









问题引入
偏差与方差的权衡是统计学中最核心的问题,在机器学习中,它们是导致欠拟合和过拟合的原因。
对于线性回归问题,我们到底是该选择简单的线性模型
y=θ0+θ1x
还是选择诸如
y=θ0+θ1x+...+θ5x5
这样复杂些的模型呢?我么先看下图
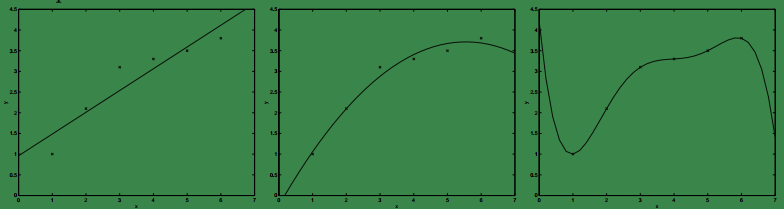
上图我们之前就见到过,最左面的为欠拟合,因为它会有较大的偏差;最右面的为过拟合,它很有可能会过于关注少量样本中的一些比较极端的属性值(噪声),因此测试新样本时将会产生很大的方差。
也就是说,我们不仅要在训练时使得偏差尽可能小,也要保证方差尽可能小,即泛化误差(generalization error)要小。
一般而言,如果模型过于简单,且参数很少时,容易产生大的偏差,但方差会较小;如果模型很复杂,并且参数很多时,容易产生较大的方差,但偏差会较小。
问题描述
下面先给出两个事实(fact):
1、(The union bound)假设
A1,A2,...,AK
是
k
个不同的事件(他们并不一定相互独立),有:
2、(Hoeffding inequality) 假设
Z1,...,Zm
是m个满足伯努利分布的独立同分布( independent and identically distributed (iid) )随机变量。令
ϕ^=1m∑mi=1Zi
,
γ>0
则有:
P(|ϕ−ϕ^|>γ)≤2exp(−2γ2m)
注:所谓独立同分布(iid)是指,每个样本相互独立且满足相同的分布模型(比如都满足伯努利分布,或者都满足高斯分布等)。
由2可知,当样本数m越大时,估计值
ϕ^
越接近实际值
ϕ
.
为了简化问题,我们只考虑2分类情况,对其他问题模型一样适用。
假设训练样本为
S={(x(i),y(i));i=1,...,m}
,其中每个样本
(x(i),y(i))∼D
,即每个样本都满足独立同分布。对于假设模型
h
,我们定义训练误差(也称为经验风险或经验误差)为:
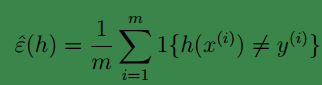
它其实反映了训练时的误分率,因为我们是使用的训练样本集
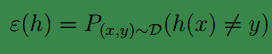
如果此时我们是使用的线性回归来分类,那么参数
θ
应该怎样求呢?我们可以求能够使得误分率最小的
θ
,因此可得:
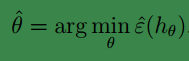
我们称之为经验风险最小化( empirical risk minimization (ERM))
事实上,对于一个分类问题,我们有时很难直接确定模型的复杂度,因此我们定义一个模型池
H
(hypothesis class),它包含了很多个假设模型,
H={hθ:hθ(x)=I{θTx≥0},θ∈Rn+1}
,我们在
R
中按如下规则选择模型:
其实就是将经验风险最小化算法应用在模型选择上。
注:在这一篇中用 h^ 之类的表示,代表这是一个估计值或统计值,而对应的 h <script type="math/tex" id="MathJax-Element-24">h</script>,表示实际值,否则符号会有点乱。















 7125
7125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









