img = heatmap
# path_cam_img = os.path.join(out_dir, "cam.jpg")
cv2.imwrite("cam1.jpg", cam_img)
return heatmap
if __name__ == '__main__':
train()
test()
predicted_tif()
# 存放梯度和特征图
fmap_block = list()
grad_block = list()
# 导入图像
img_input = img_preprocess()
img_input= img_input.permute(0, 2, 1, 3) #个人修改
# 加载训练好的pth文件
# pthfile = './cnn.pkl'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = torch.load(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl')
#print(net)
# net.eval() # 8
net.conv3[-1].register_forward_hook(farward_hook) # 9
net.conv3[-1].register_backward_hook(backward_hook)
# forward
img_input = img_input.to(device)
output = net(img_input)[0]
idx = np.argmax(output.cpu().data.numpy())
predicted = torch.max(output.data, 1)[1].data
#print(idx)
#print(predicted)
# backward
net.zero_grad()
class_loss = output[0, idx]
class_loss.backward()
# 生成cam
grads_val = grad_block[0].cpu().data.numpy().squeeze()
fmap = fmap_block[0].cpu().data.numpy().squeeze()
# cam_show_img(fmap, grads_val)修改方式二
- 源代码中,其实只用到“cnn_mul”,故可注释无关代码(cnn_std、cnn_s及cnn_s1相关)
- 设置断点判断各层的输出向量维度,关键代码如下;借此判断各个向量维度,进行修改,关键修改如下(关键:上一层的输出乘积 = 下一层的输入乘积)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=196,
kernel_size=3,
stride=1,
padding=1,
),
nn.BatchNorm2d(num_features=196),
nn.ReLU(),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=784 * 4 * 4, out_features=384) # 8192=128*8*8 3136=196*4*4
self.fc2 = nn.Linear(in_features=384, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
print('conv1:', x.shape)
x = self.se1(x)
print('se1:', x.shape)
x = self.conv2(x)
print('conv2', x.shape)
x = self.se2(x)
print('se2:', x.shape)
x = self.conv3(x)
print('conv3:', x.shape)
x = self.dropout(x)
x = x.view(-1, 784 * 4 * 4) # 8192=128*8*8 3136=196*4*4
x = self.fc1(x)
print('x.shape:', x.shape)
# self.fc2=nn.Linear(512 * 4 * 4, 784)
output = self.fc2(x)
print('output.shape:', output.shape)
return output, x- train.py完整代码
from matplotlib.pyplot import draw
from sklearn.utils import shuffle
from sklearn.utils.extmath import softmax
from sklearn.utils.validation import check_non_negative
import torch
import sys
from torch import optim
from torch.functional import Tensor
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.modules.pooling import MaxPool2d
from torch.utils import data
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from osgeo import gdal
from torchvision.transforms.functional import resize
# from logger import Logger
from sklearn.metrics import roc_curve, auc, confusion_matrix, f1_score
import pylab as plt
import numpy as np
import os
import csv
import math
import cv2
# torch.cuda.set_device(0)
# 读取多波段tif图像,将其转换为ndarray
def Myloader(path):
dataset = gdal.Open(path) # 读取栅格数据
# print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
# print(img_array)
return img_array
# 得到一个包含路径与标签的列表
def init_process(path, lens):
data = []
name = find_label(path)
for i in range(lens[0], lens[1]):
data.append([path % i, name])
return data
# 重写dataset
class MyDataset(Dataset):
def __init__(self, data, transform, loder):
self.data = data
self.transform = transform
self.loader = loder
def __getitem__(self, item):
img, label = self.data[item]
img = self.loader(img)
# 将图片转化为tensor
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data)
# 得到对应图像的标签
def find_label(str):
first, last = 0, 0
for i in range(len(str) - 1, -1, -1):
if str[i] == '%' and str[i - 1] == '.':
last = i - 1
if (str[i] == 'N' or str[i] == 'L') and str[i - 1] == '/':
first = i
break
name = str[first:last]
if name == 'Landslide':
return 1
else:
return 0
# 将数据送入模型
def load_data():
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
# 数据路径
path1 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\samples\landslides\raster\tif\rename/Landslide.%d.tif'
path2 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\samples\nonlandslides\raster\rename/NoLandslide.%d.tif'
path3 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\landslides\raster\tif\augmentation\rename/Landslide.%d.tif' # InSAR形变区中的滑坡隐患区
path4 = r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\nolandslides\raster\rename/NoLandslide.%d.tif'
data1 = init_process(path1, [0, 1058]) # Landslide
data2 = init_process(path2, [0, 1058]) # NoLandslide
data3 = init_process(path3, [0, 1058]) # Landslide
data4 = init_process(path4, [0, 1058]) # NoLandslide
# print(data2)
# 580个 训练
train_data = data1[0:1024] + data2[0:1024]
train = MyDataset(train_data, transform=transform, loder=Myloader)
# 146个 测试
test_data = data3[0:512] + data4[0:512]
test = MyDataset(test_data, transform=transform, loder=Myloader)
train_data = DataLoader(dataset=train, batch_size=512, shuffle=True, num_workers=0)
test_data = DataLoader(dataset=test, batch_size=512, shuffle=False, num_workers=0)
return train_data, test_data
def drawAUC_train(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f%%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./Train_AUC') == False:
os.makedirs('./Train_AUC')
plt.savefig(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/train_aucx.png',
format='png')
def drawAUC_TwoClass(y_true, y_score):
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr) # auc为Roc曲线下的面积
roc_auc = roc_auc * 100
# 开始画ROC曲线
plt.figure(figsize=(5, 5), dpi=300)
plt.plot(fpr, tpr, color='darkorange', linestyle=':', linewidth=4, label='CNN (AUC = %0.2f %%)' % roc_auc)
plt.legend(loc='lower right') # 设定图例的位置,右下角
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.tick_params(direction='in', top=True, bottom=True, left=True, right=True) # 坐标轴朝向
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.grid(linestyle='-.')
plt.xlabel('False Positive Rate') # 横坐标是fpr
plt.ylabel('True Positive Rate') # 纵坐标是tpr
plt.legend(loc="lower right")
if os.path.exists('./resultphoto') == False:
os.makedirs('./resultphoto')
print("AUC:", roc_auc)
plt.savefig(
r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108AUC_TwoClassx.png',
format='png')
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108train.csv',
'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
# 定义softmax
# 注意力机制
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class cnn_mul(nn.Module):
def __init__(self):
super(cnn_mul, self).__init__() # 继承__init__功能
# 第一层卷积
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=13, # 个人修改
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=2),
)
self.se1 = SELayer(channel=64, reduction=16)
# 第二层卷积
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),
nn.BatchNorm2d(num_features=128),
nn.MaxPool2d(kernel_size=2),
)
self.se2 = SELayer(channel=128, reduction=16)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=196,
kernel_size=3,
stride=1,
padding=1,
),
nn.BatchNorm2d(num_features=196),
nn.ReLU(),
)
self.dropout = nn.Dropout2d(p=0.5)
self.fc1 = nn.Linear(in_features=784 * 4 * 4, out_features=512) # 8192=128*8*8 3136=196*4*4
self.fc2 = nn.Linear(in_features=512, out_features=2)
def forward(self, x):
x = x.type(torch.FloatTensor)
x = self.conv1(x)
#print('conv1:', x.shape)
x = self.se1(x)
#print('se1:', x.shape)
x = self.conv2(x)
#print('conv2', x.shape)
x = self.se2(x)
#print('se2:', x.shape)
x = self.conv3(x)
#print('conv3:', x.shape)
x = self.dropout(x)
x = x.view(-1, 784 * 4 * 4) # 8192=128*8*8 3136=196*4*4
x = self.fc1(x)
#print('x.shape:', x.shape)
# self.fc2=nn.Linear(512 * 4 * 4, 784)
output = self.fc2(x)
#print('output.shape:', output.shape)
return output, x
# 训练及相关超参数设置
def train():
train_log_path = r"./log/train_log"
# train_logger = Logger(train_log_path)
train_loader, test_loader = load_data()
epoch_num = 200
# GPU计算
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = cnn_mul().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss().to(device)
output_list = []
labels_list = []
for epoch in range(epoch_num):
model.train()
running_loss = 0.0
running_corrects = 0.0
for batch_idx, (data, target) in enumerate(train_loader, 0):
data, target = Variable(data).to(device), Variable(target.long()).to(device)
data = data.permute(0, 2, 1, 3) # 个人修改
optimizer.zero_grad() # 梯度清0
output = model(data)[0] # 前向传播s
# output=output.reshape(512,32) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
_, preds = torch.max(output.data, 1)
_, argmax = torch.max(output, 1)
output_list.extend(output.detach().cpu().numpy())
labels_list.extend(target.cpu().numpy())
accuracy = (target == argmax.squeeze()).float().mean()
loss = criterion(output, target) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算一个epoch的值
running_loss += loss.item() * data.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == target.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = float(running_corrects) / len(train_loader.dataset)
# scheduler.step()
print('{} Loss: {:.4f} Acc: {:.4f} Acc1:{:.4f}'.format('train', loss.item(), epoch_acc, accuracy))
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
# for tag, value in info.items():
# train_logger.scalar_summary(tag, value, epoch)
score_array = np.array(output_list)
drawAUC_train(labels_list, score_array[:, 1])
save_log(labels_list, score_array[:, 1])
torch.save(model,
r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl')
def test():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load(
r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl') # load model
# print(model)
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
TP = 0
TN = 0
FN = 0
FP = 0
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
images = images.permute(0, 2, 1, 3) # 个人修改
outputs = model(images)[0]
# outputs = outputs.reshape(16,2) #针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
# TP predict 和 label 同时为1
TP += ((predicted == 1) & (labels.data == 1)).cpu().sum()
# TN predict 和 label 同时为0
TN += ((predicted == 0) & (labels.data == 0)).cpu().sum()
# FN predict 0 label 1
FN += ((predicted == 0) & (labels.data == 1)).cpu().sum()
# FP predict 1 label 0
FP += ((predicted == 1) & (labels.data == 0)).cpu().sum()
total += labels.size(0)
current += (predicted == labels).sum()
precision = TP / (TP + FP)
recall = TP / (TP + FN)
F1_score = (2 * precision * recall) / (precision + recall)
MCC = (TP * TN - FP * FN) / (math.sqrt((TP + FP) * (TP + FN) * (TN + FP) * (TN + FN)))
print("precision:", precision)
print("recall:", recall)
print("F1_score:", F1_score)
print("MCC:", MCC)
print('Accuracy: %d %%' % (100 * current / total))
score_array = np.array(outputs_list)
drawAUC_TwoClass(labels_list, score_array[:, 1])
# save_log(labels_list,score_array[:,1])
def predicted_tif():
train_loader, test_loader = load_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load(
r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl') # load model
total = 0
current = 0
outputs_list = [] # 存储预测得分
labels_list = []
for data in test_loader:
# model.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
images = images.permute(0, 2, 1, 3) # 个人修改
outputs = model(images)[0]
outputs = outputs.reshape(16, 32) # 针对32×32尺寸,2022年11月8日个人修改 output=output.reshape(batchsize,32)
outputs_list.extend(outputs.detach().cpu().numpy())
labels_list.extend(labels.cpu().numpy())
predicted = torch.max(outputs.data, 1)[1].data
outputs = outputs.data.cpu().numpy()
result = softmax(outputs)
# print(result)
print('\npredicted:\n', predicted)
total += labels.size(0)
current += (predicted == labels).sum()
print('Accuracy: %d %%' % (100 * current / total))
def save_log(data1, data2):
m = zip(data1, data2)
with open(r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108ROC85.csv',
'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for line in m:
writer.writerow(line)
def img_preprocess():
# 读取多波段tif图像,将其转换为ndarray
# dataset = gdal.Open("D:/CNN/cnn_datas2/testing_data/Landslide/Landslide.580.tif")
dataset = gdal.Open(
r"D:\Desktop\geological_disaster\DL_LandslideSusceptibility\202211_zaihaidian\32×32\insar_samples\nolandslides\raster\rename/NoLandslide.0.tif") # 读取栅格数据
# print('处理图像的栅格波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset,除0是将其转换为浮点类型
img_array = dataset.ReadAsArray() / 1.0
print(img_array.shape)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),
std=(1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)) # 归一化
])
img_array = transform(img_array)
img_array = img_array.unsqueeze(0)
# print(img_array.size())
return img_array
# 定义获取梯度的函数
def backward_hook(module, grad_in, grad_out):
grad_block.append(grad_out[0].detach())
# 定义获取特征图的函数
def farward_hook(module, input, output):
fmap_block.append(output)
# 计算grad-cam并可视化
def cam_show_img(feature_map, grads):
# H, W, _ = img.shape
cam = np.zeros(feature_map.shape[1:], dtype=np.float32) # 4
grads = grads.reshape([grads.shape[0], -1]) # 5
weights = np.mean(grads, axis=1) # 6
for i, w in enumerate(weights):
cam += w * feature_map[i, :, :] # 7
cam = np.maximum(cam, 0)
cam = cam / cam.max()
cam = cv2.resize(cam, (32, 32))
heatmap = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
cam_img = heatmap
# path_cam_img = os.path.join(out_dir, "cam.jpg")
cv2.imwrite("cam1.jpg", cam_img)
return heatmap
if __name__ == '__main__':
train()
test()
# predicted_tif()
# 存放梯度和特征图
fmap_block = list()
grad_block = list()
# 导入图像
img_input = img_preprocess()
img_input = img_input.permute(0, 2, 1, 3) # 个人修改
# 加载训练好的pth文件
# pthfile = './cnn.pkl'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = torch.load(
r'D:\Desktop\geological_disaster\DL_LandslideSusceptibility\results\20221107_32×32/20221108cnn.pkl')
# print(net)
# net.eval() # 8
net.conv3[-1].register_forward_hook(farward_hook) # 9
net.conv3[-1].register_backward_hook(backward_hook)
# forward
img_input = img_input.to(device)
output = net(img_input)[0]
idx = np.argmax(output.cpu().data.numpy())
predicted = torch.max(output.data, 1)[1].data
# print(idx)
# print(predicted)
# backward
net.zero_grad()
class_loss = output[0, idx]
class_loss.backward()
# 生成cam
grads_val = grad_block[0].cpu().data.numpy().squeeze()
fmap = fmap_block[0].cpu().data.numpy().squeeze()
# cam_show_img(fmap, grads_val)















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









