






引言
如果两个内存访问会触碰一段相同的内存,且其中至少有一个是写操作,则认为它们之间存在依赖(即不是独立的)。
本文假定数组总是 row-major 的,考察如下形式的循环:
for (i1 = d1; i1 <= u1; i1 += s1) {
for (i2 = d2; i2 <= u2; i2 += s2) {
// 第 n 层循环
for (in = dn; in <= un; in += sn) {
// 循环体
}
}
}
数组访问依赖分析要解决的核心问题:
(1)数组访问间是否独立
(2)能否通过等效变换,将有依赖关系的数组访问安排在一起
编译器作各种变换都需要保持内存访问间的依赖。数组访问依赖分析可用于判断 Loop Interchange、Loop Vectorization 等许多变换的合法性;通过将有依赖关系的数组访问安排在一起,可以提升程序的时间/空间局部性,相互独立的部分也能并行。
下面看一个例子:
for (i = 1; i < 100; i += 1)
for (j = 0; j < i; j += 1)
a[j, i+1] = a[j, i] + 1![]()
作如下 Loop Interchange 变换以提升程序的空间局部性:
for (j = 0; j < 99; j += 1)
for (i = j + 1; i < 100; i += 1)
a[j, i+1] = a[j, i] + 1
数组访问的数学表述

for (i = d; i <= U; i += S)for (j = 1; j <= (U - L + S) / S; j += 1)
i = j * S - S + L不失一般性,令迭代变量均为归一化的。

看一个例子:
for (i = 1; i <= 100; i += 1)
for (j = 1; j <= 3 * i; j += 1)
a[i, i + j * 2 + 1] += 1静态数组访问 a[i, i + j * 2 + 1] 对应:
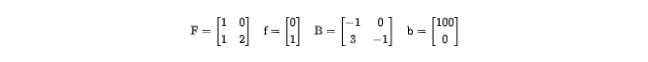
判断数组访问间是否独立

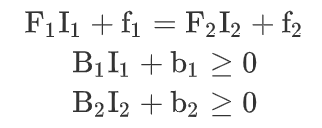
上述方程的求解是典型的整数规划问题,可参阅相关资料,不再赘述。此类问题是 NP 完全问题,无法精确求解。实践中通常根据一系列启发式的依赖关系测试作出判断。
仿射划分
为了将有依赖关系的动态数组访问安排在一起,我们需要找到一个划分:若两个动态数组访问之间存在依赖,则它们应当属于同一个集合。



每一个仿射划分都可以分解为以下几种基本转换之叠加,每种基本转换对应一类对源码的简单修改。
1. Fusion
转换前:
for (i = 1; i <= N; i++)
Y[i] = Z[i]
for (i = 1; i <= N; i++)
X[i] = Y[i]划分:
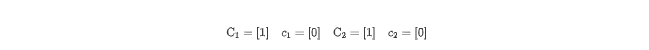
转换后:
for (j = 1; j <= N; j++)
Y[j] = Z[j]
X[j] = Y[j]2. Fission
转换前:
for (i = 1; i <= N; i++)
Y[i] = Z[i]
X[i] = Y[i]划分:
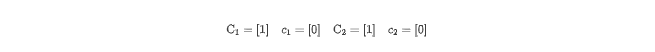
转换后:
for (j = 1; j <= N; j++)
Y[j] = Z[j]
for (j = 1; j <= N; j++)
X[j] = Y[j]3. Re-indexing
转换前:
for (i = 1; i <= N; i++)
Y[i] = Z[i]
X[i] = Y[i-1]划分:
![]()
转换后:
if (N >= 1)
X[1] = Y[0];
for (j = 1; j <= N - 1; j++)
Y[j] = Z[j]
X[j+1] = Y[j]
if (N >= 1)
Y[N] = Z[N]4. Scaling
转换前:
for (i = 1; i <= N; i++)
Y[2*i] = Z[2*i];
for (i = 1; i <= 2*N; i++)
X[i] = Y[i];划分:
![]()
转换后:
for (j = 1; j <= 2*N; i++)
if (j % 2 == 0)
Y[j] = Z[j]
X[j] = Y[j];5. Reversal
转换前:
for (i = 1; i <= N; i++)
Y[N-i] = Z[i];
for (i = 1; i <= N; i++)
X[i] = Y[i];划分:
![]()
转换后:
for (j = 1; j <= N; j++)
Y[j] = Z[N-j];
X[j] = Y[j];6. Permutation
转换前:
for (i1 = 1; i1 <= N; i1++)
for (i2 = 0; i2 <= M; i2++)
Z[i1, i2] = Z[i1-1, i2]划分:
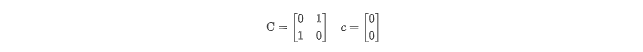
转换后:
for (j1 = 0; j1 <= M; j1++)
for (j2 = 1; j2 <= N; j2++)
Z[j2, j1] = Z[j2-1, j1]7. Skewing
转换前:
for (i1 = 0; i1 <= N+M-1; i1++)
for (i2 = max(1, i1+N); i2 <= min(i1, M); i2++)
Z[i1, i2] = Z[i1-1, i2-1]划分:
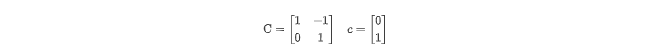
转换后:
for (j1 = 1; j1 <= N; j1++)
for (j2 = 1; j2 <= M; j2++)
Z[j1, j2-j1] = Z[j1-1, j2-j1-1]在 LLVM 中的应用
DependenceAnalysis pass 实现了基本的数组访问依赖分析,可用于依赖关系判断,也能进行简单的仿射划分。LoopFuse、LoopInterchange、LoopTiling 等 transformation pass 均需要 DependenceAnalysis 提供的信息才能工作。
在 MLIR 'affine' dialect 中,数组访问依赖分析的实现更加完备(因为在 MLIR 中数组访问的相关信息被完全保留了,而非像在 IR 中那样需要从 getelementptr 等指令反向推导出来),不仅支持依赖关系判断,更支持较复杂的仿射划分。MLIR 'affine' dialect 尤其适用于存在大量复杂的高维数组操作的场景,通过仿射划分自动分割出可以并行的部分,应用常常能因此得到成倍性能提升。
参考
1. Compilers: Principles, Techniques, & Tools, Second Edition. Jeffrey D. Ullman
2. Practical Dependence Testing. Goff, Kennedy, Tseng
转载自鲲鹏社区:https://www.hikunpeng.com/zh/developer/techArticles/20231123-2















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









