









词嵌入模型
词嵌入模型基于的基本假设是出现在相似的上下文中的词含义相似,以此为依据将词从高维稀疏的独热向量映射为低维稠密的连续向量,从而实现对词的语义建模。
基于词出现频次的词嵌入模型
通过对“文档-词”矩阵进行矩阵分解得到每个词的语义表示。典型模型有GloVe。GloVe模型的基本思想是最小化 词 i i i和词 j j j的向量向量表示 v i v_i vi和 v j ^ \hat{v_j} vj^算得的函数 F ( v i T v j ^ ) F(v_i^T\hat{v_j}) F(viTvj^) 与 词 j j j出现在词 i i i的上下文概率 P i j P_{ij} Pij 之间的误差。
基于词预测的词嵌入模型
基于词预测的词嵌入模型的典型模型是Word2Vec,又包括CBOW(Continuous Bag-of-Words)模型和Skip-Gram模型两种。

- CBOW模型的目标是最大化通过上下文的词预测当前词的生成概率。
- Skip-Gram模型则是最大化用当前词预测上下文的词生成概率。
CBOW:多个one-hot输入向量通过一个
V
×
N
V \times N
V×N维的权重矩阵
W
W
W连接到隐藏层,相加后得到上下文向量;隐藏层通过一个
N
×
V
N\times V
N×V的权重矩阵
W
′
W^{'}
W′连接到输出层,得到预测向量,与目标one-hot向量计算损失。最终模型的词向量就是利用训练好的权重矩阵
W
W
W,输入对应单词的one-hot向量,输出
N
N
N维词向量。
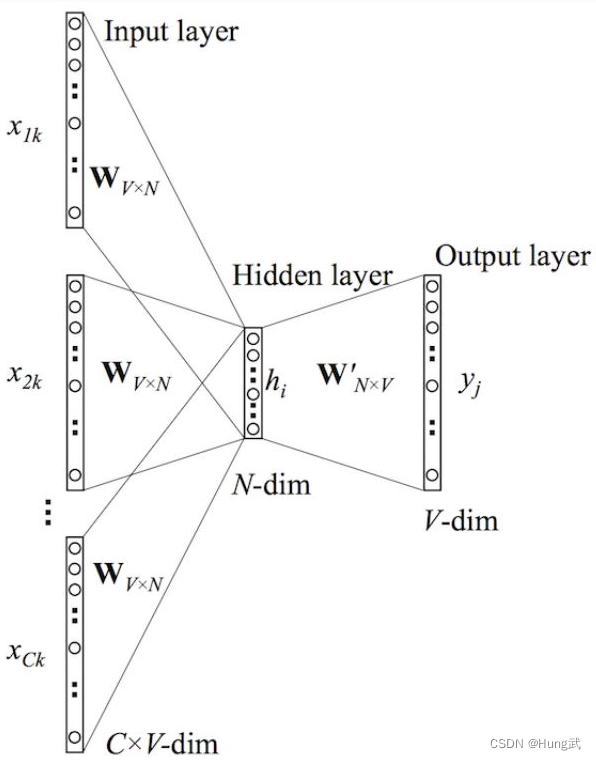
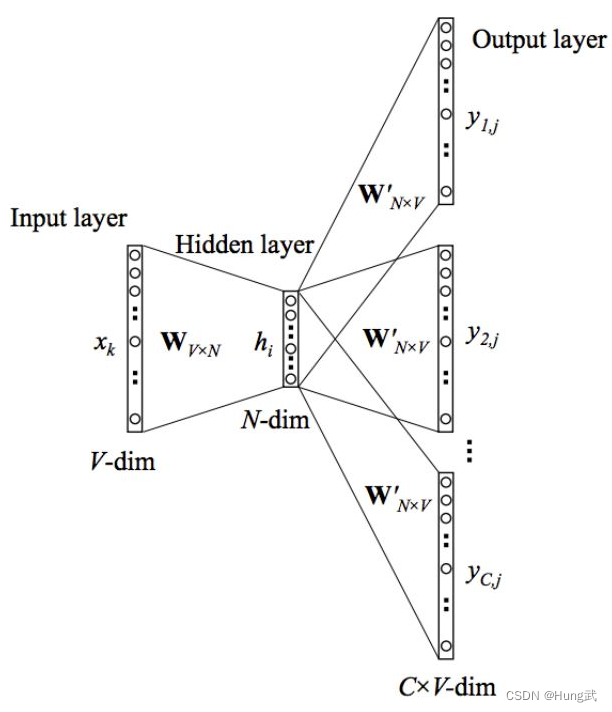
Skip-Gram模型学习的目标是输入层与隐藏层之间的权重矩阵
W
W
W。预测结果由多个权重矩阵
W
′
W^{'}
W′映射得到。
区别
目前流行的模型中,基于词预测的词嵌入模型占据主导地位。一方面,直接预测不需要对语料进行复杂的处理,可以适应更大的计算量;另一方面,预测上下文词的任务形式也很容易扩展为其他自然语言处理任务。
作用
词嵌入模型常被用于预训练任务,即利用在大规模语料库中训练获得的词嵌入表示,来初始化各种自然语言处理任务中神经网络模型的输入层参数。
语言模型
语言模型是自然语言处理中的核心任务,一方面它可以评估语言的生成概率,直接用于生成符合人类认知的语言;另一方面,由于语言模型的训练不依赖额外的监督信息,因此适合用于学习语句的通用语义表示。
ELMo

ELMo基于双向LSTM来学习一个双向语言模型。具体任务中,通过特征融合的方式将特征表示集合中不同的表示加权求和,作为特征输入到任务模型中,权重跟随任务模型的参数一起学习。
GPT

GPT基于Transformer单向编码器结构,将单向语言模型作为预训练阶段的目标函数。预训练学习到的网络结构和参数将作为具体任务模型的初始值,然后针对文本分类、序列标注、句子关系判断等不同任务对网络结构进行改造,同时将语言模型作为辅助任务对模型参数进行微调。
BERT

BERT相对于之前工作的改进点主要有两个方面:
- 实现真正的双向多层语言模型,对词级别语义进行深度建模。BERT在预训练阶段引入掩码语言模型任务,每轮训练选择语料中15%的词,随机替换成< MASK >标志或其他随机词或保持原样,并对这些词进行预测。
- BERT模型对输入层的嵌入表示做了两点改进,(1)引入了句子向量同时作为输入,(2)引入了< SEP >标志表示句子的结尾和< CLS >标志表示句子关系,并分别学习对应向量。在面对具体任务时,BERT同样保留预训练得到的模型结构,然后通过参数微调来优化具体任务对应的目标。和GPT相比,BERT在利用预训练的语言模型做下游自然语言处理任务时,对模型的改动更小,泛化性能更强。
机器翻译
机器翻译模型
Seq2Seq架构的神经机器翻译模型在效果上还未超过统计机器翻译模型,主要原因在于模型将源语言端的信息全部编码到LSTM最后一次隐单元,对信息进行了有损压缩,同时LSTM对长距离语境依赖问题解决程度有限,解码时容易丢失重要信息而导致翻译结果较差。
基于注意力机制的神经机器翻译模型,与统计机器翻译中词对齐思想类似,认为模型在解码每个词的时候,主要受源语言中当前解码词相关的若干词影响,因此可以利用注意力机制学习一个上下文向量,作为每步解码的输入。注意力机制一方面生成上下文向量,为解码提供额外的信息;另一方面它允许任意编码节点到解码节点的直接连接,很好地解决了长距离语境依赖问题。
Transformer是基于注意力机制的网络结构,核心创新点在于提出多头自注意力机制。一方面通过自注意力将句中相隔任意长度的词距离缩减为常量,另一方面通过多头结构捕捉到不同子空间的语义信息,因此可以更好地完成对长难句的编码和解码。由于Transformer完全基于前馈神经网络,缺少了像卷积神经网络和循环神经网络中对位置信息的捕捉能力,因此它显式地对词的不同位置信息进行了编码,与词嵌入一起作为模型的输入。相比于循环神经网络,Transformer大大提升了模型的并行能力,在训练和预测时效率都远高于基于循环神经网络的机器翻译模型。
解决双语语料不足的方法
双语语料是机器翻译模型训练时最重要的监督信息,然而在现实应用中由于某些语言是小语种或者特定领域的语料稀缺等,经常出现双语语料不足的情况。
- 通过爬虫自动挖掘和产生更多的双语语料。
- 构造伪双语平行语料。(1)利用目标语言端的单语语料反向翻译源语言,由于这样构造的平行语料中的目标语言端为真实语料,有利于解码器网络的学习,提升模型效果;(2)利用数据增强的方式对原始语料进行改造,用在双语语料中出现频率较低的词替换原语料中某一位置的词,并利用语言模型对替换后语句打分,将排名靠前的保留,接着利用词对齐模型将目标语言端与被替换词对齐的词也替换成对应词的释义,选择语言模型打分最高的释义进行保留。
- 在模型层面来解决语料不足的问题。将不同语言对的双语语料放在一起训练,共用统一的词表。唯一与单语言对翻译模型不同的是,在源语言端的输入起始位置加上< 2es >或 < 2cn >这种表示翻译目标语言的标记。
问答系统
问答系统是指可以根据用户的问题从一个知识库或非结构化的自然语言文档集合中查询并返回答案的计算机软件系统。
问题系统的任务
- 问题分类。问题分类主要用于决定答案的类型,不同的答案类型也往往意味着在系统实现上对应着不同的处理逻辑。根据期望回答方式可以将问题分类成 事实型问题、列举型问题、带有假设条件的问题、询问“某某事情如何做”以及“某某东西是什么”等问题。
- 段落检索。段落检索是指根据用户的问题,在知识库以及备选段落集合中返回一个较小候选集。应用一些相对轻量级的算法筛选出一部分候选集,使得后续的答案抽取阶段可以应用一些更为复杂的算法。
- 答案抽取。答案抽取是指根据用户的问题,在段落候选集的文本中抽取最终答案的过程。
注意力机制
对于同一个文本段落,不同问题的答案往往来自于段落中不同的位置。在给文本段落编码时结合问题信息,可以获得更有效的编码表示。利用注意力机制算得问题中每个词相对于段落的注意力编码 和 段落中每个词相对于问题的注意力编码。结合问题信息对段落进行注意力编码可以降低段落长度对预测结果的影响。
位置编码
由于在 Transformer 中没有显式地保留位置信息,研究者采用不同频率的正弦/余弦函数对位置信息进行编码。位置编码向量的维度一般与文本编码向量的维度相同,这样二者可以直接相加作为单词最终的编码向量。位置编码的另一个优点是,即使测试集中出现了超过训练集文本长度的样本,这种编码方式仍然可以获得有效的相对位置表示。此外,使用这种位置编码时,在模型中加入位置信息只需要简单的相加操作即可,不会给模型增加过大的负担。
对话系统
对话系统是指可以通过文本、语音、图像等自然的沟通方式自动地与人类交流的计算机系统。对话系统根据信息领域的不同(开放与闭合)以及设计目标的不同(任务型与非任务型)可以划分为不同的类型:
- 任务型:需要根据用户的需求完成相应的任务
- 非任务型:根据人类的日常聊天行为而设计
结构
- 对话理解:对于用户的输入,通过语义理解单元进行编码,通过对话状态跟踪模块生成的当前对话状态编码;
- 策略学习:根据当前对话状态,系统选择需要执行的任务;
- 对话生成:通过自然语言生成返回用户可以理解的表达形式。
强化学习的应用
对于对话系统来说,用户的输入往往多种多样,对于不同领域的对话内容,对话系统可以采取的行为也多种多样。普通的有监督学习方法往往无法获得充足的训练样本进行学习,而强化学习可在一定程度解决这个问题。而且,当对话系统与用户的交互行为持续地从客户端传输到服务端时,强化学习方法可以对模型进行及时的更新,在线训练模型。
对话系统中的策略学习模块比较适合使用强化学习来建模。我们的目标是学习一个策略 π \pi π,根据系统当前对话状态向量 b b b来选择一个最优行为 a a a,使得对话系统尽可能完成用户在对话中指定的任务。每段对话结束时,可以根据任务是否成功完成来设定策略的奖励。另外在每一轮对话结束后,都反馈一个绝对值较小的 − ϵ -\epsilon −ϵ,以促使算法尽可能学习简洁的策略。















 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









