






Hybrid Transfer Learning and Broad Learning System for Wearing Mask Detection in the COVID-19 Era
- 在本文中,提出了一种使用混合机器学习技术来检测戴口罩的两阶段方法。第一阶段基于fast_rcnn和InceptionV2结构的迁移模型,尽可能多地检测候选口罩佩戴区域,第二阶段使用广义学习系统验证真实口罩。它通过训练一个两类模型来实现。
INTRODUCTION
-
本文的目的是设计一种方法来检测戴口罩的人。给定一个输入图像,通过开发的深度迁移学习模型和广义学习系统(BLS)在输出图像中标记佩戴面具的区域。
-
为了实现这一目标,必须解决一些问题。
- 第一个问题是,口罩有各种各样的风格,如方向和随机噪声。它很容易导致面部特征的缺乏,甚至导致最先进的面部检测算法或模型的失败。
- 虽然已经为人脸检测创建了许多人脸数据集,但仍然缺乏现实场景中佩戴口罩检测(WMD)的数据集。
-
本文主要贡献有以下几点
- 本文提出了两阶段方法。探索了fast_rcnn框架,使用InceptionV2作为预检测阶段,并使用BLS作为验证阶段。通过两个阶段的组合,验证了该方法的有效性。
- 从抗击大流行的场景中创建了一个新的数据集。
RELATED WORK
Facial Mask Detection Methods
- 使用手工特征进行人脸检测
- haar-like特征,它可以通过AdaBoost算法训练来进行人脸检测。
- 基于卷积神经网络(cnn)的深度学习方法
- lle - cnn
- RetinaFaceMask
- 迁移学习方法来检测带口罩的人脸。
- 利用深度学习架构来检测面具和面孔,并将其应用于闭路电视系统,以帮助当局采取必要的行动。
- 混合的深度迁移学习模型和机器学习方法检测带口罩的人脸
- 结合图像超分辨率和分类网络作为一种新的口罩佩戴识别方法
- 使用VGG16结构进行口罩和物理距离检测
- 利用ResNet-50和YOLOv2技术训练用于医用蒙面检测的模型
- 本文中,主要关注的是 wearing mask detection (WMD) 。
Related Data Sets
- 目前的数据集大多是由简单的场景或合成而来,在一定程度上缺乏标签或真实感。在本文中,我们创建了一个带标签的数据集,原始图像来自抗击COVID-19的真实场景。大多数图像都有不同的大小和方向。
PROPOSED METHOD
- 该方法的流程图如图所示。
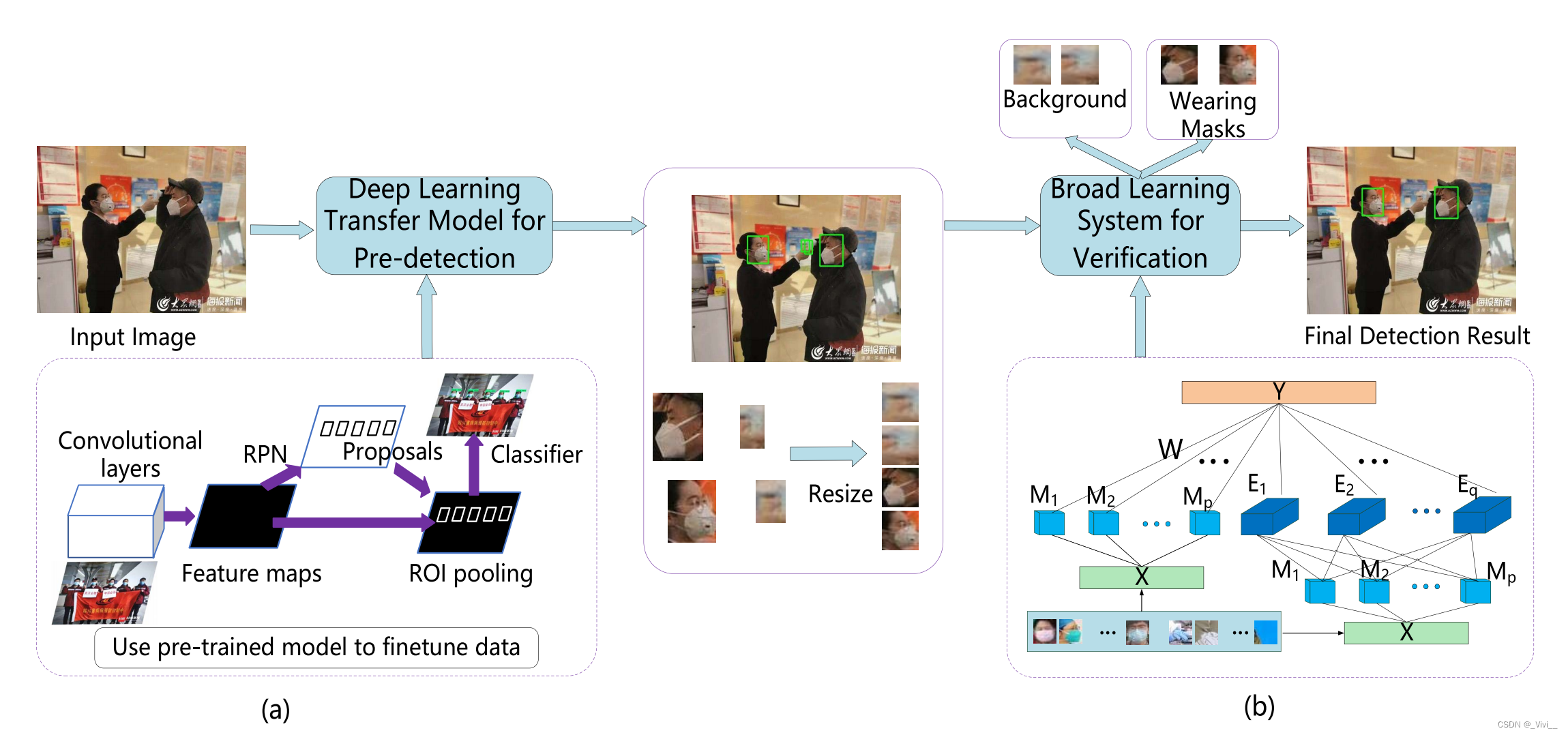
- 它包括两个阶段:预检测和验证。
- 第一阶段是使用训练好的Faster_RCNN模型来检测候选口罩
- 第二阶段是使用BLS训练好的分类器来去除背景区域。
Deep Transfer Learning Model for Predetection
- 开发了一个深度迁移学习模型,用于佩戴口罩的预检测。
- 戴口罩是感兴趣区域(ROI)。检测这些ROI需要一个能够提出准确和有效区域的模型。fast_rcnn框架引入的区域建议网络(RPN)可以提供一系列的候选区域。此外,该框架提供了一种强大的新方法,可以在简单的过程后生成区域及其分类分数。因此,它是一个很好的预检测模块。这一阶段的主要原则是尽可能多地定位ROI。
- 预检测分为四个步骤。通过四个步骤之后,许多候选区域都已生成。
- Feature map : 设计一系列卷积运算,然后是relu层和pooling层来提取特征映射。特征映射的最后一层将由后续RPN和ROI池化步骤使用。
- Generate Proposals : 由RPN实现,目的是生成足够的提案供选择,称为锚定生成器。图像的每个点都可以看作是一个锚点。
- RPN包括box-regression layer和box-classification layer。box-regression层的目标是调整提案的位置,而box-classification层的目标是确定一个box是属于对象还是背景。
- Obtain Fixed Dimension of Feature Map:这一步通过ROI-pooling来实现。它接收来自卷积层(步骤1)和RPN生成的建议(步骤2)的特征图,并通过最大池化操作从每个ROI生成固定大小的特征图。
- 它解决了后续分类和回归需要固定特征图的问题。特征图的固定尺寸从不依赖于输入大小;它仅仅取决于该层的参数。
- Object Classification and Location Regression:该步骤接收特征图的固定维度,输出类的概率。同时,使用bounding box regression得到盒的准确位置。最后生成预测对象及其位置。
- 图像的损失函数定义为
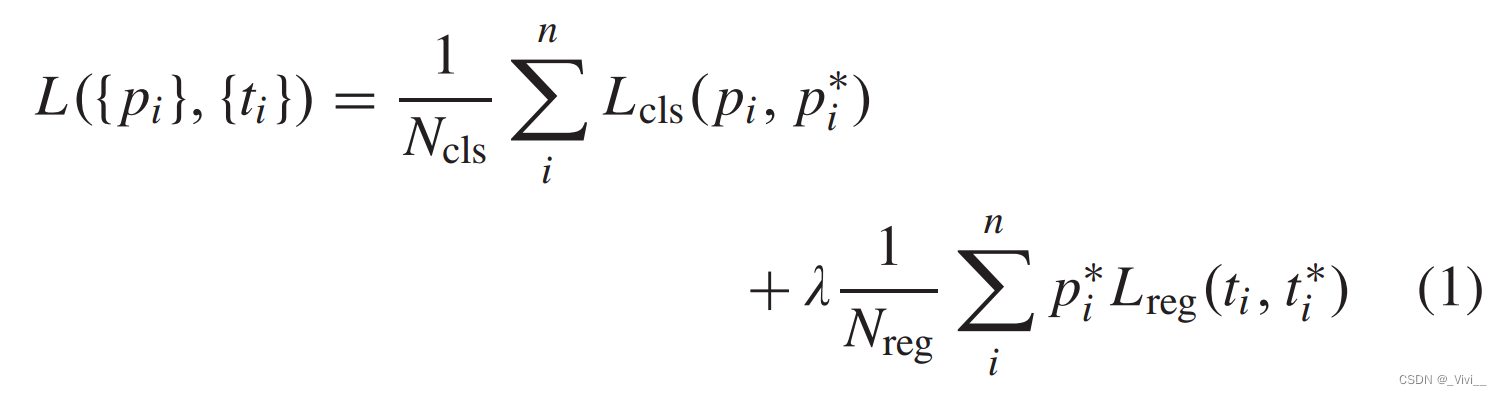
- 其中 i i i是锚的指数, p i p_i pi是预测的属于戴面具的概率。 p i ∗ p_i^* pi∗代表基本真理,如果锚点为正,则为1,如果锚点为负,则为0。 t i t_i ti是盒子的预测坐标, t i ∗ t_i^* ti∗是正锚的真实坐标。 L c l s L_{cls} Lcls是分类损失, L r e g L_{reg} Lreg是回归损失。 p i ∗ L r e g p^*_iL_{reg} pi∗Lreg表示只计算正锚点。分类损失和回归损失用 N c l s N_{cls} Ncls和 N r e g N_{reg} Nreg术语归一化。
- 表征瓶颈
- 当卷积网络降维过多时,可能会导致信息丢失,这被称为表征瓶颈。
- 为了解决这个问题,对Inception模块的基础上进行增强形成Inception v2。它旨在减少表征瓶颈,降低计算复杂度。
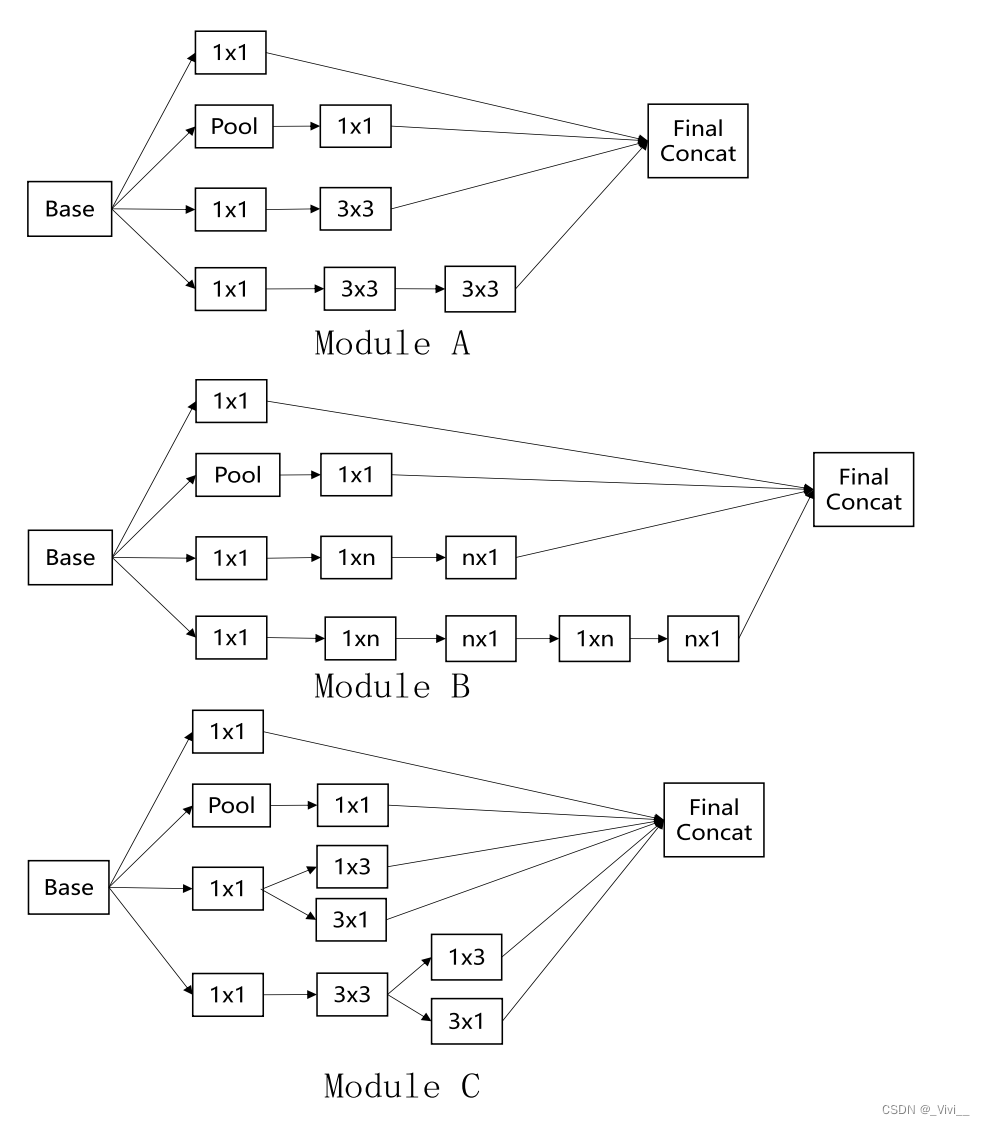
- 三个模块
- 模块A是将一个5 × 5的卷积分解为两个3 × 3的卷积,遵循空间聚集原理。它可以通过因数分解减少(5 × 5−(3 × 3 + 3 × 3)/5 × 5) = 28%的计算量,从而提高性能。
- 空间因子分解为非对称卷积是降低复杂性的另一种策略。模块B说明了n × n可以被1 × n和n × 1的组合分解。两层的解是(3 × 3−(1 × 3 + 3 × 1)/3 × 3) = 1层的解,比一层的解减少33%。
- 扩展了滤波器组以避免代表性瓶颈。它意味着更宽而不是更深,以促进高维表示,这有助于在网络内进行本地处理。
- 综上所述,预检测模型采用了图中的三个模块。
Broad Learning System for Verification
- 验证预检测结果
- 以平面神经网络的形式建立(BLS)。为了分类,首先将输入图像转换为“映射特征”形式的随机特征节点; 然后,将所有映射的特征以“增强特征”的形式扩展为特征节点。
- 其中,定义第
i
i
i组映射特征
M
i
=
φ
(
X
W
m
i
+
β
m
i
)
,
i
=
1
,
2
,
…
,
p
Mi = φ (XWmi + βmi), i = 1,2,…, p
Mi=φ(XWmi+βmi),i=1,2,…,p
- 其中 W m i W_{mi} Wmi和 β m i β_{mi} βmi是由指定分布随机生成的权重,其中 φ φ φ是映射函数。为了探索更多的基本特征,映射的特征通过稀疏自编码器进行微调。
- 经过一系列映射操作,生成了
p
p
p组映射的特征,可以用
M
p
≡
[
M
1
,
…
,
M
p
]
M^p≡[M_1,…,M_p]
Mp≡[M1,…,Mp]。然后,将所有处理后的特征扩展为增强特征
E
j
=
σ
(
M
p
W
e
j
+
β
e
j
)
,
j
=
1
,
2
,
…
,
q
E_j = σ (M^pW_{ej} + β_{ej}), j = 1,2,…,q
Ej=σ(MpWej+βej),j=1,2,…,q
- 其中 σ σ σ为非线性激活函数。 W e j W_{ej} Wej和 β e j β_{ej} βej被定义为由给定分布产生的权重。增强节点的前 q q q组 E q ≡ [ E 1 , … , E q ] E^q≡[E_1,…, Eq] Eq≡[E1,…,Eq]。
- 所有映射的特征和增强的特征共同连接到输出层
Y
=
[
M
1
,
M
2
,
…
,
M
p
,
E
1
,
E
2
,
…
,
E
q
]
W
=
[
M
p
∣
E
q
]
W
Y = [M_1, M_2,…, M_p, E_1, E_2,…, E_q]W = [M^p |E^q]W
Y=[M1,M2,…,Mp,E1,E2,…,Eq]W=[Mp∣Eq]W
- 其中 W W W为全网权重, Y Y Y表示输出。在实际应用中,参数 p p p和 q q q的选择取决于任务的复杂程度和计算成本的要求。
- 权值 W W W可由 W = [ M p ∣ E q ] + Y W=[M^p|E^q]^+Y W=[Mp∣Eq]+Y导出,其中 [ M p ∣ E q ] + [M^p|Eq]^+ [Mp∣Eq]+可由岭回归近似的伪逆计算。
- 增量学习
- 当设计好的BLS不能很好地学习任务时,一个有效的解决方案是添加映射特征或增强的功能。
- 当添加一个映射特征 M p + 1 = φ ( X W m p + 1 + β m p + 1 ) M_{p+1} = φ (XW_{m_{p+1}} + β_{m_{p+1}}) Mp+1=φ(XWmp+1+βmp+1)时,映射特征的级连就变成了 M p + 1 ≡ [ M 1 , … , M p + 1 ] M_{p+1}≡[M_1,…, M_{p+1}] Mp+1≡[M1,…,Mp+1]。
- 增强后的特征节点可以更新为
E
e
x
j
=
[
σ
(
M
p
+
1
W
e
x
j
+
β
e
x
j
)
,
…
,
σ
(
M
p
+
1
W
e
x
j
+
β
e
x
j
)
]
E^{ex_j}= [σ (M^{p+1}W_{ex_j} + β_{ex_j}),…,σ (M^{p+1}W_{ex_j} + β_{ex_j})]
Eexj=[σ(Mp+1Wexj+βexj),…,σ(Mp+1Wexj+βexj)]
- 其中 W e x j W_{ex_j} Wexj和 β e x j j = 1 , 2 , … , q β_{ex_j} j = 1,2,…,q βexjj=1,2,…,q是随机权重。
- 如果增加增强特征,则新的增强特征节点可表示为 E q + 1 = σ ( M p + 1 W e x q + 1 + β e x q + 1 ) E_{q+1} = σ(M^{p+1}W_{ex_{q+1}} + β_{ex_{q+1}}) Eq+1=σ(Mp+1Wexq+1+βexq+1)。

- 这次权重的更新使BLS的速度更快,保证了训练效率。这一特点使BLS具有对各种应用场景的灵活性和适应性。
EXPERIMENTAL RESULTS
- 比较的方法都是深度学习算法:MobileNet,一个叫做PaddlePaddle的商业软件和fast_rcnn两种型号:fast_rcnn - resnet50和fast_rcnn - inceptionv2和SSD-InceptionV2。
Wearing Mask Data Set
- 创建一个佩戴口罩的数据集,该数据集包括WMD数据集和佩戴口罩分类(WMC)数据集两部分。WMD被用来训练一个探测模型。WMC用于训练一个两类分类器。
- 在创建数据集的过程中有三个步骤。
- 首先,粗糙的图像是从新闻报道、视频和其他类似的小数据集中裁剪出来的。
- 其次,去除一些不良样本,只选取有面膜的样本。
- 第三,利用标签工具LabelImg对佩戴口罩的矩形位置进行标注。通过反复操作,生成7804张图像,26 403个标记掩码。
- 其中测试集根据任务难度分为DS1、DS2、DS3三个部分。
- WMC包括两个课程 : 戴口罩和背景。
Evaluation Metrics and Parameter Setting
-
交集over Union (IoU)通常用于比较predicted boxes 和 ground-truth boxes
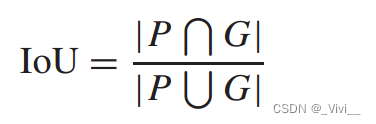
- 其中 P P P被定义为预测框, G G G被定义为真实框。 n n n是交集操作, U U U是并集操作。IoU的取值范围为 0 ≤ I o U ≤ 1 0≤IoU≤1 0≤IoU≤1,表示匹配置信度。
-
The metric IoU用于one box comparision。常用的指标包括用于统计分析的召回率、精度、F1和假率。
- TP表示被归类为戴口罩的阳性样本数量。FN表示被分类为背景的阳性样本的数量。FP表示被归类为戴口罩的阴性样本的数量

- TP表示被归类为戴口罩的阳性样本数量。FN表示被分类为背景的阳性样本的数量。FP表示被归类为戴口罩的阴性样本的数量
Quantitative Analysis
- 在本部分中,将在测试集DS1、DS2和DS3上进行实验。
- 实验结果中的Recall和F1的倾向都是下降对索引方法。它清楚地表明了DS1、DS2和DS3的难度级别由易到难。
- 三个测试集在实际应用中从大小、人群和变化的角度代表不同的场景,本文的方法取得了很好的效果。
- 时间比较
- 本文的方法用时最短
Visual Results and Discussion
- 如果图像中有人脸和戴面具的人,会同时检测到他们。
- 更重要的是,该方法有望与红外热成像测温技术相结合,保护公共服务专业人员和核酸检测免受密切接触者造成的COVID-19感染风险。
- 还扩展了正确佩戴口罩和不正确佩戴口罩的分类。如果检测到面部区域,将应用鼻子检测和嘴巴检测来预测是否有口罩,戴口罩是否正确。
- 但是,结果仍然存在一些失败。我们的方法很难处理小物体,面部几乎被防护服、口罩和医用护目镜保护着。功能不足可能是主要原因。解决这一问题的一个可能的方法是在现有方法的基础上应用图像超分辨率。
CONCLUSION
- 本文提出了一种混合的深度迁移学习和BLS用于口罩检测。
- 它的设计包括两个阶段:预检测和验证。通过迁移学习技术,fast_rcnn框架实现了预检测。检测模型是从一个多类检测模型调整而来的。验证由BLS的分类器实现。通过在预检测中设置较低的分数,可以使用更多的候选区域进行验证。















 2389
2389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









