







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
个人学习笔记,仅供参考!欢迎指正!
一、常识
内存
1、寻址:ns(纳秒) 2、带宽:很大 秒 > 毫秒 > 微妙 > 纳秒 在寻址上,磁盘比内存慢了10W倍
磁盘
1、寻址:ms 2、带宽:G或者M,单位时间内可以有多少个数据流过去
文件读取问题
如果文件存储在磁盘上,随着文件越大,读取文件的速度会变慢,这是由于IO的瓶颈导致的
I/O Buffer成本问题
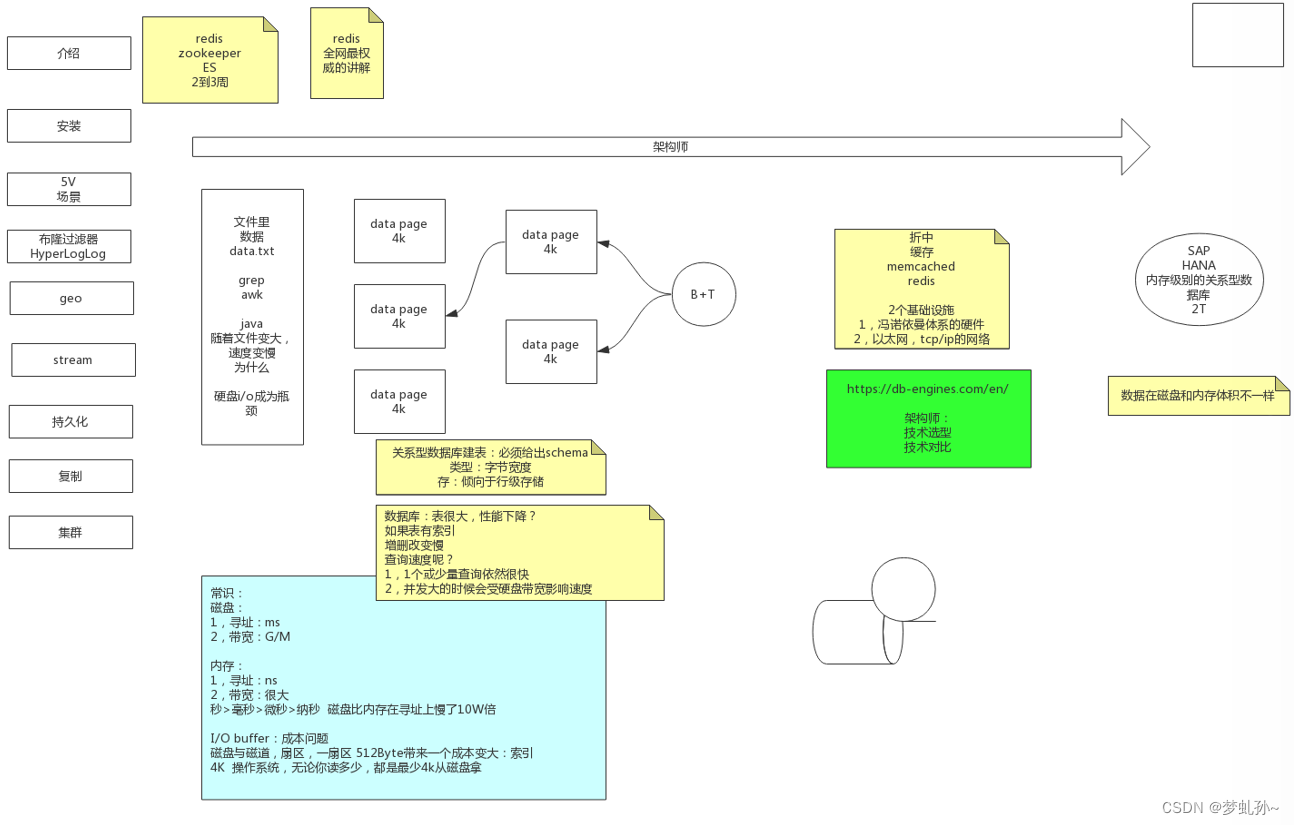
磁盘与磁道,扇区,一扇区 512Byte,容器区域足够小,会导致一个成本变大:索引;但是真正使用硬盘的时候,有一个4K对齐操作,读一扇区512Byte时,操作系统无论你读多少都是最少4K从磁盘拿,系统每一次的读写量都是4K
二、关系型数据库常识
IO基础知识
data page:默认4K,刚好和磁盘上每次的默认读取量4K相同。根据第一天的经验,data page设置时,如果小于4K时,会导致浪费,比如data page设置为1K,实际上对磁盘做数据操作时,磁盘还是给返回4K的数据回来;不过如果data page的设置大于4K,则磁盘每次的读写量大小就是data page设置的大小
磁盘读写量与data page的关系:磁盘每次的读写量 = data page < 4K ? 4K : data page
数据库基础知识
- 如果数据库仅仅只是建表,但是没有建索引,每次从数据库中读取信息时,实际上IO也是按照顺序去遍历每一个data page所对应的磁盘数据,找到了就给你返回,数据量越大,IO速度也就会越慢。
- 如果为表中的某个列建索引,那么索引其实底层上也是保存在data page上的,只是这个data page上除了保存索引列的信息之外,还保存了当前索引所在行的data page磁盘地址,方便我们后续的查询能更快的定位。
- 关系型数据库建表的时候,必须给出 schema ( schema :一共多少个列,每个列的类型是啥),定死了每列的数据类型的字节宽度,假设此时数据表中有5个字段,每个字段占一个字节,然后我们新增一条数据,只有2个字段是有值的,当我们向 data page 中存数据的时候,其他3个没有值的字段会用 0 作为填充,把当前列字节的宽度给全部占满,这是由于关系型数据库偏向于 行级储存 ,当我们以后对行数据做编辑操作的时候,不需要移动数据,直接对行数据做覆盖操作就可以了。数据表和索引因为都是文件,都会放在磁盘上,而我们常说的 B+ 树其实是一种算法,用来更快的找到数据的所在区间,减少磁盘寻址的次数,提升查询效率, B+ 树里是不存储数据的,因此它可以放在内存中,而它的叶子结点保存的是索引所在的data page地址。
表很大的时候,性能下降?这句话对吗
- 如果表有索引,增删改会变慢,因为需要维护索引
- 查询速度呢?(假数据量巨大,1TB)
1个或少量查询依然会很快,并发大的时候会受到硬盘带宽影响速度。
硬盘的速度除了受寻址影响之外,还会受到硬盘带宽的影响
数据库的两个极端
数据库有两个极端:一个是把数据存储在磁盘上的数据库(MYSQL),还有一个是把数据存在内存上的数据库(SAP HANA)。
数据存在内存和存在磁盘上时,所占用的空间是不一样的,因为磁盘中的文件不存在引用这个概
念,而内存可以利用引用来减少索引带来的额外的空间使用,因此基于内存的数据库往往要比基于
磁盘的数据库存储相同数据时,所使用的空间更少,但是内存数据库的价格也是极其高昂的,一般
的企业无法承担
所以才有了一个折中的处理方案,也就是利用缓存保存部分热点数据,提高访问的效率
K-V数据库
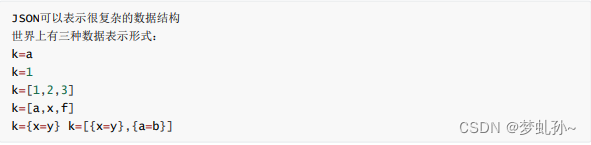
K-V数据库其实就是JSON,一般JSON所表示的数据形式有:
三、介绍
架构师要做技术选型,不能破坏技术的特征,比如 Redis 的一致性是最终一致性,如果在其他维度需要强一致性,那么就不是适合使用 Redis 了
Redis 的速度:1.5M 每秒,每秒15W笔操作,换算成K是150000K,当然这是理想状态,所以现实中还是会有些出入,但是 redis 就是一个毫秒级响应的中间件
简介
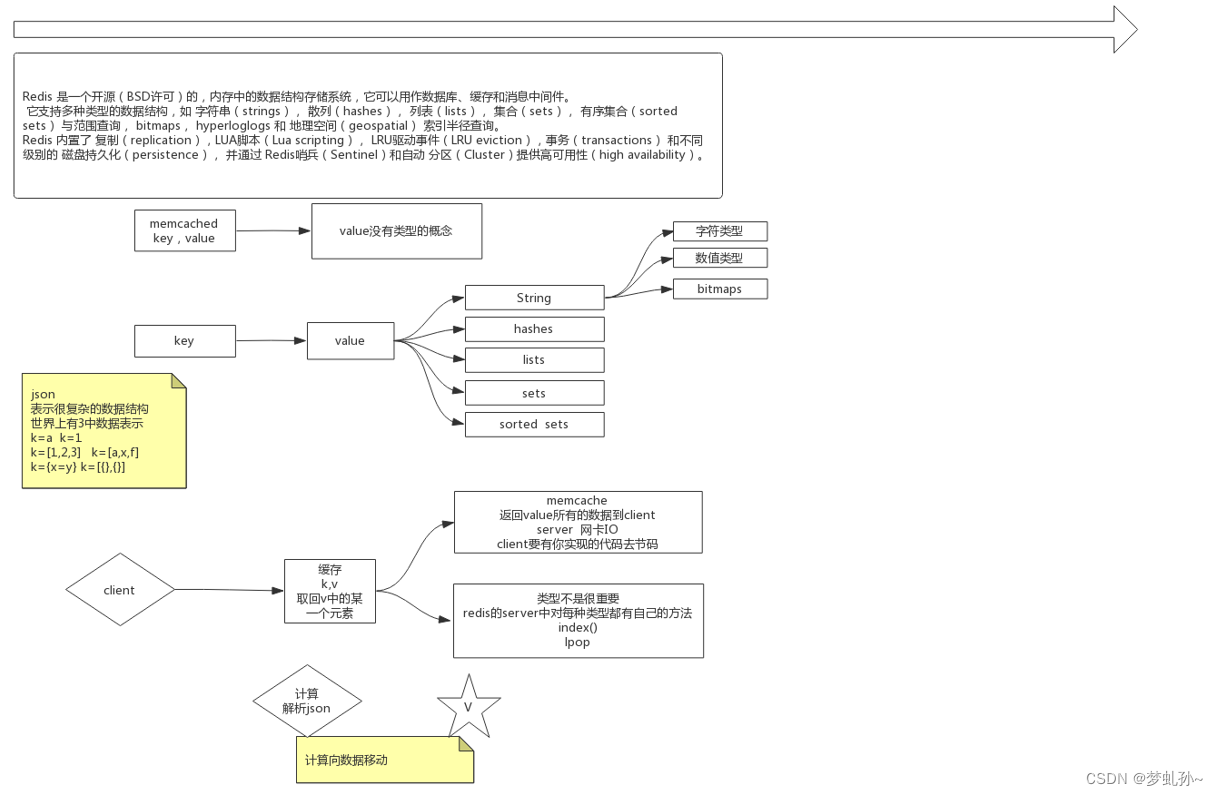
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合
(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)在 Redis 中,一般说的数据结构是针对 value 的,只有 value 才有类型的区分
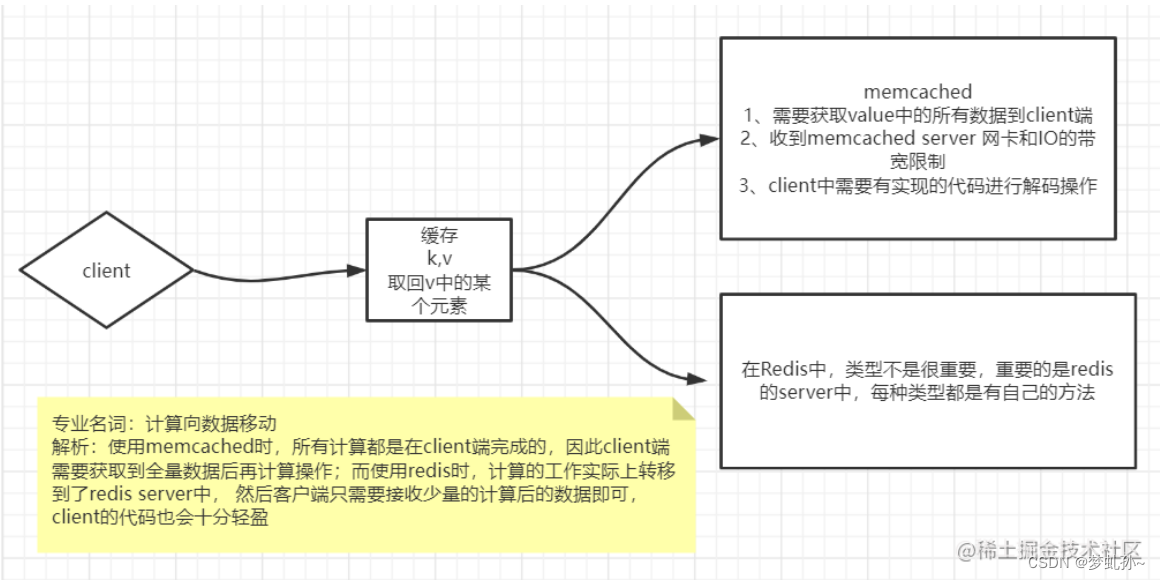
在 Redis 之前,还有一个也是基于 K-V 的缓存数据库 memcached ,但是与 Redis 不同的是,
memcached 中的 value 没有类型这个概念。当发现两者的不同时,思考一下当没有 Redis 时,只有
memcached 时,如果表示一个复杂的数据结构?没错,就是 JSON ,世界上只有三种数据表示方式:
根据上面的描述,其实 memcached 也完全是OK的,那么为什么需要去学习 Redis ?
为什么选择Redis?
场景:此时我们需要从缓存中通过 key 获取 value 中的某个元素,他们都是怎么做的?















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









