






前言
一、SD主流 UI
Stable Diffusion(SD)因为其开源特性,有着较高的受欢迎程度,并且基于SD的开源社区及教程、插件等,都是所有工具里最多的。基于SD,有不同的操作界面,可以理解为一个工具的不同客户端。WebUI和ComfyUI是两种较为流行的操作界面选项
1. WebUI :
优点:界面友好,插件丰富,新手小白基本也能秒上手
缺点:吃显存,对配置要求较高,出图较慢
2. ComfyUI :
优点:性能好,速度快,支持工作流的导入导出分享,对小显存友好(GPU小于3G以下依然可以工作),基于工作流,对出图逻辑理解更清晰
缺点:对新手用户不太友好,有一定学习成本
二者各有优缺点,根据自身情况选择即可。我个人更推荐ComfyUI
所有的AI设计工具,模型和插件,都已经整理好了,👇获取~### 二、ComfyUI 能干啥?
-
基础文生图
-
基础图生图
-
真人转动漫/动漫转真人
-
线稿上色
-
老旧照片修复
-
隐藏艺术字
-
改变人物姿态
-
四维彩超宝宝长相预测
-
红包封面
-
真人电子AI写真定制
-
赛博朋克风格转换
-
专属表情包
-
手机壁纸
-
更多:这里不一一举例了,类似的玩法在网上可以看到很多,ComfyUI只是一个工具,具体如何应用,就要依靠自身的想象力了

三、汉化
• 整合包可以直接点击右边设置小按钮,并对语言设为中文即可
• 非整合包需自行下载汉化插件,通过插件管理器搜索AIGODLIKE-ComfyUI-Translation安装即可,或类似下载插件管理器的方式在custom_nodes下git clone https://github.com/AIGODLIKE/AIGODLIKE-ComfyUI-Translation.git后重启ComfyUI
四、 学习参考
ComfyUI的流程导入导出功能非常便捷,这让用户之间可以轻松地分享和学习彼此的工作流程,甚至直接采用现成的工作流。目前,有许多在线平台提供工作流的分享服务。通过导入其他用户的工作流,您可以进行学习并实践,这对于个人技能的提升和知识的积累大有裨益
- ComfyUI官方示例:https://comfyanonymous.github.io/ComfyUI_examples/
- 基础工作流示范:https://github.com/wyrde/wyrde-comfyui-workflows
- comfyworkflows:https://comfyworkflows.com/
- esheep(国内站点,访问快):https://www.esheep.com/
插件安装
当我们采用他人创建的工作流时,有时会遇到他们所使用的一些节点我们本地并未安装,从而出现了节点缺失的问题。面对这种情况,我们需要补充安装这些缺失的节点。以下是几种常见的插件安装方法:
1.通过界面管理器安装:如果你处于可以顺畅访问互联网的环境,推荐直接在用户界面的管理器中搜索并安装所需的节点,这通常是最简便的方法。如果无法顺畅访问互联网,这个过程可能会变得相对复杂。
2.使用启动器安装:如果你使用的是集成包,可以通过启动器来安装缺失的插件。具体步骤为:进入版本管理界面,选择“安装新插件”,然后搜索并选择所需的插件进行安装。
3.手动下载插件:你也可以选择单独下载所需的插件包。下载并解压后,将插件文件放置到ComfyUI的安装目录
五、文生图工作流
初次运行ComfyUI,一启动便会看到一个预设的工作流程,这通常是一个入门级的文本到图像的工作流。让我们借此机会对构成这个工作流的基础节点进行一番简要说明。
在ComfyUI中,节点和节点之间的链接以相同颜色链接即可,熟悉常用工作流之后,大概就能明白节点的链接逻辑了
1、K采样器
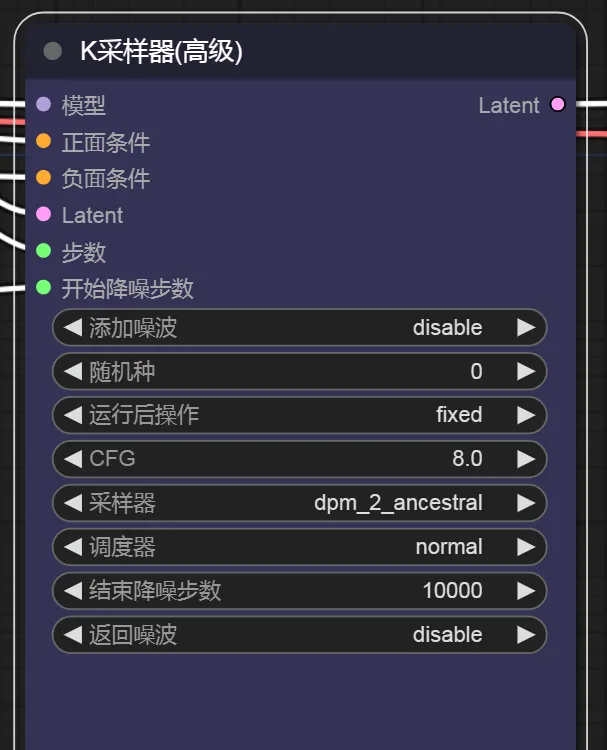
K采样器是SD出图流程中的核心节点,所有节点载入,数据输入,参数配置,最后都会汇总到K采样器,它会结合载入的模型,提示词的输入以及Latent输入,进行采样计算,输出得到最终图像
Latent,即潜空间,可以理解为SD内部流程中的图像格式,如果我们将图像作为输入,则需要通过VAE编码将其转换为Latent数据,在最后输出时,我们也需要通过VAE解码将其转换为像素空间,也就是我们最终图像
2、Checkpoint加载器
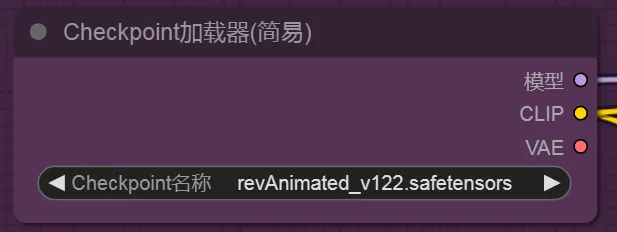
checkpoint 也就是大模型,这个节点是起始点,需要选择相应的大模型,以及vae输入给采样器,clip则连接正反向提示词 其中VAE可以直接使用大模型的vae去链接,也可以单独使用vae解码节点,来选择自定义的vae
3、CLIP文本编码器
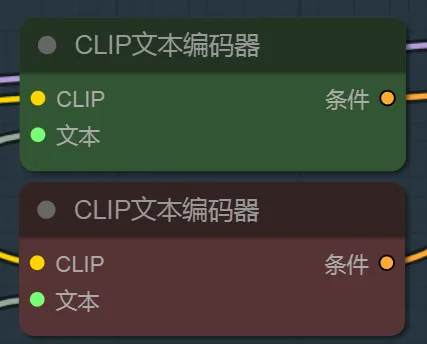
CLIP节点则需要输入提示词,其中CLIP节点需要两个,一个作为正向提示词链接K采样器,一个作为负向提示词链接采样器
4、空Latent
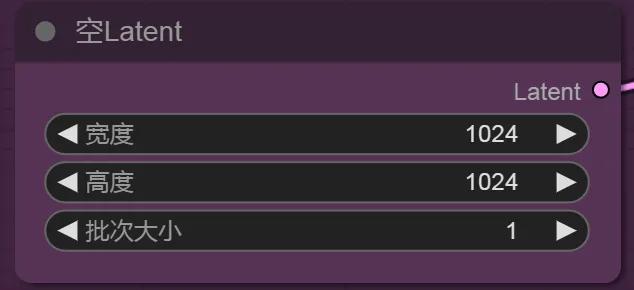
使用空latent建立潜空间图像,这里主要用于控制图像尺寸和批次数量的
5、VAE解码
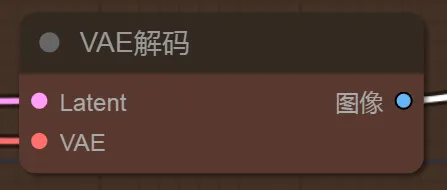
前面已经提到对于Latent潜空间图像和输出的像素图像之间,需要进行一次转换,VAE解码节点则是对这个过程转换的节点
6、保存图像

顾名思义,即保存当前生成的图像,保存的图像除了在当前页面能看到以外,也可以在本地文件夹目录(x:\xxx\ComfyUI根目录\output)下看到所有生成的图片
默认流程整体就这么简单,输入提示词,点击添加提示词队列,即可生成你的第一张ComfyUI图片了
六、图生图工作流
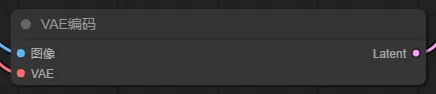
使用过WebUI的小伙伴可能要问了,文生图我懂了,那图生图怎么做呢?其实很简单,加一个图像载入节点作为数据输入就好了。前面提到,像素空间到潜空间需要做一次转换,所以我们就需要“加载图像”和“VAE编码”两个节点。
1. 加载图像
2. VAE编码
通过简单地加两个节点,即把工作流改为了最基础的图生图模式,如以下工作流就是一个简单通过动漫大模型把真人转动漫的工作流,其中K采样器的降噪也就是对应WebUI中的重绘幅度,这个值越大生成图像越靠近提示词,越小则越靠近参考图像,我这里用的 0.6,看情况调整即可
七、Lora
在Stable Diffusion框架内,Lora技术扮演着至关重要的角色。Lora的引入显著降低了模型训练的成本,使得用户能够以较低的资源消耗训练出符合自己需求的Lora模型。将Lora应用于Stable Diffusion的微调模型时,可以通过特定的训练素材对模型的主体风格或画面特征进行精细调控。通过Lora的训练过程,用户可以定制出具有特定画风、特定人物特征或特定物体表现的模型。
lora 是对大模型的后续微调,所以我们在ComfyUI中添加lora只需要在大模型后面新加Lora节点即可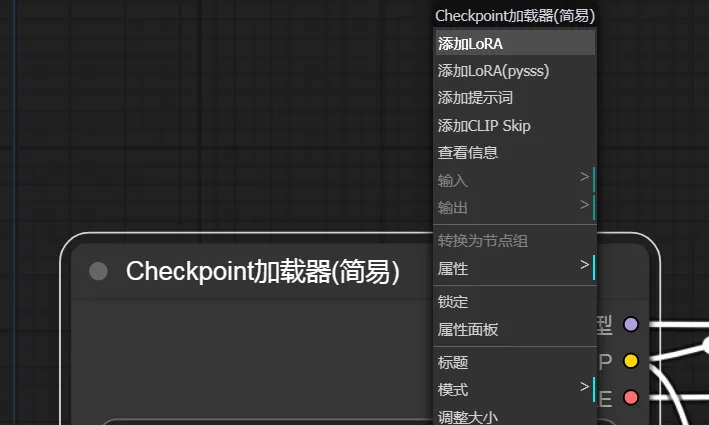
当然 lora 不仅仅控制风格,可以把人物、衣服等进行炼制,控制出图的人物形象,控制出图人物的穿着都是可以的,这里推荐大家去C站寻宝吧,总有一款你喜欢的,如果没有也可以自己炼制哦。
我们以上面的图生图工作流为例,对整体工作流添加lora节点添加宫崎骏画风lora,于是我们就得到了真人转宫崎骏动漫画风的图片
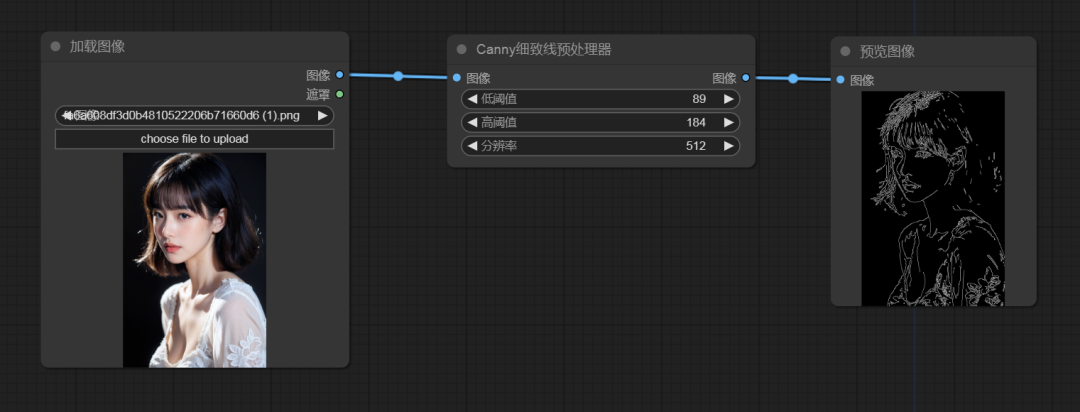
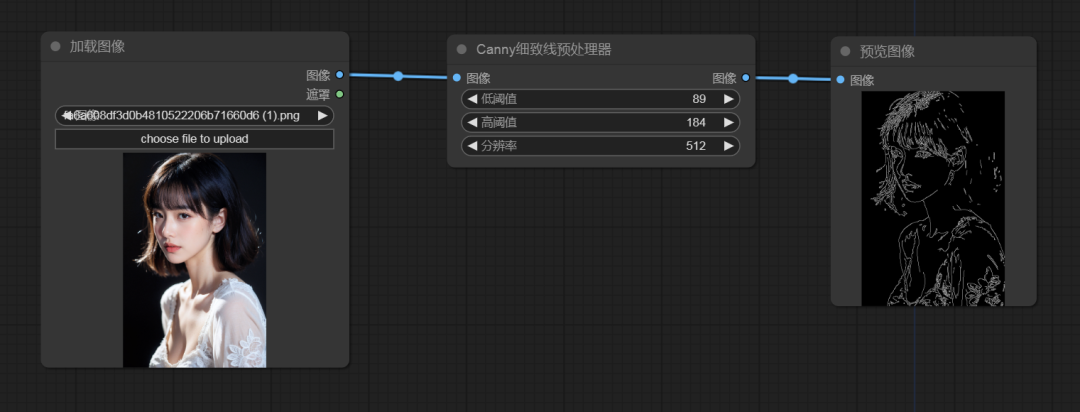
八、ControlNet
Stable Diffusion(SD)与其他AI绘图工具相比,其突出优势在于其卓越的图像控制能力。这种控制力主要源自其核心组件——ControNet模型
ControINet 有独立的控制图像,通过对图像的预处理,再结合提示词进行生成图像 不同的预处理可以对生成的图像进行不同的控制,一般有风格约束、线条约束、姿态约束、景深控制等,不管是WebUI还是ComfyUI,都有强大ControlNet,这里不详细介绍ControlNet,主要讲下如何在ComfyUI中使用ControlNet,后续可能专门写一篇ControlNet的详细介绍
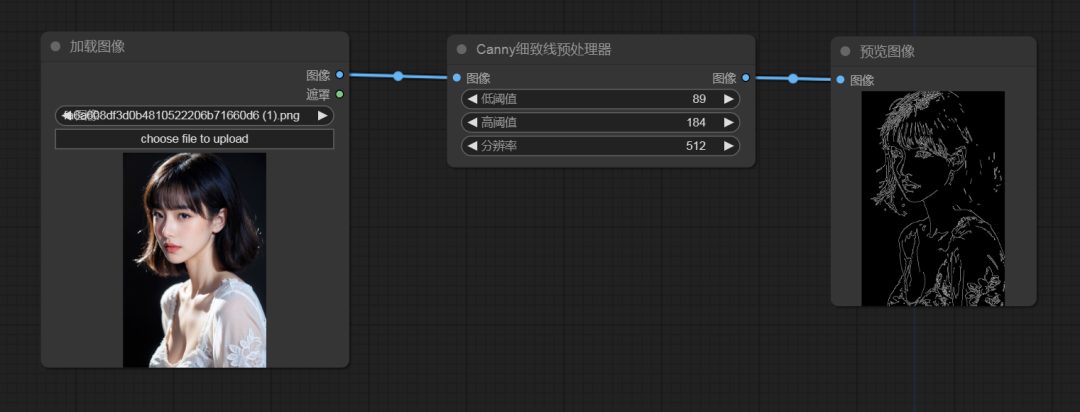
因此,在使用ControlNet时,需要添加几个关键节点:预处理器、ControlNet应用、ControlNet加载器、加载图像、预览图像、VAE解码
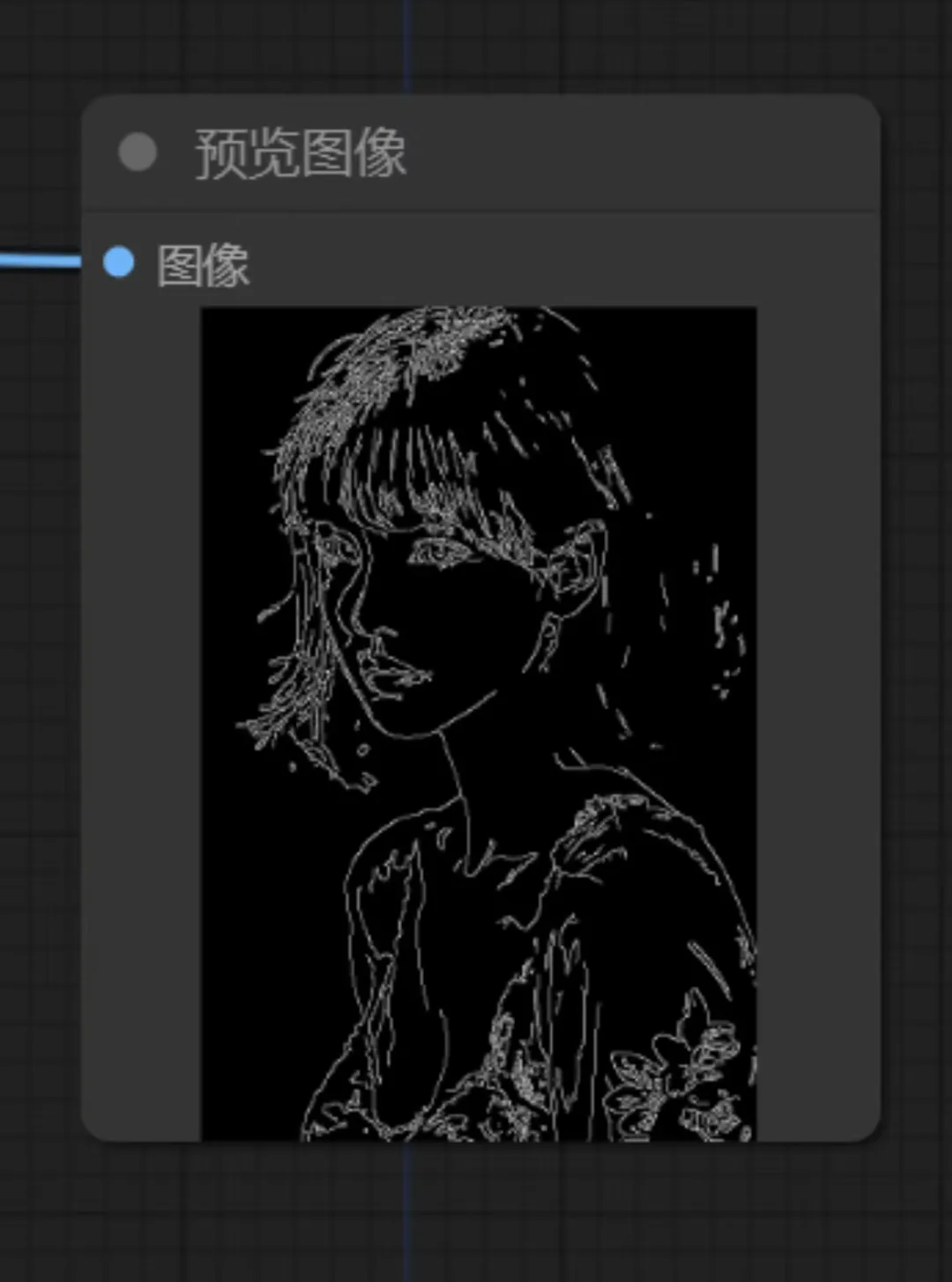
1. 预处理器
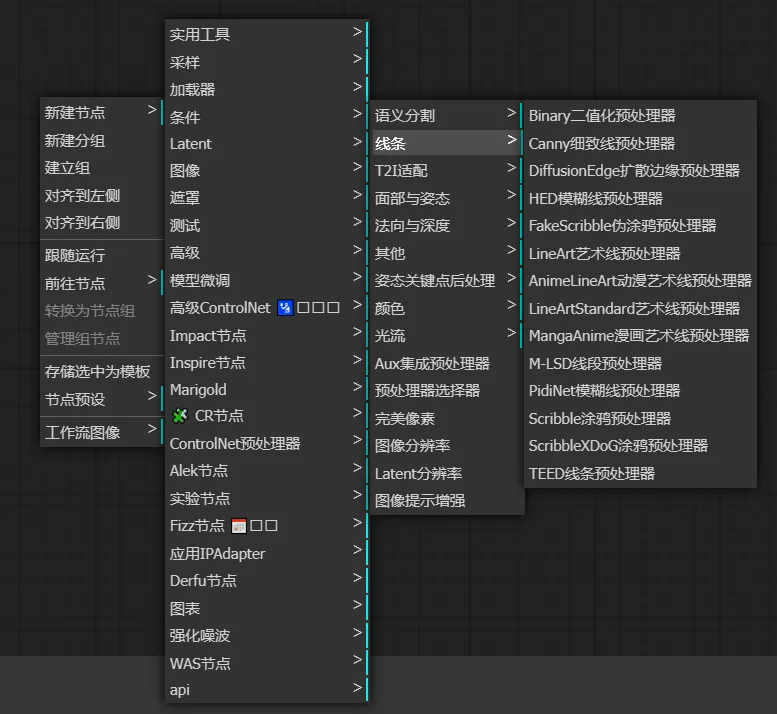
预处理器的作用是选择需要对图像进行的控制方向,这里我们以线条控制为例,让预处理器导出一份预览图像,这样我们能直观的看到预处理的结果
九、Comfyui资源推荐
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









