






本文是基于Stanford CS231n的学习笔记,搭建一个简单的Softmax分类器。1
生成数据集
首先是生成一个不易线性分割的数据集,本文采用的例子是螺旋数据集(Spiral Dataset)
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# lets visualize the data:
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.show()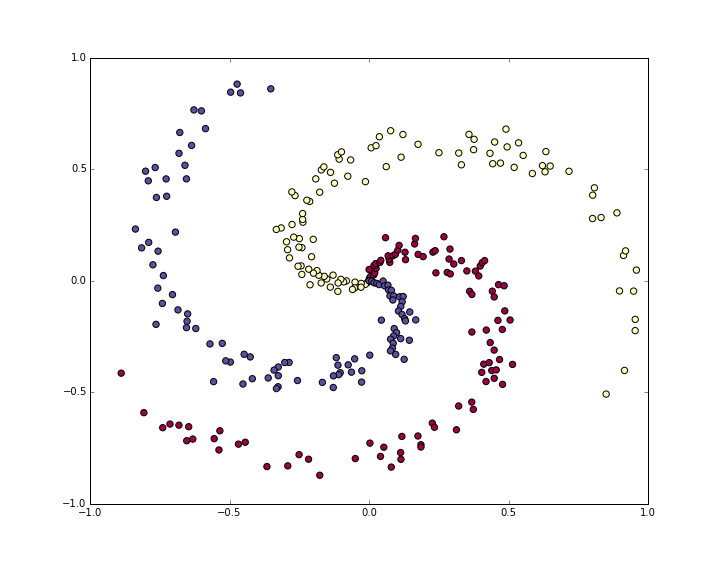
通常情况我们需要预处理每个特征,进行Z-score标准化:
Z-score标准化有两个好处
1.是消除量纲对最终结果的影响,使不同变量具有可比性。比如两个人体重差10KG,身高差0.02M,在衡量两个人的差别时体重的差距会把身高的差距完全掩盖,标准化之后就不会有这样的问题。
2.均值为0,标准差为1
其中 σ 是标准差, μ 是样本均值
具体可参考 2
但是这个数据集的特征已经很好的分布于[-1,1],所以我们跳过这个步骤
训练一个Softmax线性分类器
初始化参数
Softmax分类器是由一个线性的 Score Function 并使用 Cross-entropy Loss Function,这个线性分类器的参数由一个权重矩阵
W
和一个偏移向量
# initialize parameters randomly
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))这里的D=2指的是数据集的维度,K=3指的是数据集包含的类别。
计算得分
# compute class scores for a linear classifier
scores = np.dot(X, W) + b在这个例子中我们有300个二维的点,所以计算得出的矩阵 scores 的大小为[300*3],表示的是300个点分别在3个类别的得分(蓝,红,黄)。
计算损失
分类器的第二个重要构成部分是损失函数,损失函数是一个可微的用来量化我们对于计算出的得分是否满意的函数。 我们希望每个点对应的正确的类别相比于其他类别取得一个更高的得分。在这个例子中我们会使用 Cross-entropy 损失函数, f 表示的是每个点在3个类别的得分:
Softmax分类器解释
f
中的每个元素为该点对应三个类别的对数概率(未标准化)。 我们对其取幂得到概率(未标准化),然后再进行标准化得到概率。因此,log里面的表达式是正确类别的标准化后的概率
(
NOTE:这个公式的数值永远介于0到1之间,当正确类别的概率接近0时,损失值会接近正无穷。相反地,如果正确类别的概率接近于1,损失值会接近于0。所以,当
Li
很小时,正确类别的概率是很高的,当它很大时,正确类别的概率是很小的。
整个分类器的损失值是所有训练例子的损失值的平均值加上正则损失值。(正则损失值是为了防止过拟合)
以下是代码
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)所以我们现在有了一个[300*3]的数组 probs ,描述了300个点分别对应3个类别的概率,现在我们可以求300个点分别对应的正确类别的概率的log值。
corect_logprobs = -np.log(probs[range(num_examples),y])corectlogprobs 是一个[300*1]矩阵,描述了300个点分别对应的正确类别的概率的log值。整个分类器的损失值将由这些log值加上正则损失值构成:
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss这个代码中,正则强度值 λ 储存在reg中。用初始的随机参数值计算loss会得到,loss=1.1,也就是log(1.0/3)=1.1,因为用初始参数值计算出的每个类别的概率大概都是1/3。而我们接下来需要做的是尽可能降低loss值。
反向传播法(Backpropagation)计算梯度值
我们已经有了方法测量损失值(loss),现在我们要降低它。我们会采取梯度下降法。 首先我们引进一个中间变量
p
,一个代表概率的向量:
则训练样本i的loss是
现在我们想要得到是
fk
的值应该怎样变化才能降低loss
Li
,即我们想求得
∂Li/∂fk
,利用复合函数求导可求得:
这是一个很漂亮的结果,假设我们求得一个训练样本的概率值是 p = [0.2, 0.3, 0.5], 然后这个训练样本的正确类是第二类,则 df = [0.2, -0.7, 0.5]. 表示只有提升f中的第二个值才能降低loss. 以下为代码:
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples最后,因为我们有 scores = np.dot(X, W) + b ,所以我们得知了dscores就可反向传播求得 db 和 dW 。
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # don't forget the regularization gradient参数更新
# perform a parameter update
W += -step_size * dW
b += -step_size * db完整代码
import numpy as np
import matplotlib.pyplot as plt
# initialize parameters randomly
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
D=2
K=3
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in xrange(200):
# evaluate class scores, [N x K]
scores = np.dot(X, W) + b
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 10 == 0:
print "iteration %d: loss %f" % (i, loss)
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters (W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# perform a parameter update
W += -step_size * dW
b += -step_size * db
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print W
print 'training accuracy: %.2f' % (np.mean(predicted_class == y))
plt.show()以下是Desicion Boundary的图,但是我不知道怎么画Desicion Bounday,有知道的朋友欢迎指导

关于本文涉及的更详细的SoftMax原理可参阅这里















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









