







 该教程详细介绍了如何在Windows操作系统上安装和运行Auto-GPT,包括获取OpenAIAPIKey、安装Python、设置虚拟环境、安装依赖包,以及解决可能出现的问题,如无效APIkey和网络超时等。
该教程详细介绍了如何在Windows操作系统上安装和运行Auto-GPT,包括获取OpenAIAPIKey、安装Python、设置虚拟环境、安装依赖包,以及解决可能出现的问题,如无效APIkey和网络超时等。
Windows安装、运行Auto-GPT
第一、准备条件
OpenAI Key,请登录官网获取
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
第二、环境搭建
2.1安装python(3.8以上版本)
a、下载Python安装包
在 Download Python | 官网选择Python版本并下载,本教程用的 Python3.10
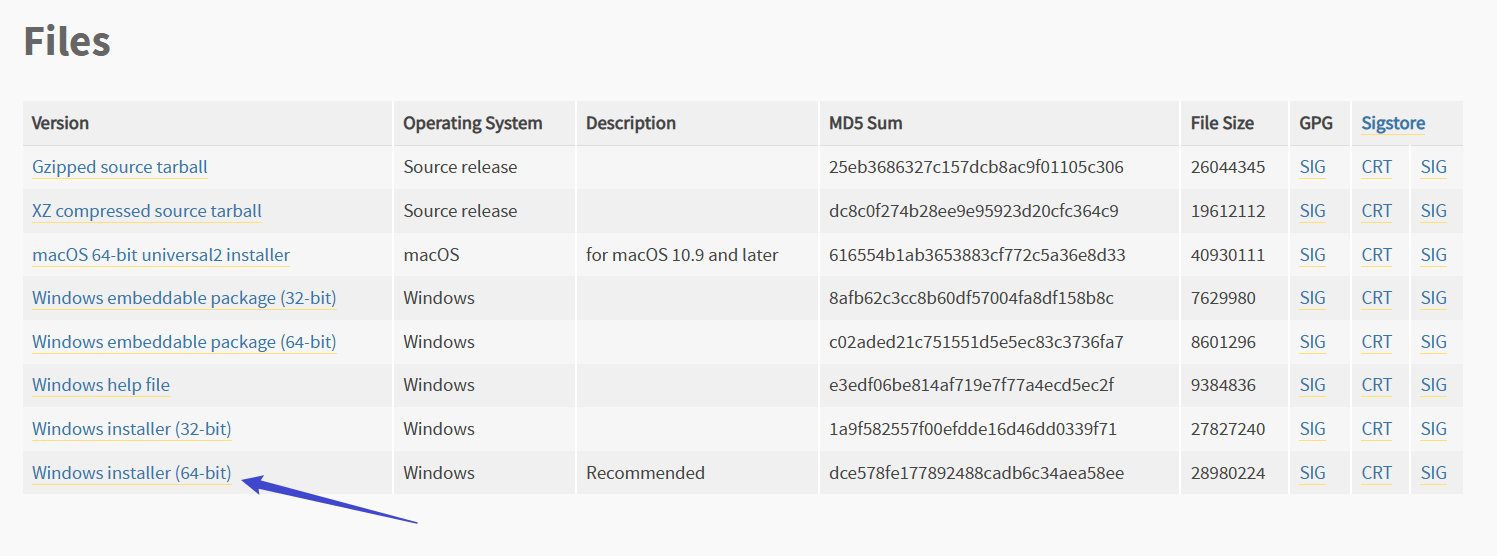
安装python
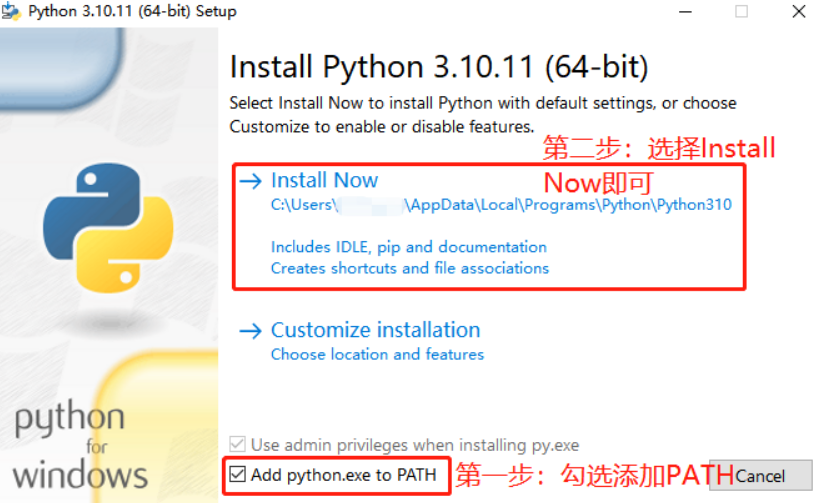
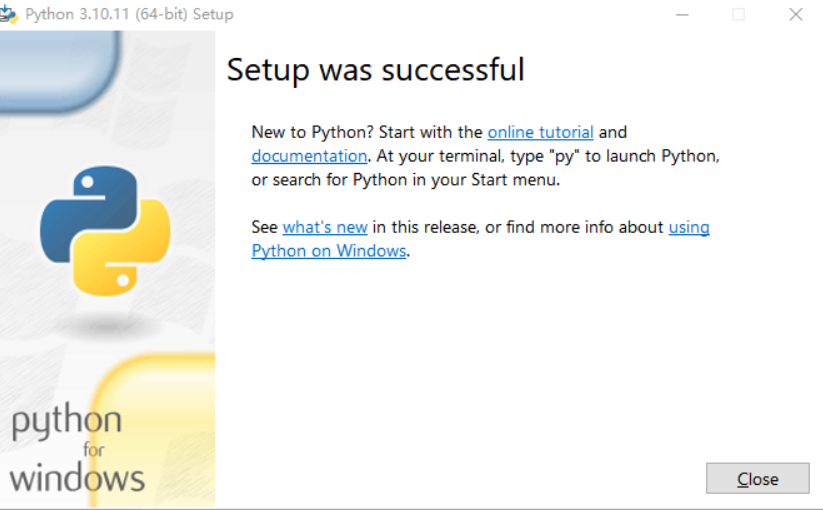
b、验证是否安装成功?
- 按快捷键win+R,打开运行面板,输入"cmd",然后点击"确定"
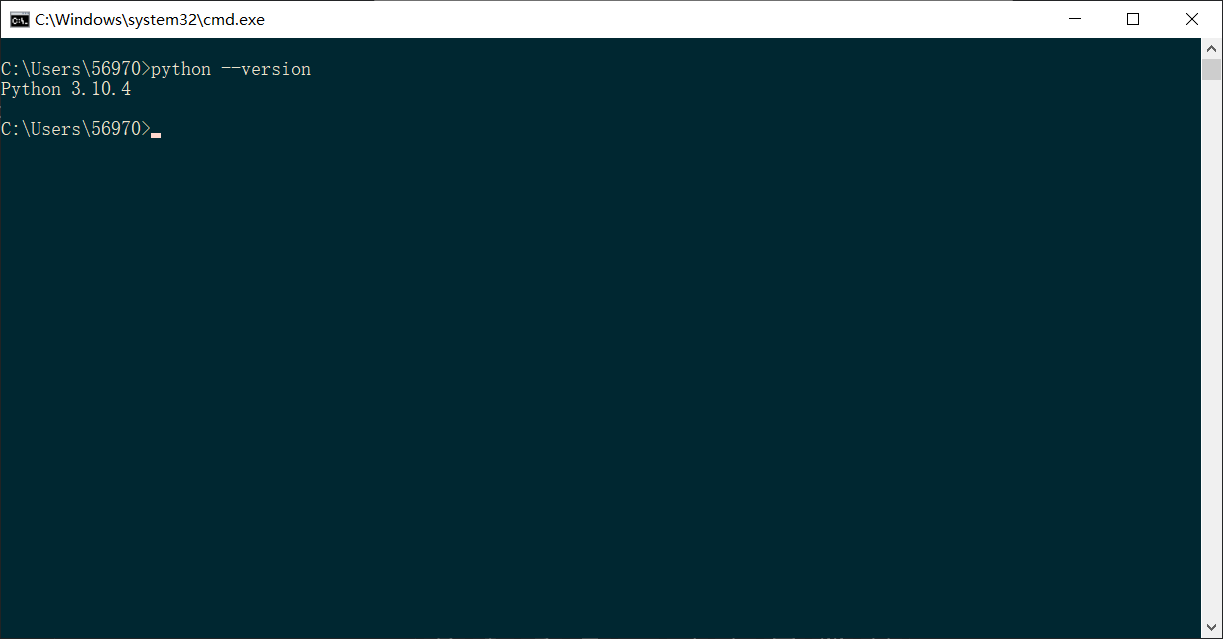
- 进入windows命令提示符窗口,输入命令"python --version",然后回车,出现这样的界面则表示成功安装
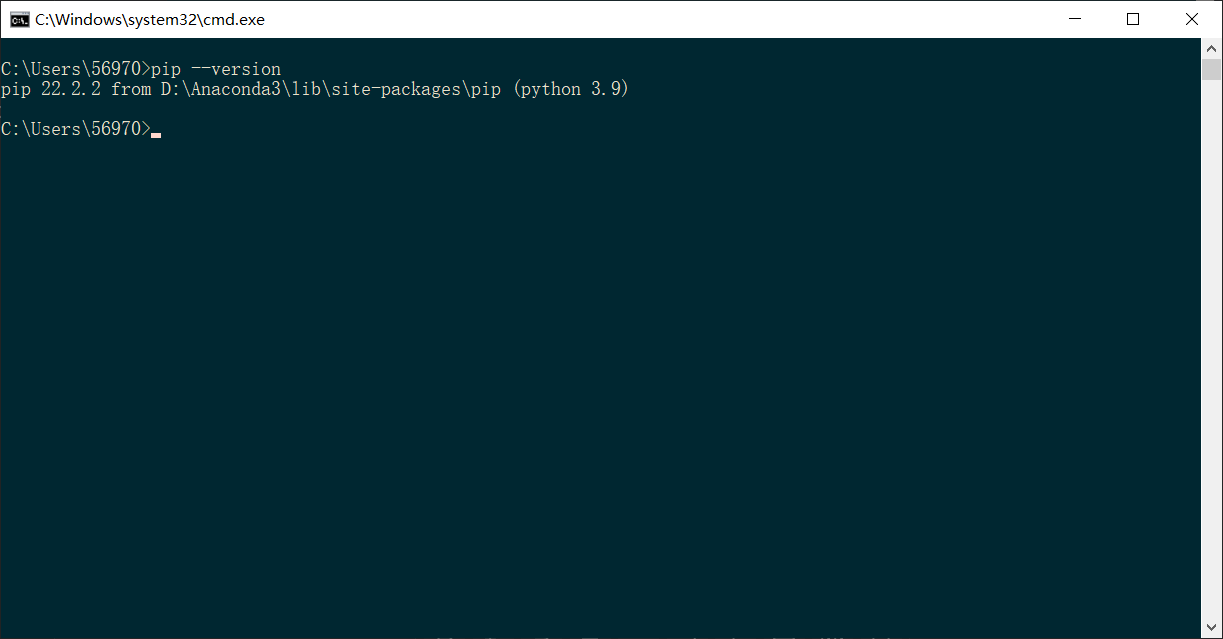
- 检查pip包管理工具是否安装成功?搭建Auto-GPT需要用pip安装所需的python包
在cmd窗口输入指令pip --version,出现版本号,就说明安装成功了。
2.2安装git
a、下载git安装包
Git官网 下载Git安装包,并安装Git
b、安装git
点击安装包,一直点击Next,傻瓜式安装即可。

第三、安装与运行Auto-GPT
1,克隆AutoGPT仓库到本地
git clone -b stable https://github.com/Significant-Gravitas/Auto-GPT.git
2、创建虚拟环境(可选)
为了更好的管理项目和依赖库,我这里创建一个auto gpt的虚拟环境。如果你电脑没有其他的项目,可以直接跳到第3步。
#创建虚拟环境
conda create --name auto_gpt_env python=3.10
#激活虚拟环境
conda activate auto_gpt_env
#退出虚拟环境
conda deactivate
#删除虚拟环境
conda remove --name auto_gpt_env --all
#查看虚拟环境
conda info --envs
3、安装Auto-GPT依赖包
在powershell中输入命令pip install -r requirements.txt,然后回车,安装Auto-GPT所需的Python包,如果是电脑已安装了的Python包,会显示"Requirement already satisfied",未安装的Python包,则会显示"Collecting",最后显示"Successfully installed"则说明安装所需的Python包成功了,这时候Auto-GPT所需的环境已经搭建完成了,下面就可以运行Auto-GPT了。
这一步会耗费一点时间,取决于网速。
4、修改环境变量
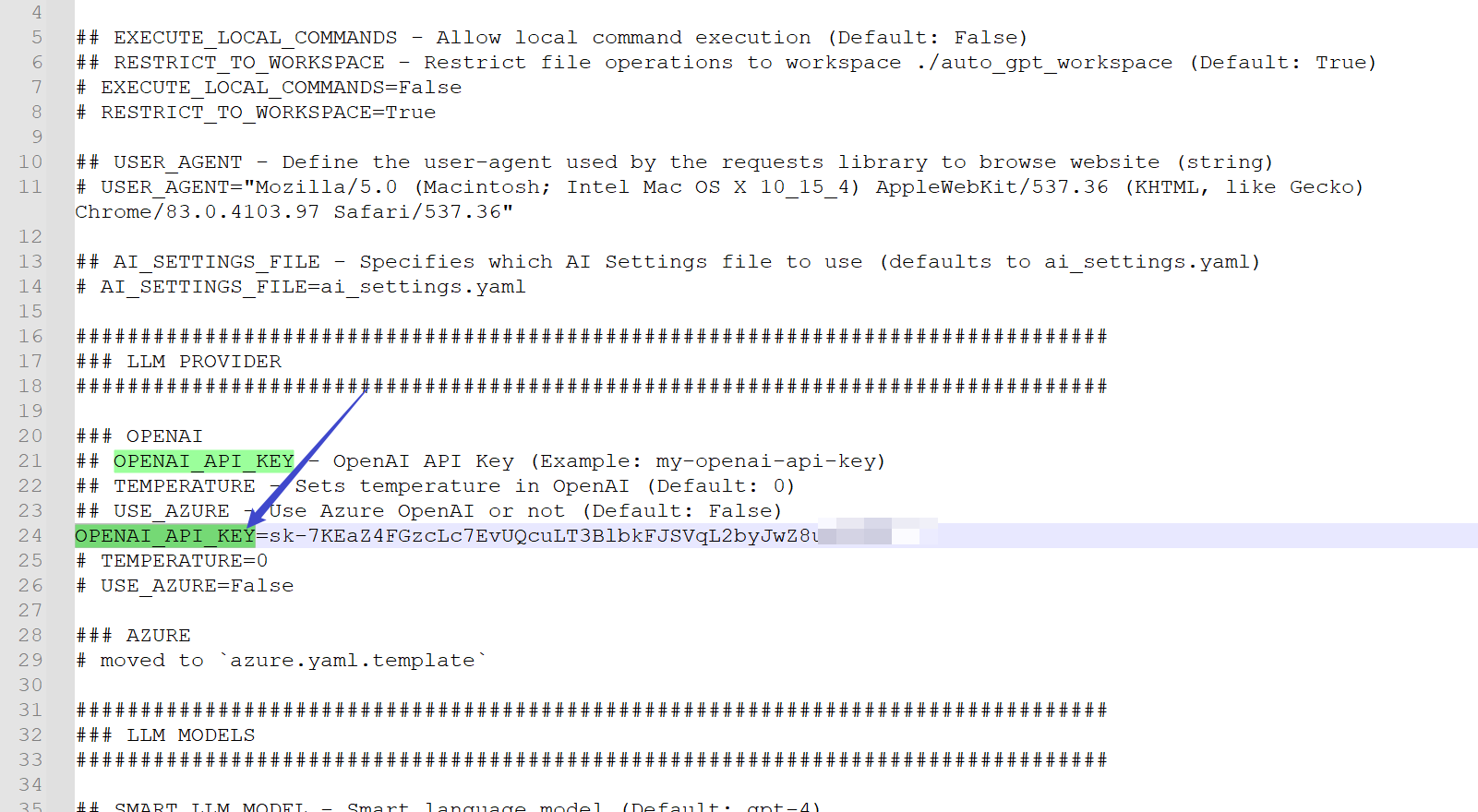
将根目录下的.env.template重命名为.env。打开.env,修改OPENAI_API_KEY的值,以及打开一些环境变量参数。
EXECUTE_LOCAL_COMMANDS=True
OPENAI_API_KEY=你自己的key
5、运行Auto-GPT
python -m autogpt
我让它分析一篇cdc的文章,并提炼观点
medical experts
Analysis of this article: https://www.chinacdc.cn/gwxx/202109/t20210918_248161.html
Extract the main ideas and save them in a file.
finish, close the program
第四、遇到的一些问题
a、无效key问题
问题:Incorrect API key provided" error - I think the repo has a hardcoded OpenAI Key
原因:之前电脑配置了一个OPENAI_API_KEY的环境变量,这个key已经过期。
解决办法:更新环境变量中的key值,或者删除它直接使用.env文件中的key。
b、访问openai timeout
类似的问题:Command google returned: Error: [WinError 10060]
解决办法:
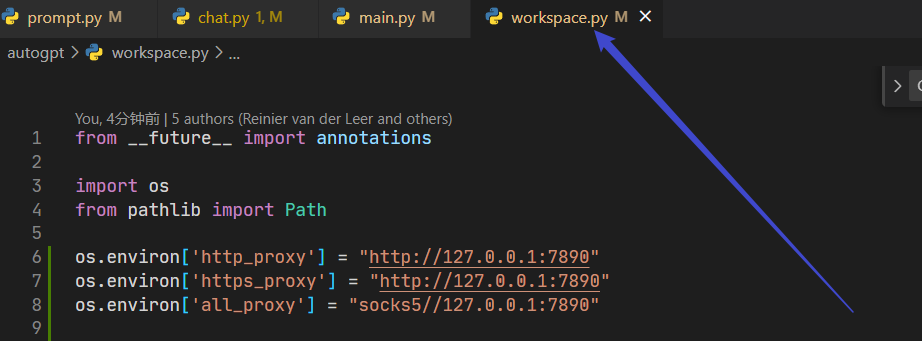
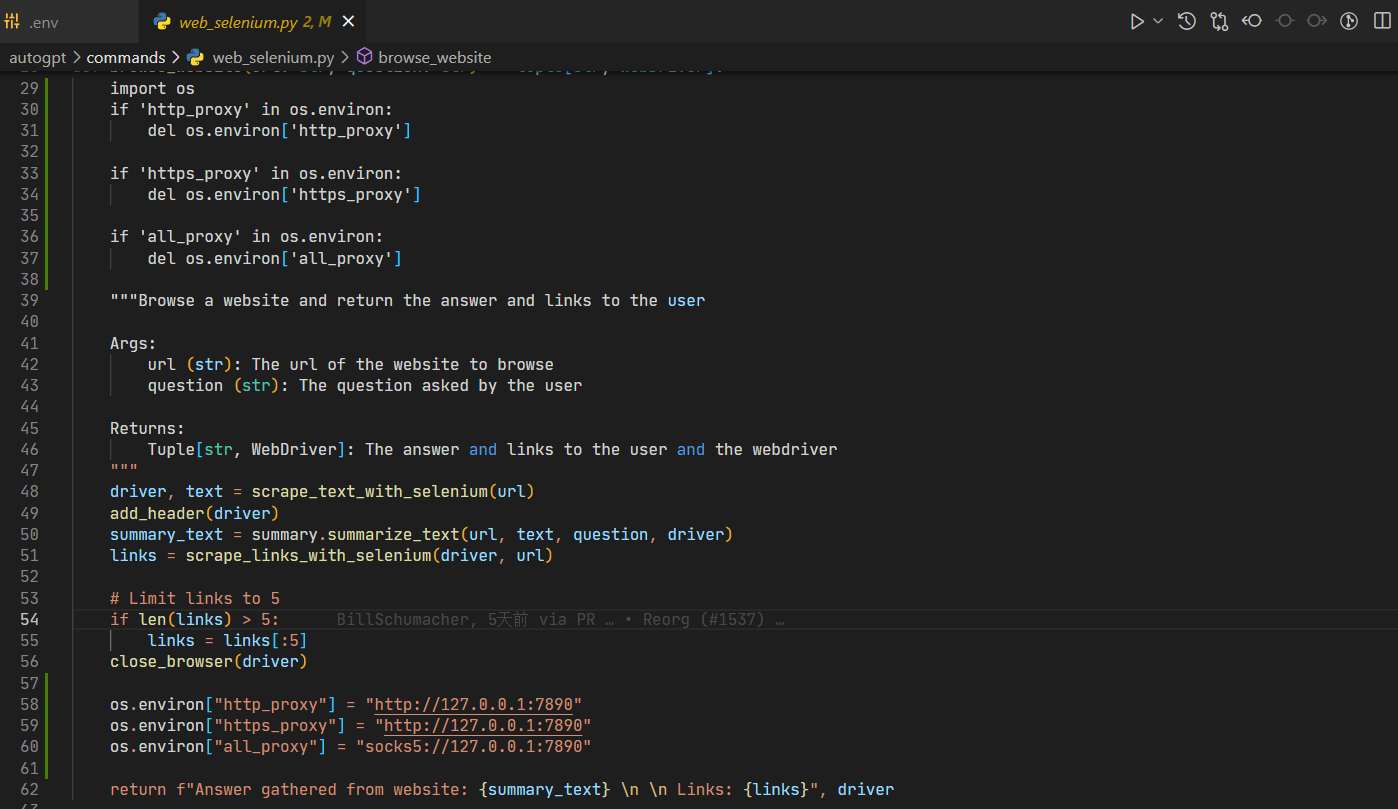
c、中文回复问题
问题:如果要让AutoGPT中文回复,怎么办?
chat.py修改如下代码,测试有效。
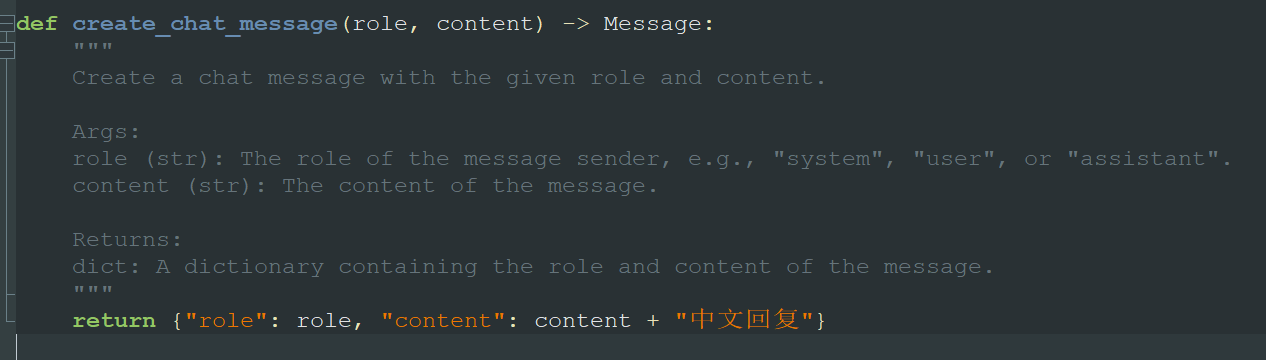
d、openAI 接口,SSL 认证失败 443
ssl.SSLEOFError: EOF occurred in violation of protocol (_ssl.c:1131)requests.exceptions.SSLError: HTTPSConnectionPool(host='openaipublic.blob.core.windows.net', port=443): Max retries exceeded with url: /encodings/cl100k_base.tiktoken (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1131)')))
解决方法,对urllib3 降版本,变为 1.25.11
pip install urllib3==1.25.11

















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









