






复现的Unet网络,得出的测试图是这样的:

而当我换成自己的数据集,训练完成后确是这样。
测试原图:
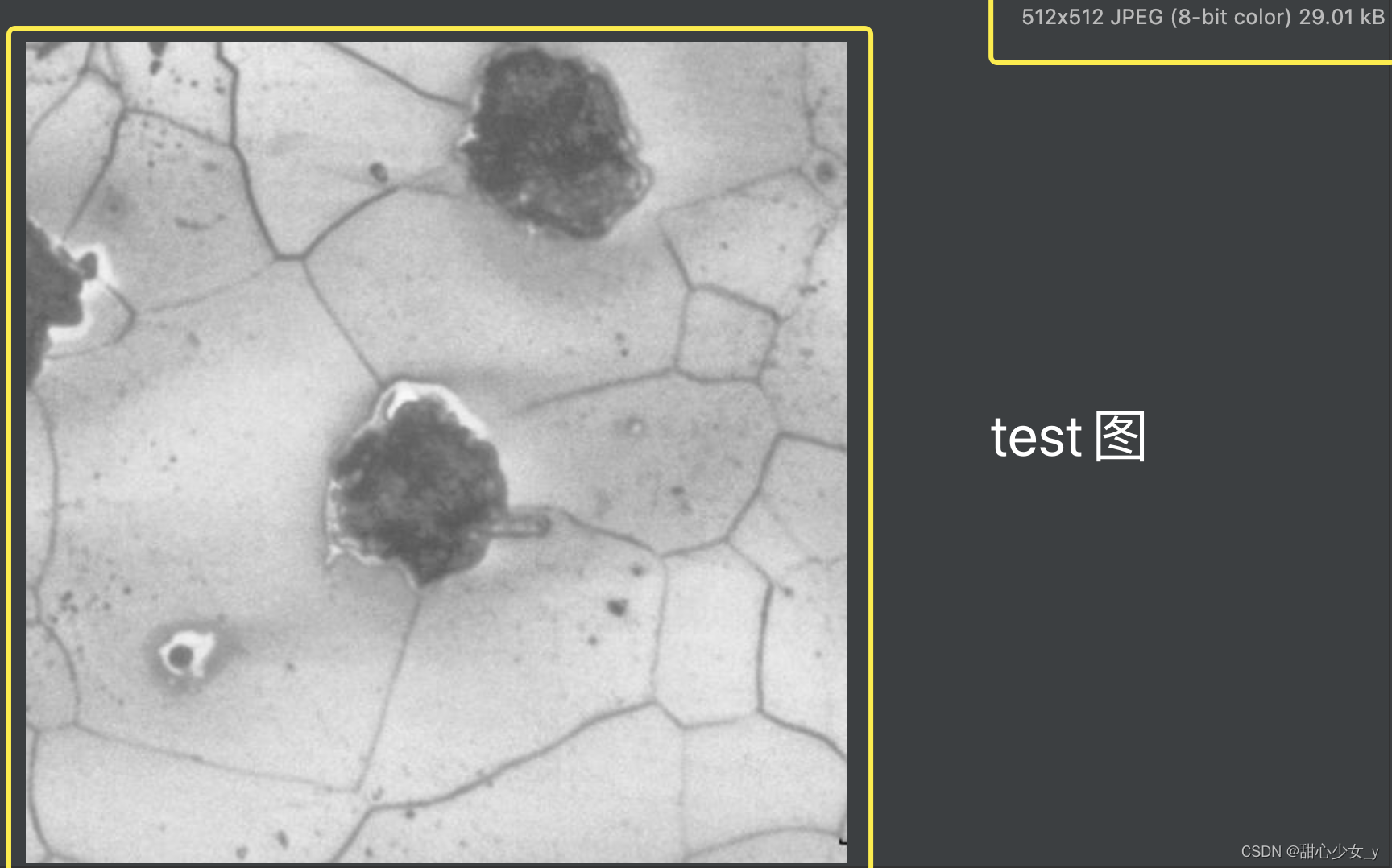
测试分割出的结果图:
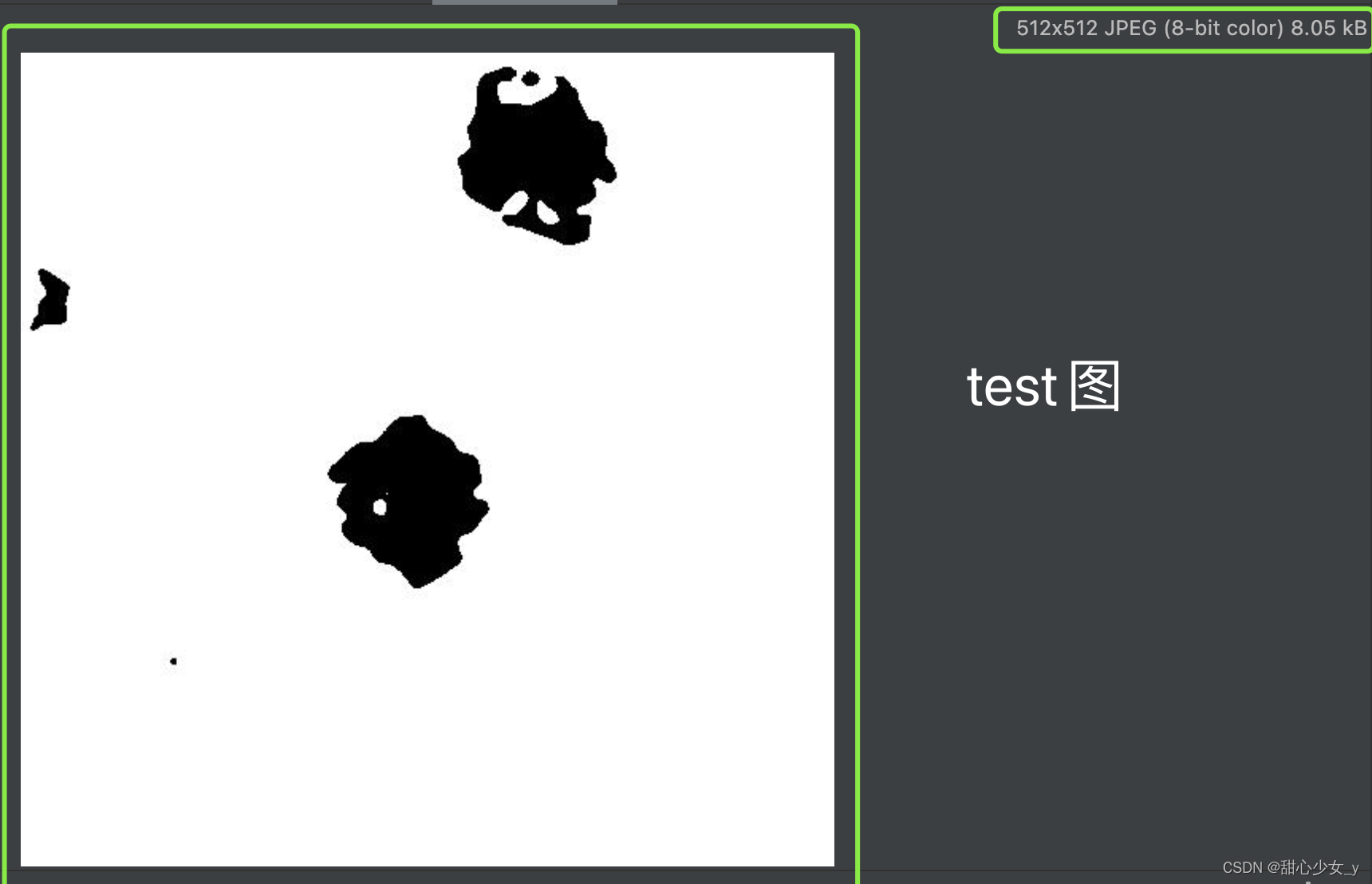
以下是代码:train.py的参数设置
def train_net(net,
device,
epochs=10,
batch_size=1,
lr=1e-4,
val_percent=0.1,
save_cp=True,
img_scale=0.5):
logging.info(f'''Starting training:
Epochs: {epochs}
Batch size: {batch_size}
Learning rate: {lr}
Training size: {n_train}
Validation size: {n_val}
Checkpoints: {save_cp}
Device: {device.type}
Images scaling: {img_scale}
''')
optimizer = optim.RMSprop(net.parameters(), lr=1e-4, weight_decay=1e-8)















 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









