







自然语言处理 笔记
1.什么是自然语言处理?
NLP = NLU + NLG
NLU(Natural Language Understangding) 从语音/文本信息中 ------》 理解意思(meaning)
NLG(Natural Language Generation) 意思 ------》生成文本/语音
2.为什么NLP更难?
相比于 CV(Computer Vision),CV是所见即所得,是直观上感知;而NLP更为复杂,牵扯到上下文理解,词的多义性等等
3.NLP的Challenge
- One Meaning —> Multiple Ways to Express(一种意思 多种表达方式)

- Ambiguity(一词多义)

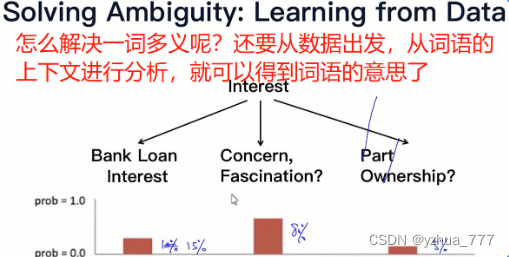
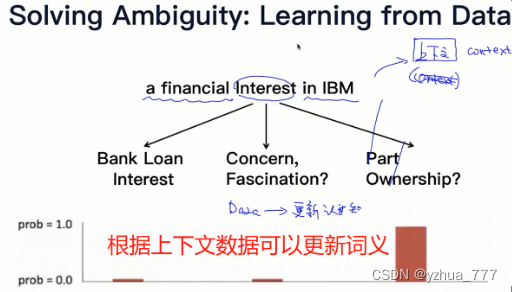
4.怎么解决一词多义呢?
从词语的上下文进行分析,从数据出发

5. case study: 机器翻译
根据以往的翻译,翻译出指定的句子?

- 解决方法:1.将原始数据翻译制作语料库,每个单词对应的翻译做成一一映射 2.查询将要翻译的单词,找到对应的翻译,连到一起
- 解决方法的缺点:1.慢 2.没有考虑上下文 3.语义方面翻译不对 4.语法不对
那么该怎么做呢?

上面机器翻译的过程是怎样的呢?
- 首先将 今晚的课程有意思 进行分词处理, 得到 今晚 | 的 | 课程 | 有意思
- 逐词翻译 Tonight, of, the course, interesting
- 由于逐次翻译没有语法概念,翻译后的词排列组合
- Tonight, of, the course, interesting
of, tonight, the course, interesting
the course,…
…
总共是4!=24种排列组合 - 这些组合将会通过一个语言选择模型进行选择,语言选择模型会对每个组合进行概率估计,最终选择概率最大的句子
当逐词翻译出的句子排列组合较多时,语言选择模型的时间复杂度将会是指数级别的,是及不可取的。于是便产生了Viterb algorithm

- 维特比同时考虑Translation Model和Language Model

















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









