









 本文详细介绍了TF-IDF算法原理及其实现方法,包括使用TfidfTransformer和TfidfVectorizer进行文本特征提取的过程。同时,文章深入探讨了点互信息PMI和互信息MI的概念及其在自然语言处理中的应用,最后给出了如何利用互信息进行特征筛选的具体实例。
本文详细介绍了TF-IDF算法原理及其实现方法,包括使用TfidfTransformer和TfidfVectorizer进行文本特征提取的过程。同时,文章深入探讨了点互信息PMI和互信息MI的概念及其在自然语言处理中的应用,最后给出了如何利用互信息进行特征筛选的具体实例。
目录
sklearn.metrics.mutual_info_score
sklearn.feature_selection.mutual_info_classif
TF-IDF原理
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
TF(词频),即统计文本中各个词的出现频率,并作为文本特征,这个很好理解。
IDF,即“逆文本频率”。为方便理解,举例说明。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer()
text=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
# 文本的词频统计
print(vectorizer.fit_transform(text))
# 各个特征代表的词
print(vectorizer.get_feature_names())
# 每个文本的词向量特征
print(vectorizer.fit_transform(text).toarray())

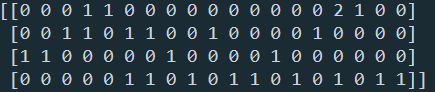
在这个例子中,出现"to"的词频虽然高,但是重要性却应该比词频低的"China"和“Travel”要低。IDF就是来帮助我们来反应这个词的重要性的,进而修正仅仅用词频表示的词特征值。
概括来讲, IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,比如上文中的“to”。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。比如一些专业的名词如“Machine Learning”。这样的词IDF值应该高。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。IDF的定义如下:
IDF(x)=log(N/N(x))
其中,N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数。
为什么IDF的基本公式应该是上面这样,而不是像N/N(x)这样的形式呢?这就涉及到信息论相关的一些知识了。感兴趣的朋友建议阅读吴军博士的《数学之美》第11章。
上面的IDF公式已经可以使用了,但是在一些特殊的情况会有一些小问题,比如某一个生僻词在语料库中没有,这样我们的分母为0, IDF没有意义了。所以常用的IDF我们需要做一些平滑,使语料库中没有出现的词也可以得到一个合适的IDF值。平滑的方法有很多种,最常见的IDF平滑后的公式之一为:
IDF(x)=log((N+1)/(N(x)+1)) + 1
知道了IDF,就可以计算某个词的TF-IDF值了:
TF-IDF(x) = TF(x) * IDF(x)
TF-IDF代码
方法1:使用TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
text=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(text))
print(tfidf)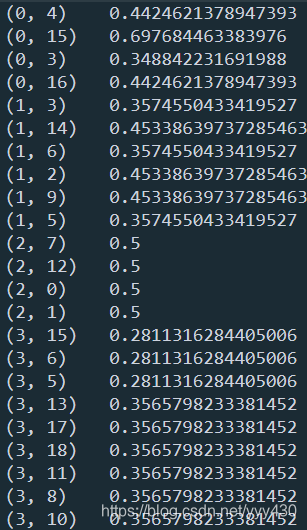
方法2:使用TfidfVectorizer(推荐)
from sklearn.feature_extraction.text import TfidfVectorizer
text=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
tfidf2 = TfidfVectorizer()
re = tfidf2.fit_transform(text)
print(re)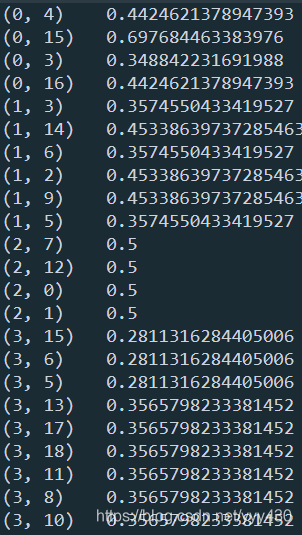
可以看到,2种方法的结果相同,但是TfidfVectorizer更为简洁,因此在实际应用中推荐使用。
互信息的原理
点互信息PMI
点互信息PMI(Pointwise Mutual Information)这个指标常常用来衡量两个事物之间的相关性(比如两个词)。公式如下:
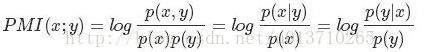
如果x跟y不相关,则p(x,y)=p(x)p(y)。二者相关性越大,则p(x, y)就相比于p(x)p(y)越大。
举个自然语言处理中的例子来说,我们想衡量like这个词的极性(正向情感还是负向情感)。我们可以预先挑选一些正向情感的词,比如good。然后计算like跟good的PMI。
互信息MI
点互信息PMI其实就是从信息论里面的互信息这个概念里面衍生出来的。 互信息即:
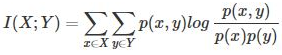
其衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。
可以看出,互信息其实就是对X和Y的所有可能的取值情况的点互信息PMI的加权和。
对特征矩阵使用互信息进行特征筛选
sklearn.metrics.mutual_info_score
from sklearn import datasets
from sklearn import metrics as mr
iris = datasets.load_iris()
x = iris.data
label = iris.target
x0 = x[:, 0]
x1 = x[:, 1]
x2 = x[:, 2]
x3 = x[:, 3]
# 计算各特征与label的互信息
print(mr.mutual_info_score(x0, label))
print(mr.mutual_info_score(x1, label))
print(mr.mutual_info_score(x2, label))
print(mr.mutual_info_score(x3, label))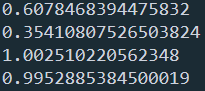
sklearn.feature_selection.mutual_info_classif
from sklearn import datasets
from sklearn.feature_selection import mutual_info_classif
iris = datasets.load_iris()
x = iris.data
label = iris.target
mutual_info = mutual_info_classif(x, label, discrete_features= False)
print(mutual_info)![]()
参考
文本挖掘预处理之TF-IDF https://www.cnblogs.com/pinard/p/6693230.html
《从零开始学习自然语言处理(NLP)》-TF-IDF算法(2) https://mp.weixin.qq.com/s?__biz=MzUyMjE2MTE0Mw==&mid=2247487478&idx=1&sn=44eec0f46d511dd181afe5eca26b456d&chksm=f9d1516ecea6d8785fb02f1082773711b9ead3c235315eded29dade64791e3df9d394091124d&scene=0&xtrack=1#rd
文本挖掘预处理之向量化与Hash Trick http://www.cnblogs.com/pinard/p/6688348.html
使用gensim、sklearn、python计算TF-IDF值 https://www.jianshu.com/p/f3b92124cd2b
sklearn:点互信息和互信息 https://blog.csdn.net/u013710265/article/details/72848755
NLP实践-Task3 https://blog.csdn.net/zh11403070219/article/details/88284390
sklearn.metrics.mutual_info_score https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mutual_info_score.html#sklearn.metrics.mutual_info_score
sklearn.feature_selection.mutual_info_classif https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.mutual_info_classif.html#sklearn.feature_selection.mutual_info_classif


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









