







一、概述
缓存在我们系统内部也广泛使用,基本分本地缓存和分布式缓存。本地缓存由自定义写的缓存组件,分静态缓存与动态缓存,所谓静态就是数据存入就不会被应用清除,动态缓存采用LRU淘汰策略。本地缓存自不多说。但就使用的分布式缓存Redis说明下。
说到缓存的使用场景,1、需要经常访问;2、是很少发生改动;(如果使用缓存并且数据发生频繁改动,同步开销需要注意控制。)
二、场景
多个子系统都需要使用缓存,比如上篇写到的用户权限数据,还有基础数据,比如(机构,品牌、品类,商品等等),还有一些商品价格信息。设计使用上,没有使用Redis持久化,只是单单内存缓存,比如,Key设计,每种API时的时间复杂度的考量,缓存更新策略等,这点大家基本达成共识。那么我们的部署架构应该怎么来做呢?
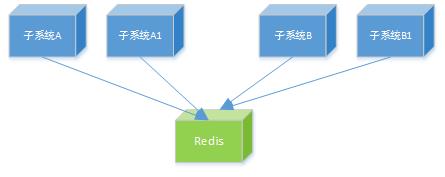
一种声音是A:多个子系统使用同一个缓存集群。(实际上目前我们使用的是单机Redis。单单内存缓存HA确实比较少见。大家都在期待Redis3.0)
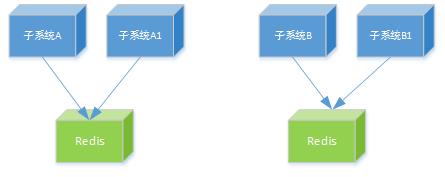
另一种声音是B:最好是每个子系统同一套缓存集群。(前期可以是同一个实例)。
我们还是使用目标场景决策,来选型我们的部署方案。
三、选型
使用过Redis的同学都很清楚,Redis单线程结构,所以,设计缓存接口方案时,都注意控制每个API的请求处理时间。那不相关的系统缓存,放在一起的原因,只有一个解释,就是成本考虑。
A B
成本 低 高
性能 低 高
操作耦合性 高 低
维护复杂性 低 相对高
当然,后续对子系统缓存设计,也需要考量缓存数据量,访问压力,进而采用不同的缓存策略。
综上:前期可以将不同系统缓存使用多Redis实例隔离。















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









