







 多元线性回归是一种统计分析方法,用于研究自变量X和因变量Y之间的线性关系。本文详细介绍了线性回归的基本概念、模型设定、数据类型、回归方程、误差项假设以及内生性问题。此外,还探讨了异方差性、多重共线性、逐步回归分析等关键概念,并提供了STATA实现回归分析的实例。
多元线性回归是一种统计分析方法,用于研究自变量X和因变量Y之间的线性关系。本文详细介绍了线性回归的基本概念、模型设定、数据类型、回归方程、误差项假设以及内生性问题。此外,还探讨了异方差性、多重共线性、逐步回归分析等关键概念,并提供了STATA实现回归分析的实例。
多元线性回归分析
回归分析是数据分析中最基础也是最重要的分析工具,绝大多数的数据分析问题,都可以使用回归的思想来解决。回归分析的任务就是,通过研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的。
常见的回归分析有五类:线性回归、0‐1回归、定序回归、计数回归和生存回归,其划分的依据是因变量Y的类型。本讲主要学习线性回归。
多元线性回归分析
- 相关性
通过回归分析,研究相关关。相关性不等于因果性。 - X
X是用来解释Y的相关变量,所以X被称为自变量。 - Y
Y常常是我们需要研究的那个核心变量,称为因变量。
数据的分类
| 数据类型 | 解释 | 举例 | 建模方法 |
|---|---|---|---|
| 横截面数据 | 在某一时点收集的不同对象的数据 | 我们自己发放问卷得到的数据、全国各省份2018年GDP的数据、大一新生今年体测的得到的数据 | 多元线性回归 |
| 时间序列数据 | 对同一对象在不同时间连续观察所取得的数据 | 从出生到现在,你的体重的数据(每年生日称一次)、中国历年来GDP的数据、在某地方每隔一小时测得的温度数据 | 移动平均、指数平滑、ARIMA、GARCH、VAR、协积 |
| 面板数据 | 横截面数据与时间序列数据综合起来的一种数据资源 | 2008‐2018年,我国各省份GDP的数据 | 固定效应和随机效应、静态面板和动态面板 |
回归分析的分类
| 类型 | 模型 | Y的特点 | 例子 |
|---|---|---|---|
| 线性回归 | OLS、GLS(最小二乘) | 连续数值型变量 | GDP、产量、收入 |
| 0-1回归 | logistic回归 | 二值变量 | 是否违约、是否得病 |
| 定序回归 | probit定序回归 | 定序变量 | 等级评定(优良差) |
| 计数回归 | 泊松回归(泊松分布) | 计数变量 | 每分钟车流量 |
| 生存回归 | Cox等比例风险回归 | 生存变量(截断数据) | 企业、产品的寿命 |
一元线性回归
- 回归模型
只涉及一个自变量的回归称为一元回归,描述两个具有线性关系的变量之间关系的方程称为回归模型,一元线性回归模型可表示为:
y i = β 0 + β 1 x i + μ i y_i=\beta_0+\beta_1x_i+\mu_i yi=β0+β1xi+μi
其中 μ \mu μ是被称为误差项的随机变量,反映了变量线性关系外的随机因素对y的影响。
上式称为理论回归模型,对它有以下假定:
- y与x之间具有线性关系;
- x是非随机的,在重复抽样中,x的取值是固定的;
以上2个假定表明,对于任何一个给定的x的值,y的取值都对应着一个分布,代表一条直线。但由于单个y是从y的分布中抽出来的,可能不在这条直线上,因此,必须包含一个误差项。 - 误差项是一个期望值为0的随机变量,因此,对于一个给定的x值,y的期望
E
(
y
)
=
β
0
+
β
2
x
E(y)=\beta_0+\beta_2x
E(y)=β0+β2x值。
- 对于所有的x, μ \mu μ的方差 σ \sigma σ都相同,这意味着对于一个给定的x值,y的方差都等于 σ 2 \sigma^2 σ2。
- 误差项是一个服从正态分布的随机变量,且独立。一个特定的x值所对应的与其他x值对应的不相关。对于任何一个给定的x值,y都服从期望值为 β 0 + β 1 x \beta_0+\beta_1x β0+β1x方差为 σ 2 \sigma^2 σ2的正态分布,不同的x值,y的期望值不同,但方差相同
扰动项需要满足的条件
y i = β 0 + β 1 x i + μ i y_i=\beta_0+\beta_1x_i+\mu_i yi=β0+β1xi+μi
满足球型扰动项,即满足“同方差”和“无自相关”两个条件。
这里注意,横截面数据容易出现异方差的问题,时间序列数据容易出现自相关的问题。
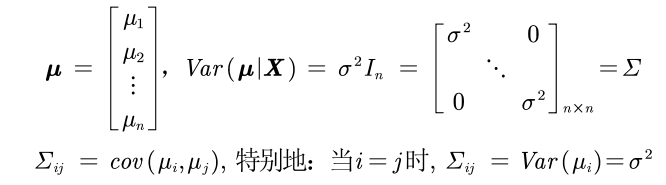
- 回归方程
描述y的期望值如何依赖自变量x的方程称为回归方程,一元线性回归方程(误差项的期望值为0)的形式为:
E ( y ) = β 0 + β 2 x E(y)=β_0+β_2x E(y)=β0+β2x - 估计的回归方程
总体回归参数 β 0 β_0 β0和 β 1 β_1 β1是未知的,需要用样本数据去估计。一元线性回归的估计的回归方程形式为:
y ^ = β ^ 0 + β ^ 1 x \hat y=\hat\beta_0+\hat\beta_1x y^=β^0+β^1x
- 对于“线性”的理解
不要求严格的线性,只要有线性的形式即可。
如下,都属于“线性”。
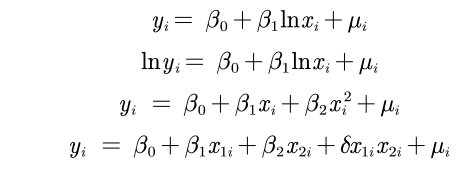
内生性的探究
误差 μ \mu μ包含了所有与 y y y相关,但未添加到回归模型中的变量。如果这些变量和我们已经添加的自变量相关,则存在内生性。
蒙特卡罗模拟
%% 蒙特卡洛模拟:内生性会造成回归系数的巨大误差
times = 300; % 蒙特卡洛的次数
R = zeros(times,1); % 用来储存扰动项u和x1的相关系数
K = zeros(times,1); % 用来储存遗漏了x2之后,只用y对x1回归得到的回归系数
for i = 1: times
n = 30; % 样本数据量为n
x1 = -10+rand(n,1)*20; % x1在-10和10上均匀分布,大小为30*1
u1 = normrnd(0,5,n,1) - rand(n,1); % 随机生成一组随机数
x2 = 0.3*x1 + u1; % x2与x1的相关性不确定, 因为我们设定了x2要加上u1这个随机数
% 这里的系数0.3我随便给的,没特殊的意义,你也可以改成其他的测试。
u = normrnd(0,1,n,1); % 扰动项u服从标准正态分布
y = 0.5 + 2 * x1 + 5 * x2 + u ; % 构造y
k = (n*sum(x1.*y)-sum(x1)*sum(y))/(n*sum(x1.*x1)-sum(x1)*sum(x1)); % y = k*x1+b 回归估计出来的k
K(i) = k;
u = 5 * x2 + u; % 因为我们回归中忽略了5*x2,所以扰动项要加上5*x2
r = corrcoef(x1,u); % 2*2的相关系数矩阵
R(i) = r(2,1);
end
plot(R,K,'*')
xlabel("x_1和u'的相关系数")
ylabel("k的估计值")

表明x与
μ
\mu
μ关系越大,内生性越强。
核心解释变量和控制变量
无内生性(no endogeneity)要求所有解释变量均与扰动项不相关,这个条件一般很难达到,因此我们对于变量作以下两种分类
核心解释变量:我们最感兴趣的变量,因此我们特别希望得到对其系数的一致估计(当样本容量无限增大时,收敛于待估计参数的真值 )。
控制变量:我们可能对于这些变量本身并无太大兴趣。而之所以把它们也放入回归方程,主要是为了 “控制住” 那些对被解释变量有影响的遗漏因素。
在实际应用中,我们只要保证核心解释变量与𝝁不相关即可。
回归系数的解释
一元线性回归
y
=
a
+
b
x
+
μ
y=a+bx+\mu
y=a+bx+μ
β
0
^
\hat{\beta_0}
β0^ : 一般不考虑(所有变量都是0才有意义)
β m ^ ( m = 1 , 2... k ) \hat{\beta_m}(m=1,2...k) βm^(m=1,2...k) :在控制了其他变量的情况下, x m i x_{mi} xmi每增加一个单位,对 y i y_i yi造成的变化。
半对数模型1
y = a + b l n x + μ y=a+blnx+\mu y=a+blnx+μ
什么时候取对数
- 与市场价值相关的,例如,价格、销售额、工资等都可以取对数;
- 以年度量的变量,如受教育年限、工作经历等通常不取对数;
- 比例变量,如失业率、参与率等,两者均可;
- 变量取值必须是非负数,如果包含0,则可以对y取对数ln(1+y);
取对数的好处
- 减弱数据的异方差性
- 如果变量本身不符合正态分布,取了对数后可能渐近服从正态分布
- 模型形式的需要,让模型具有经济学意义。
x每增加1%,y平均变化b/100个单位。
半对数模型2
l
n
y
=
a
+
b
x
+
μ
lny=a+bx+\mu
lny=a+bx+μ
x每增加1个单位,y平均变化(100b)%。
双对数模型
l
n
y
=
a
+
b
l
r
n
x
+
μ
lny=a+blrnx+\mu
lny=a+blrnx+μ
x每增加1%,y平均变化b%
虚拟变量
- 如果自变量中有定性变量,例如性别、地域等,在回归中转化为0-1表示
- 为了避免完全多重共线性的影响,引入虚拟变量的个数一般是分类数减1。
数据的描述性统计
stata 实现
- 定量数据 :
summarize 变量1 变量2 ... 变量n - 定性数据 :
tabulate 变量名,gen(A)
返回对应的这个变量的频率分布表,并生成对应的虚拟变量(以A开头)。gen以后的不写也可以
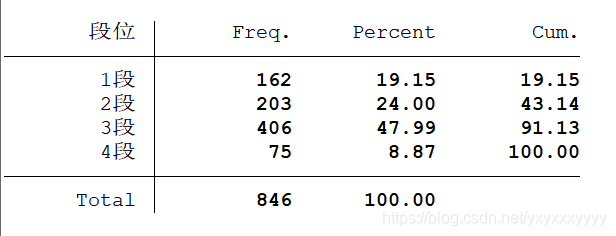
- Freq 频数
- Percent 频率
- Cum 累积频率
Excel实现
回归实现
STATA语句 : regress y x1 x2 … xk
- 默认使用的OLS:普通最小二乘估计法)
- 如果假如虚拟变量 STATA会自动检测数据的完全多重共线性
- 不带虚拟变量的
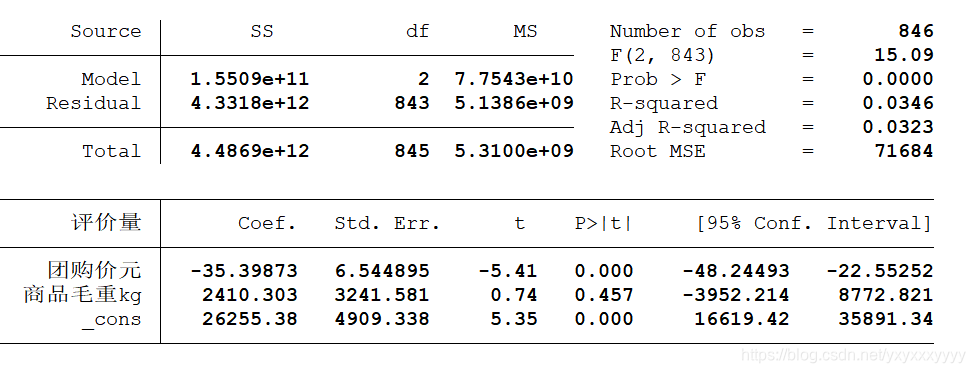
- Model + SS :SSR回归平方和
- Residual +SS : SSE误差平方和
- Total + SS :SST=SSR+SSE
- df : 自由度
- MS :ss/df
- F&&Prob>F : 联合显著性检验。 H 0 : β 1 = β 2 = . . . β k = 0 H_0 : \beta_1=\beta_2=...\beta_k=0 H0:β1=β2=...βk=0
- R 2 a n d a d j R 2 R^2 and adj R^2 R2andadjR2 :一般使用调整后的
- _cons : 常数项
- H 0 : β 1 = β 2 = . . . β k = 0 H_0 : \beta_1=\beta_2=...\beta_k=0 H0:β1=β2=...βk=0
- 带虚拟变量的
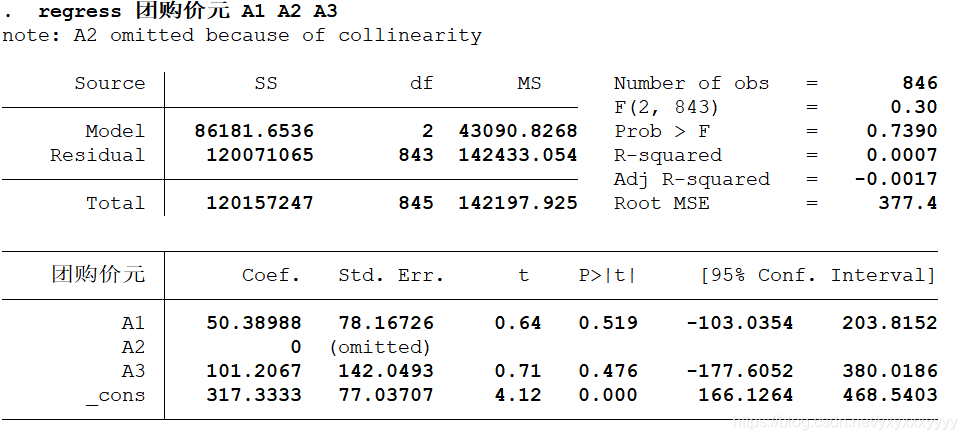
避免多重共线性,把一个固定(为0), 其余的数值是与它作比较。
拟合优度 R 2 R^2 R2较低怎么办
- 回归分为解释型回归和预测型回归。
预测型回归一般才会更看重 R 2 R^2 R2。解释型回归更多的关注模型整体显著性以及自变量的统计显著性和经济意义显著性即可。- 可以对模型进行调整,例如对数据取对数或者平方后再进行回归。
- 数据中可能有存在异常值或者数据的分布极度不均匀。
- 我们引入的自变量越多,拟合优度会变大。但我们倾向于使用调整后的拟合优度,如果新引入的自变量对SSE的减少程度特别少,那么调整后的拟合优度反而会减小。
标准化回归
标准化回归系数
为了去除量纲的影响,我们可使用标准化回归系数。
对数据进行标准化,就是将原始数据减去它的均数后,再除以该变量的标准差,计算得到新的变量值,新变量构成的回归方程称为标准化回归方程,回归后相应可得到标准化回归系数。标准化系数的绝对值越大,说明对因变量的影响就越大(只关注显著的回归系数)
Stata标准化回归命令
regress y x1 x2 … xk,beta
bata可简写为b
- 常数项没有标准化回归系数
常数的均值是其本身,经过标准化后变成了0。
-除了多了标准化回归系数 ,和之前的回归结果完全相同。
对数据进行标准化处理不会影响回归系数的标准误,也不会影响显著性。
异方差
- 危害
当扰动项存在异方差时 : - OLS估计出来的回归系数是无偏、一致的。
- 假设检验无法使用(构造的统计量失效了)。
- OLS估计量不再是最优线性无偏估计量(BLUE)。
- 检验(by stata)
\\在回归结束后运行命令:
rvfplot \\(画残差与拟合值的散点图)
rvpplot x \\(画残差与自变量x的散点图)
estat hettest ,rhs iid\\异方差bp检验
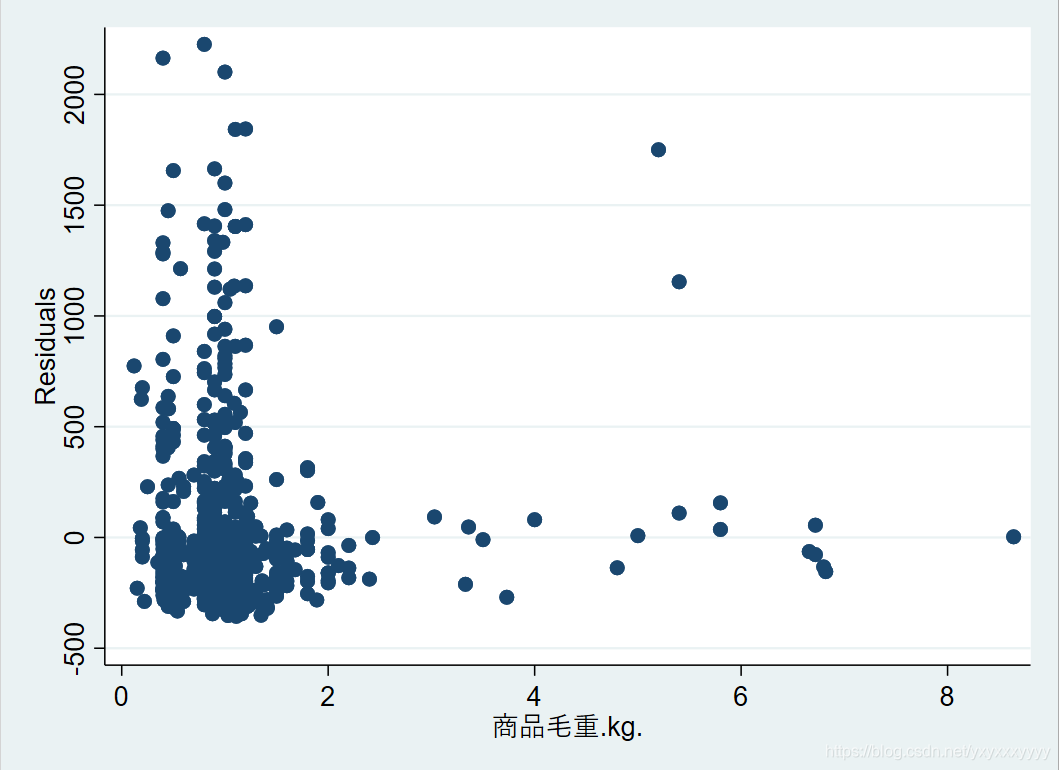
波动比较大,表示存在异方差
- BP检验
- 原假设 : 扰动项不存在异方差
- 备选假设 :扰动项存在异方差
- 解决方案
- 使用OLS + 稳健的标准误
如果发现存在异方差,一 种处理方法是,仍然进行OLS 回归,但使用稳健标准误。只要样本容量较大,即使在异方差的情况下,若使用稳健标准误,则所 有参数估计、假设检验均可照常进行。
regress y x1 x2 … xk,robust
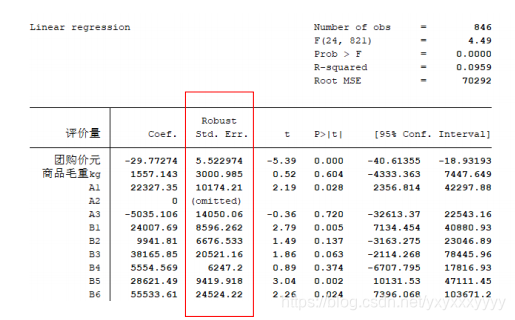
Stock and Watson (2011)推荐,在大多数情况下应该使用“OLS + 稳健标准误”。
2. 广义最小二乘估计法GLS(有缺陷)
原理:方差较小的数据包含的信息较多,我们可以给予信息量大的数据更大的权重(即方差较小的数据给予更大的权重)
多重共线性
多重线性回归,也即通过 X 1 X_1 X1, X 2 X_2 X2等多个自变量(解释变量)来构建线性回归模型预测因变量 Y Y Y。在多重线性回归中,当多个自变量之间存在 精确/高度 相关关系时,会导致回归系数难以估计/估计不准,这时就出现了共线性问题。
- 检验多重共线性
VIF,VarianceInflation Factor,方差膨胀因子。VIF指的是解释变量之间存在多重共线性时的方差与不存在多重共线性时的方差之比,可以反映多重共线性导致的方差的增加程度。
V I F m VIF_m VIFm越大,说明第 m m m个变量和其他变量的相关性越大,回归模型的 V I F = m a x { V I F 1 , V I F 2 , . . . , V I F K } VIF=max\{VIF_1,VIF_2,...,VIF_K\} VIF=max{VIF1,VIF2,...,VIFK}
一般 V I F > 10 VIF>10 VIF>10认为回归方程存在严重的多重共线性。
\\Stata计算各自变量VIF的命令(在回归结束后使用):
estat vif
- 如果不关心具体的回归系数,而只关心整个方程预测被解释变量的能力,则通常可以 不必理会多重共线性(假设你的整个方程是显著的)。这是因为,多重共线性的主要后果是使得对单个变量的贡献估计不准,但所有变量的整体效应仍可以较准确地估计。
- 如果关心具体的回归系数,但多重共线性并不影响所关心变量的显著性,那么也可以不必理会。即使在有方差膨胀的情况下,这些系数依然显著;如果没有多重共线性,则只会更加显著。
- 如果多重共线性影响到所关心变量的显著性,则需要增大样本容量,剔除导致严重共线性的变量(不要轻易删除,因为可能会有内生性的影响),或对模型设定进行修改。
- 逐步回归分析
- 向前逐步回归Forward selection:将自变量逐个引入模型,每引入一个自变量后都要进行检验,显著时才加入回归模型。
(缺点:随着以后其他自变量的引入,原来显著的自变量也可能又变为不显著了,但是,并没有将其及时从回归方程中剔除掉。) - 向后逐步回归Backward elimination:与向前逐步回归相反,先将所有变量均放入模型,之后尝试将其中一个自变量从模型中剔除,看整个模型解释因变量的变异是否有显著变化,之后将最没有解释力的那个自变量剔除;此过程不断迭代,直到没有自变量符合剔除的条件。
(缺点:一开始把全部变量都引入回归方程,这样计算量比较大。若对一些不重要的变量,一开始就不引入,这样就可以减少一些计算。当然这个缺点随着现在计算机的能力的提升,已经变得不算问题了) - Stata实现逐步回归法
\\向前逐步回归Forward selection: stepwise regress y x1 x2 … xk, pe(#1) \\向后逐步回归Backward elimination: stepwise regress y x1 x2 … xk, pr(#2)- pe(#1) specifies the significance level for addition to the model; terms with p<#1 are eligible for addition(显著才加入模型中).
- pr(#2) specifies the significance level for removal from the model; terms with p>= #2 are eligible for removal(不显著就剔除出模型)
- 向前逐步回归Forward selection:将自变量逐个引入模型,每引入一个自变量后都要进行检验,显著时才加入回归模型。
- 如果你筛选后的变量仍很多,可以减小#1或者#2;如果筛选后的变量太少了,可以增加#1或者#2。
- x 1 x 2 … x k x_1 x_2 … x_k x1x2…xk之间不能有完全多重共线性(和regress不同哦)
- 可以在后面再加参数b和r,即标准化回归系数或稳健标准误
-向前逐步回归和向后逐步回归的结果可能不同。- 不要轻易使用逐步回归分析,因为剔除了自变量后很有可能会产生新的问题,例如内生性问题。

















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









