程序纠错(异常处理)
1.try…except…
try:
user_weight = float( input("请输入您的体重(单位: kg) : "))
user_height = float(input("请输入您的身高(单位:m): "))
user_BMI = user_weight / user_height
except ValueError:
print("输入不为合理数字,请重新运行程序,并输入正确的数字。")
except ZeroDivisionError :
print("身高不能为零,请重新运行程序,并输入正确的数字。")
except:
print("发生了未知错误,请重新运行程序。")
else:
print("您的BMI值为:" + str(user_BMI))
finally:
print("程序结束运行。")
2.assert断言
- 后面跟
True或False的句子,True就无事发生,False则报错 ,但是报错程序就会中止
3.unittest(不会中止)
class ShoppingList:
"""初始化购物清单,shopping_list是字典类型,包含商品名和对应价格
例子:{"牙刷": 5, "沐浴露": 15, "电池": 7}"""
def __init__(self, shopping_list):
self.shopping_list = shopping_list
"""返回购物清单上有多少项商品"""
def get_item_count(self):
return len(self.shopping_list)
"""返回购物清单商品价格总额数字"""
def get_total_price(self):
total_price = 0
for price in self.shopping_list.values():
total_price += price
return total_price
- 测试
shopping类(测试文件名和测试类都要test_开头)
import unittest
from shopping_list import ShoppingList
class TestShoppingList(unittest.TestCase):
def setUp(self) -> None:
self.shopping_list = ShoppingList({"牙刷": 5, "沐浴露": 15, "电池": 7})
def test_get_item_count(self):
self.assertEqual(self.shopping_list.get_item_count(), 3)
def test_get_total_price(self):
self.assertEqual(self.shopping_list.get_total_price(), 53)
- 在终端中输入
python -m unittest即可进行测试
解析html内容(bs4中的BeautifulSoup)
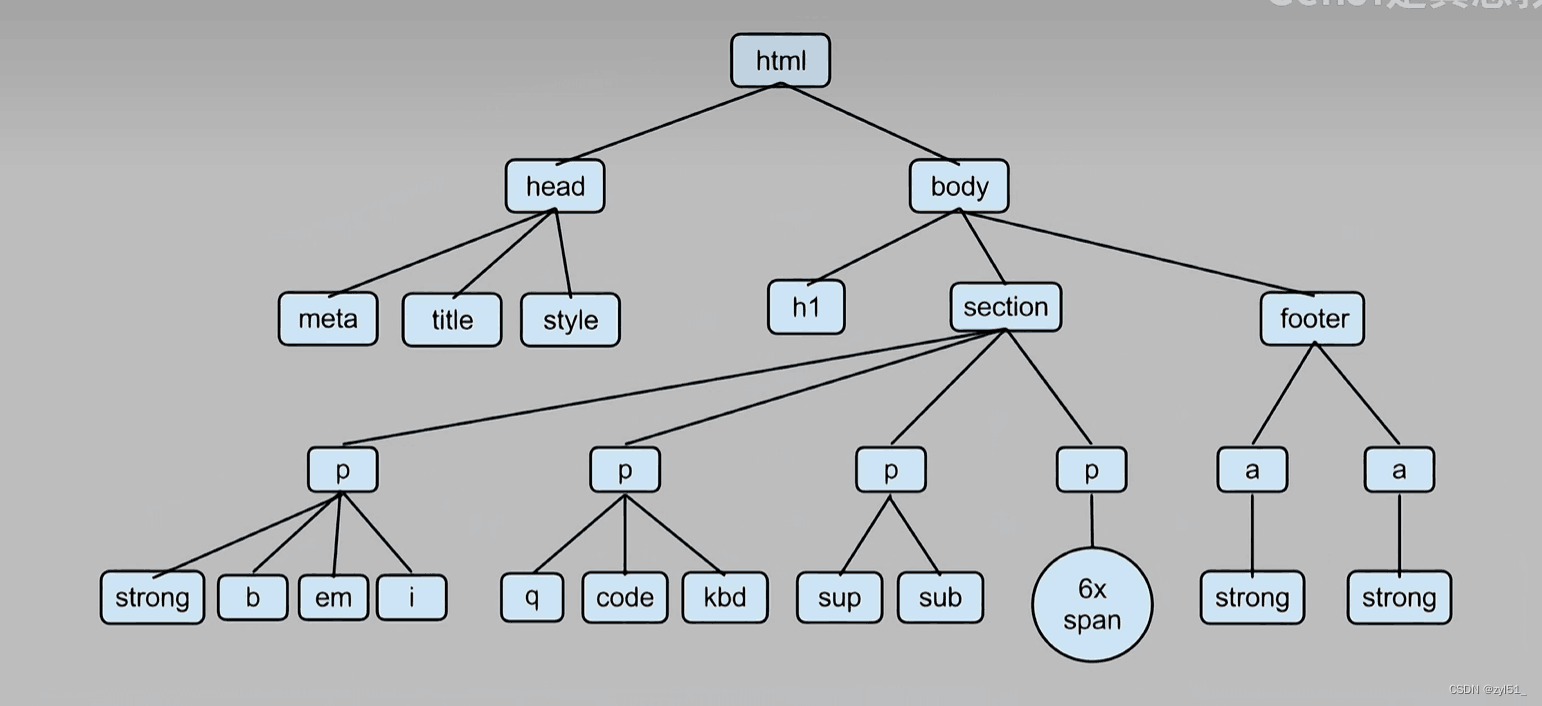
html结构图
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
for start_num in range(0, 250, 25):
url = f"https://movie.douban.com/top250?start={start_num}"
response = requests.get(url = url, headers = headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs = {"class": "title"})
for title in all_titles:
if '/' not in title.string:
print(title.string)























 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









