






标题:Generalizing to the Future:Mitigating Entity Bias in Fake News Detection(迎战未来的假新闻:通过缓解实体偏差提高假新闻检测模型的泛化能力)
论文来源:ACM SIGIR 2022
目录
一、问题
作者提出现有的方法忽视了训练数据集中存在的实体偏差(entity bias)造成的负面影响,导致其在未来数据上泛化效果不佳。作者从实体角度对已公开的中文假新闻数据集进行了分析,发现部分高频实体在真假新闻的分布存在明显的时间效应。例如,2010到2017年间关于特朗普的新闻有97%是真实的,然而在2018年这个数字大幅下降到了33%。可以预见,一个基于2010-2017年数据训练的假新闻检测模型,会更倾向于预测特朗普相关的新闻为真:这将限制其在2018年数据上的测试性能。

二、解决
作者提出从因果的角度来缓解模型学习中的实体偏差问题,如图(a)所示,现有的虚假新闻检测的方法基于新闻的所有内容进行预测,其中混杂了实体对新闻标签的直接影响以及非实体信号的影响(如写作风格和情感)。基于因果思想,作者提出了实体去偏假新闻检测框架(ENDEF),以增强检测模型面对“未来数据”的泛化能力,如图(b)所示。在传统的检测支路之外,单独建模实体对新闻真实性标签的直接影响。基于在训练阶段对训练集中所蕴含“实体偏差”的显式建模,通过在测试阶段直接移除实体相关支路,削弱实体对预测结果的影响,从而实现实体去偏。

实体抽取工具:TexSmart
为了进一步增强模型的泛化能力,作者引入两种数据增强的技术,包括:
- drop:随机丢弃部分token;
- mask:随机将部分token替换为特殊符号[MASK]。
在训练阶段,为样本随机选择一种数据增强策略,候选策略如下:
- 以一定的概率随机drop或者mask部分token;
- 以一定的概率随机drop或者mask部分实体。
三、框架细节

同时建模两个因果路径,从实体到标签,以及从实体到新闻内容再到标签:

在训练阶段,依据这两个部分的概率预测为:

为超参数,文中设置为0.8
采用交叉熵进行整个框架的训练:

为了实现更好的抓获实体偏差的目的,使用一个辅助损失,应用额外的监督训练在基于实体的模型上:

因此,总的训练流程包含两个损失函数:

是超参数,文中设置为0.2
作者提出的改善模型适用于所有的基于内容的假新闻检测模型,旨在消除所有模型的实体偏差,也就是所有模型都可以通过他们的训练框架从而达到消除实体偏差的目的。
该改善模型不会改变base model的内在结构或机制,而是用实体数据和全部数据分别训练模型,然后通过loss去控制共同作用和单一作用。具体来讲,因为实体是包含在全部信息中的,当我们利用loss去鼓励模型学习实体和预测结果的联系的时候(单一作用),包含实体的全部信息模型就会减少实体在预测中起到的作用(共同作用)。
三、实验
1.数据集

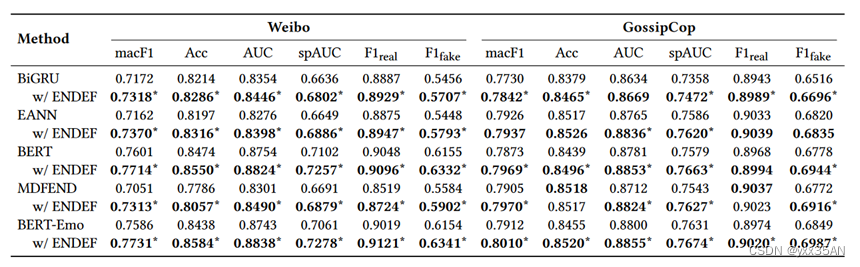
2.离线实验
3.线上实验
使用 “睿鉴识谣”线上数据















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









