







Attention-based Convolutional Neural Networks for Sentence Classification 论文阅读
文章信息:
原文链接:https://www.isca-archive.org/interspeech_2016/zhao16_interspeech.pdf
源码:https://github.com/avinashsai/Attention-based-CNN-for-sentence-classification
Abstract
句子分类是口语理解(SLU)和自然语言处理(NLP)中的基础任务之一。在本文中,我们提出了一种新颖的带注意力机制的卷积神经网络(CNN),以提高句子分类的性能。在传统的CNN中,很难有效地编码长期的上下文信息和非连续词之间的关联。相反,我们基于注意力的CNN能够捕获每个词的这些信息,而无需任何外部特征。我们在各种公共和内部数据集上进行了实验。实验结果表明,我们提出的模型明显优于传统的CNN模型,并且在利用丰富的句法特征的模型中取得了竞争性能。
1. Introduction
口语理解(SLU)通常涉及识别用户意图,即为每个自然语言句子预测一个标签。在自然语言处理(NLP)中,句子分类也是许多应用程序中的基本组成部分,例如问题分类和情感分析。在句子分类中,n-gram是最常用的特征之一。然而,n-gram无法捕获非连续词之间的长期上下文信息。一些研究引入了句法分析信息,并表明这种信息在建模句子中起着重要作用。
最近,神经网络方法在广泛的口语理解(SLU)和自然语言处理(NLP)任务中取得了新的最先进性能。在句子分类中,先前的研究提出了递归神经网络(Recursive NN)、循环神经网络(Recurrent NN)和卷积神经网络(CNN)。为了利用句法分析信息,递归神经网络接受句法分析树,并以自底向上的方式沿着分支生成句子表示,这已被证明在捕获句子语义方面是有效的,但其性能严重依赖于句法树的构建性能。另一方面,循环神经网络从左到右逐字地对句子进行建模,并在固定大小的隐藏层中存储所有先前上下文的信息,这可以捕获长句子的语义,但对后面的词有偏见。因此,一些研究尝试结合递归和循环神经网络的优点,例如将句法分析树馈入到LSTM中,这是循环神经网络的改进变体。CNN最初是在计算机视觉中提出的,最近在NLP任务中变得流行,例如序列标注、机器翻译和句子建模。与递归和循环神经网络不同,CNN通过卷积操作对n-gram进行编码,并通过池化生成固定大小的高级表示。实验结果表明,CNN非常有效地捕获了句子信息,在各种分类任务上取得了新的最先进性能,并且没有偏见问题。
然而,基本CNN存在一个主要限制:它只考虑了在表面字符串上连续的顺序n-gram,因此忽略了非连续词之间的一些远距离相关性,而这种相关性在许多语言现象中起着重要作用,例如否定、从属和wh-提取,所有这些都可能影响到句子的情感、主观性或其他分类。为了解决这个问题,Ma等人提出了一种基于依赖关系的CNN,它将单词的顺序上下文替换为单词的父节点、祖父节点、曾祖父节点和依赖树上的兄弟节点;Mou等人提出了基于树的CNN,用于直接提取句子的句法结构特征,可以是句子的组成树或依赖树。不幸的是,这两个模型都需要句法分析,这需要额外的知识。
同时,一个新的神经网络研究方向已经出现,使模型学习对输入的不同部分进行不同的“注意”,这已应用于机器翻译、标题生成、手写合成、视觉对象分类、语音识别和问题回答等领域。一般来说,大多数现有的关于NLP中注意力的研究都集中在建模不同模态之间的相关性上,例如机器翻译中源语言和目标语言之间的单词对齐,以及问题回答中问题和答案之间的单词相似性。据我们所知,对于句子内部单词之间的相关性建模的研究很少。
在本文中,我们提出了一种新颖的基于注意力机制的卷积神经网络(简称为ATT-CNN),其中注意力机制被用于自动捕捉长期上下文信息和非连续单词之间的相关性,而无需任何外部的句法信息。我们在几个数据集上进行了实验,并展示了所提出的ATT-CNN模型明显优于基本CNN,并且在利用丰富的句法特征的最先进模型方面取得了竞争性能。
2. Attention-based CNN
2.1. Basic CNN
CNN被Collobert等人[11]应用于各种NLP任务,并由Kalchbrenner等人[8]、Kim [14]和Ma等人[15]扩展到句子分类任务。以Kim的CNN [14]为例。该模型首先用每个单词的向量表示替换句子中的每个单词,并创建句子矩阵
A
∈
R
l
×
d
\mathbf{A}\in\mathbb{R}^{l\times d}
A∈Rl×d,其中
l
l
l是(零填充的)句子长度,
d
d
d是词嵌入的维度。
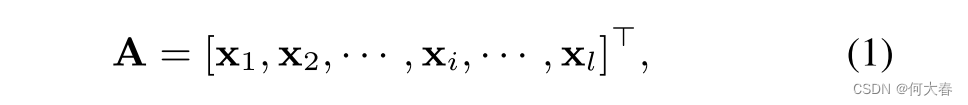
其中
x
i
∈
R
d
\mathbf{x}_i\in\mathbb{R}^d
xi∈Rd是对应于句子中第
i
i
i个单词的
d
d
d维单词向量。其次,卷积操作在宽度为
n
n
n(即
n
n
n个单词)的滑动窗口上进行。具体来说,该操作在滤波器
W
∈
R
n
d
×
h
\mathbf{W}\in\mathbb{R}^{nd\times h}
W∈Rnd×h和句子中的每个
n
n
n-gram之间进行点积,以获得另一个序列
c
c
c,该序列由一系列
h
h
h维向量
c
i
\mathbf{c}_i
ci组成,其计算方式为:
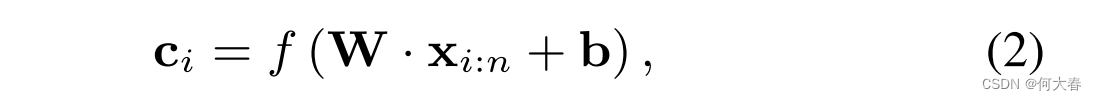
其中
f
f
f是非线性激活函数,如ReLU或sigmoid函数,
x
i
:
n
\mathbf{x}_i:n
xi:n表示
n
n
n个单词向量的连接:
x
i
:
n
=
x
i
⊕
x
i
+
1
⊕
⋯
⊕
x
i
+
n
−
1
\mathbf{x}_i:n=\mathbf{x}_i\oplus\mathbf{x}_{i+1}\oplus\cdots\oplus\mathbf{x}_{i+n-1}
xi:n=xi⊕xi+1⊕⋯⊕xi+n−1。最后,在
c
\mathbf{c}
c上应用最大池化操作,然后是一个全连接的softmax层,其输出是标签上的概率分布。
因此,基础的CNN无法捕捉长期的上下文信息和非连续词之间的关联。依赖关系的CNN在一定程度上克服了这一弱点,但在实际应用中,如口语处理,总是需要额外的资源来获得良好的依赖树。在本文中,我们提出了一种新颖的基于注意力机制的CNN来缓解这个问题。
2.2. ATT-CNN
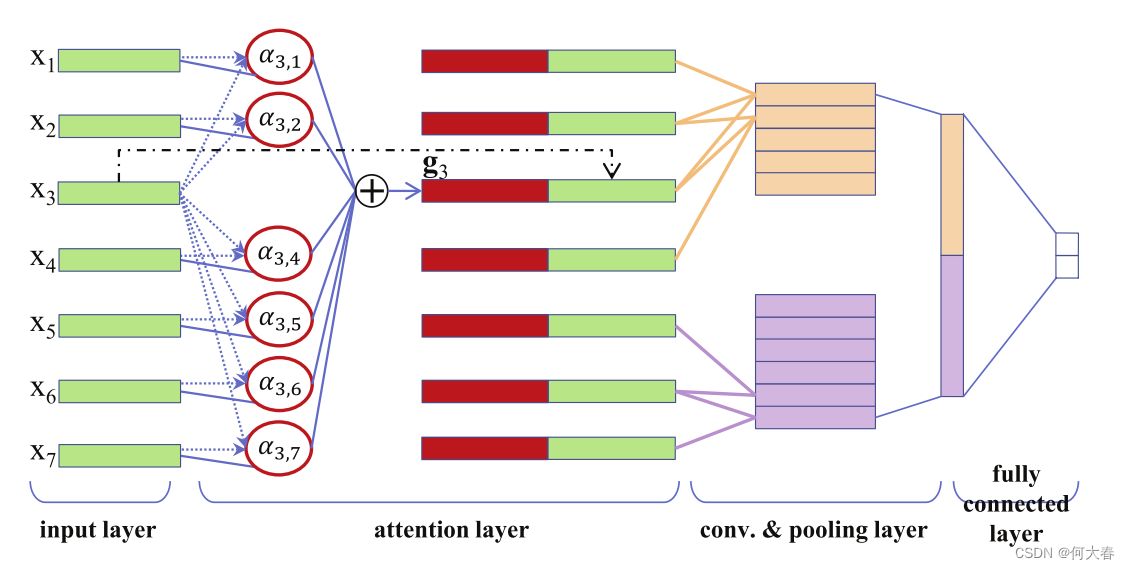
图1:ATT-CNN架构。在注意力层中,虚线对应于方程(4)-(5),实线对应于方程(3),虚点线是复制操作。
图1展示了我们提出的ATT-CNN模型的架构。正如图1所示,我们在输入层和卷积层之间引入了一个注意力层。具体来说,注意力层用于为每个词创建一个上下文向量。上下文向量与词向量连接在一起,作为新的词表示,然后输入到卷积层中。直观地说,两个相距较远的词往往联系较少。因此,我们在注意力机制中添加了距离衰减。
注意力机制的思想是在推导出词向量
x
i
\mathbf{x}_i
xi 的上下文向量
g
i
\mathbf{g}_i
gi 时学习将注意力集中在特定的重要词上。图1中的红色矩形代表
g
i
\mathbf{g}_i
gi。注意力机制是一个额外的多层感知机(MLP),与ATT-CNN的所有其他组件一起进行联合训练。该机制确定了在预测句子类别时,哪些词应该比其他词更受关注。得分的词被组合成加权和:
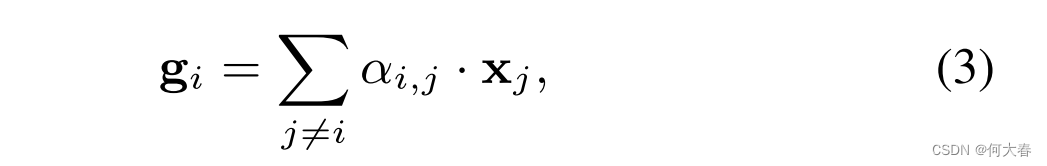
其中,
α
i
,
j
\alpha_{i,j}
αi,j 被称为注意力权重,我们要求
α
i
,
j
⩾
0
\alpha_{i,j}\geqslant0
αi,j⩾0,并且通过 softmax 归一化使得
∑
j
α
i
,
j
=
1
\sum_j\alpha_{i,j}=1
∑jαi,j=1。描述注意力机制的方程式如下:
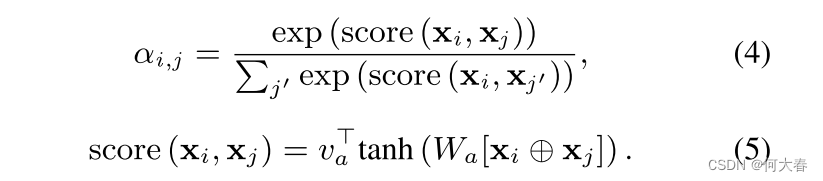
其中,得分值是由上面提到的 MLP 计算的。简单来说,我们使用这个 MLP 来建模词对
(
x
i
,
x
j
,
j
≠
i
)
(\mathbf{x}_i,\mathbf{x}_{j,j\neq i})
(xi,xj,j=i) 的相关性。那些具有较大得分的
x
j
,
j
≠
i
\mathbf{x}_{j,j\neq i}
xj,j=i 在上下文向量
g
i
\mathbf{g}_i
gi 中具有更大的权重。
以情感分类中的以下句子为例:
There’s not one decent performance from the cast and not one clever line ofdialogue.
当我们学习该句子中单词 “performance” 的上下文向量时,注意机制会更多地关注单词 “not” 和 “decent”。特别地,预期 score(performance, not) 和 score(performance, decent) 要大于其他单词对。
此外,我们引入一个衰减因子 λ ∈ [0, 1) 作为惩罚,以减少随着句子长度增长而产生的噪声信息的影响。
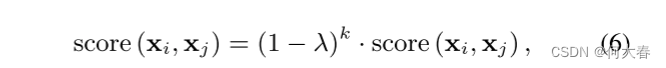
其中,
k
=
∣
j
−
i
∣
−
1
k=|j-i|-1
k=∣j−i∣−1。当我们将 λ 设定为接近 0 时,将考虑更广泛范围内的上下文;而如果我们增加 λ 使其接近 1,则只有局部范围内的上下文会被考虑。
最后,我们将扩展的单词向量
x
i
′
\mathbf{x}_i^{\prime}
xi′ 定义为
x
i
\mathbf{x}_i
xi 和其上下文向量的连接,然后使用
x
i
′
\mathbf{x}_i^{\prime}
xi′ 更新句子矩阵
A
\mathbf{A}
A,该矩阵将被馈送到 CNN 中,如第 2.1 节所述。
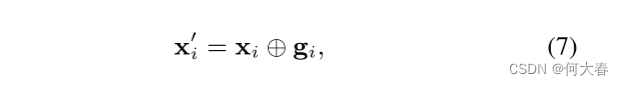
3. Experiments
3.1. Datasets
我们在各种公共数据集和内部数据集上进行了实验。
TREC [2]:一个问题分类数据集,包含5952个句子,被分类为6个粗粒度类别,分别是缩写、实体、描述、人类、位置和数字。
TREC2 [2]:它包含与TREC相同的句子,但标注了50个细粒度类别,如numeric:temperature(数值:温度)、numeric:distance(数值:距离)和entity:vehicle(实体:车辆)。
SST(斯坦福情感树库)[25]:这是一个电影评论情感语料库,包含11,855个句子,标注有5个标签,分别是非常负面、负面、中性、正面和非常正面。
SLU-UI:这是我们内部用于语音语义理解(SLU)中用户意图分类的数据集。该语料库是通过众包收集的,确保了收集到的话语与口语相似。该数据集包含13,211个句子,涵盖了6个领域(如短信、电话、闹钟、时钟等),以及25个用户意图类别,包括发送短信、打电话、闹钟开启、时钟查看时间等。训练集包含11,875个句子,测试集包含1,336个句子。
我们将我们的模型与基本CNN [14](仅利用连续词嵌入的模型)、将连续n-gram卷积替换为依赖n-gram卷积的变体DCNN [15]以及TBCNN [16]进行了比较。此外,我们还将我们的模型与三种基于递归的方法和两种基于循环的模型进行了比较:基于递归的模型包括RNN [6]、RNTN [25]和DRNN [26]。基于循环的模型包括Tree-LSTM [9]和S-LSTM [10]。在SLU-UI数据集上,我们将我们的模型与基本CNN [14]和DCNN [15]进行了比较。我们使用了斯坦福依赖解析器 [28] 对DCNN进行评估。由于时间限制,我们没有对Recursive NN和Recurrent NN进行测试。
我们使用了公开可用的word2vec和GloVe词嵌入,它们的维度均为300。word2vec是使用连续词袋结构从Google News的100B个单词中训练得到的。GloVe是使用Common Crawl的840B个标记进行训练的。不在词嵌入中的词被随机初始化。为了正则化,我们采用了以下两种方式:(1)在全连接层上采用随机丢弃 [31]。 (2)应用L2范数惩罚。训练是通过对打乱的小批量数据进行随机梯度下降,使用Adadelta更新规则完成的。
3.2. Results and Discussions
公开数据集上的结果如表1所示,我们可以观察到:(1)我们的ATT-CNN在SST数据集上与Recursive NN、Recurrent NN和DCNN表现相当,并且在TREC和TREC2数据集上表现与DCNN和TBCNN相当,尽管我们的模型不使用其他模型所需的任何外部句法信息。(2) 由于注意力机制,我们的ATT-CNN在所有数据集上明显优于基本CNN。(3) 我们目前所知道的TREC和SST上最好的结果分别是96.0%和51.4%,是由TBCNN [16]得到的。然而,他们的模型需要将句子解析成句法树作为输入,并且具有非常复杂的结构。我们的模型在远低于复杂度的情况下取得了与最先进结果相当的性能。
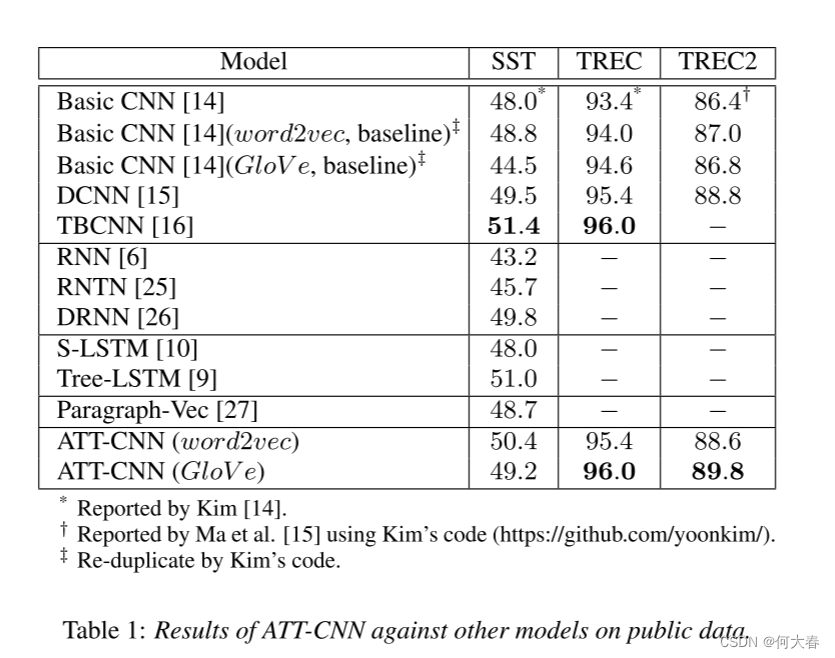
表1:ATT-CNN在公共数据上与其他模型的结果。
在SLU-UI数据集上,我们将提出的ATT-CNN与基本CNN和DCNN进行了比较,如表2所示。正如我们预期的那样,我们的模型在与基本CNN的比较中取得了更好的性能。但是与DCNN相比,ATT-CNN在使用word2vec时胜出,但在使用GloVe时失败了。结果表明:(1)DCNN和ATT-CNN都优于基线,这表明非连续词的信息在SLU中也很重要。(2) 由于我们的SLU-UI语料库中不包含许多难以进行依赖解析的非流畅话语,所以DCNN表现相当不错。(3) ATT-CNN与DCNN相比仍然具有竞争力,因为ATT-CNN不需要额外的信息。
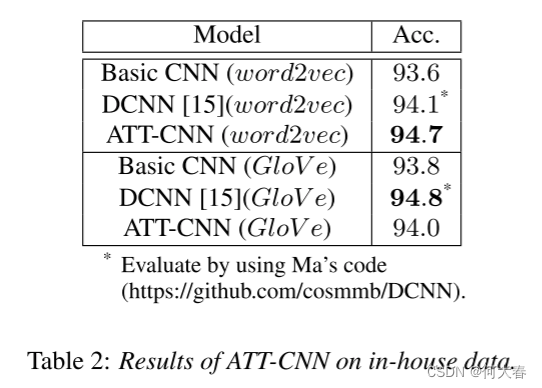
表2:ATT-CNN在内部数据上的结果。
3.2.1. Effect ofdistance decay
本节介绍了在TREC和SST数据集上应用距离衰减的效果,如图2所示。可以很容易地发现,距离衰减λ在这两个数据集上的表现不同。我们认为,在TREC数据集上,随着λ的增长,性能下降的原因是由于TREC句子的平均长度仅为10个词,句子中的单词之间关系更密切,设置小的λ值可以使模型考虑到更广泛的上下文范围。但是在SST数据集上,更长的句子长度(平均19个词)表明一个句子中单词之间的关系并不像在TREC中那样紧密,因此通过略微增加λ来缩小上下文范围可以提高性能。但是我们可以看到,持续增加λ也会导致性能下降,因为只考虑了局部上下文。
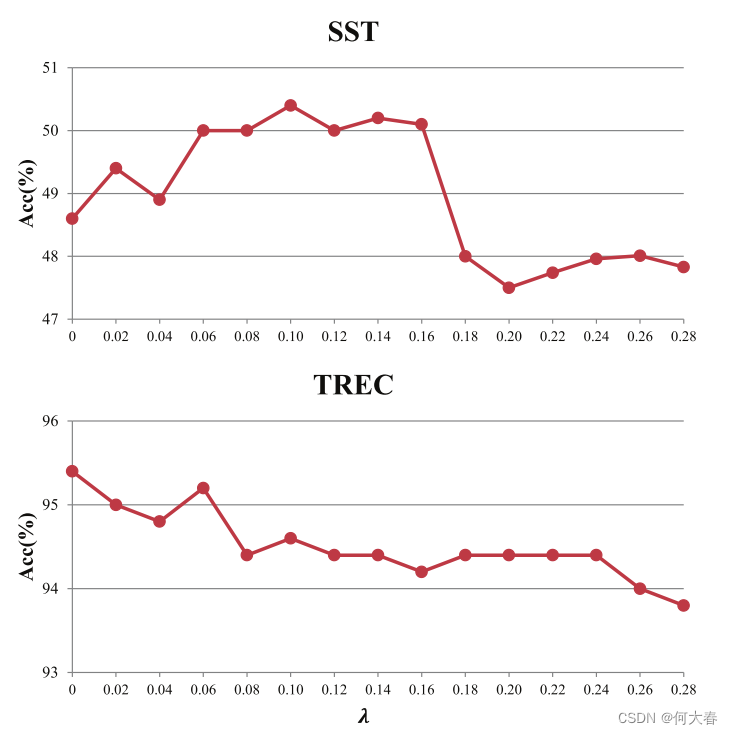
图2:距离衰减。
3.2.2. Visualization ofattention
图3和4显示了SST和TREC的注意力可视化结果。矩阵的每一行表示一个α向量,单元格越暗,表示对相应列的单词放置的注意力越多。如图3所示,负面情绪模式“not … decent”和“not … clever”在句子的前两部分非常显著。在图4(a)中,典型的描述模式“what … do”被注意力模型评分最高。在图4(b)中,单词“flower”得到更多的关注,是一个强烈的实体类别(ENTY)指示,在图4©中,典型的位置词“habitat”得到更多的关注。从图3和4可以得出结论,一对单词 ( x i , x j , j ≠ i ) (x_i, x_j, j≠i) (xi,xj,j=i)的相关性可以被认为是 x i x_i xi依赖于 x j , j ≠ i x_j, j≠i xj,j=i来指示相应句子类别的程度。
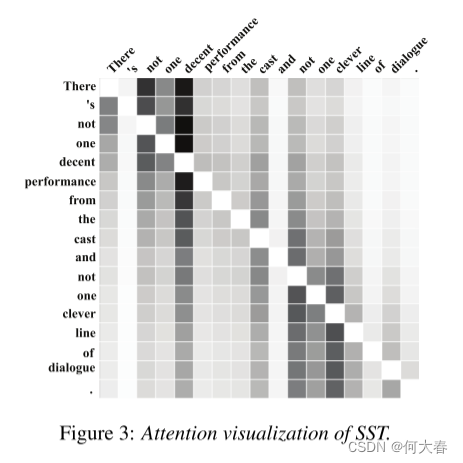
Figure 3: SST的注意力可视化。
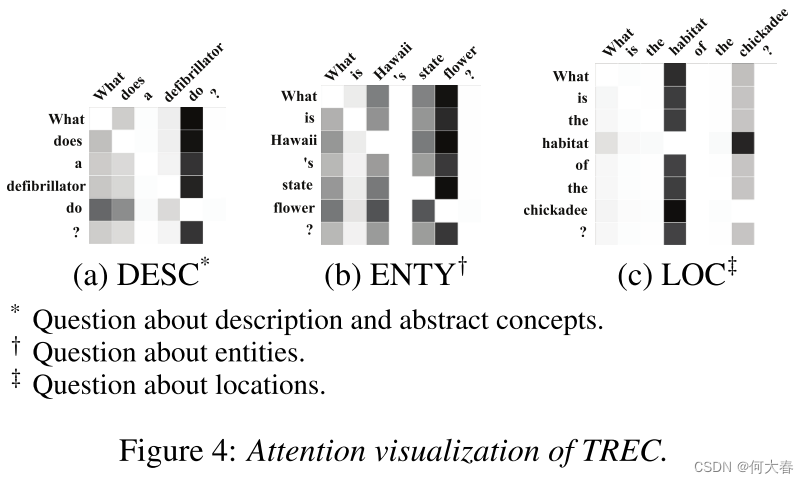
Figure 4: TREC的注意力可视化。
4. Conclusion
我们在基本CNN中引入了注意力机制,以建模句子内单词之间的关联,并提出了ATT-CNN模型。我们的模型能够在不使用任何句法信息的情况下捕捉长期上下文信息和非连续单词之间的关联。实验证明,我们的模型明显优于基本CNN,在各种数据集上实现了与递归和NNs竞争性的性能。
目前我们只考虑单词对之间的注意力,未来的工作中我们将考虑将更丰富的信息纳入注意力机制中。
阅读总结
有nlp作业的可以看看,我也是来找作业代码的,用这个代码跑一下作业数据集试试,能用再来更新。

















 2402
2402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









