






LLM推理长度是各大厂商宣传的一个特点,本文从距离衰减视角,探索Transformers架构下的长文本建模本质。
阅读完本文章,能够更进一步思考以下问题:
-
为什么
attention建模需要位置编码? -
RoPE、NTK-RoPE、PI三者有什么区别,为什么能进行拓展文本建模长度? -
位置编码里的高频、低频是如何定义的?
-
高频为什么要外推,低频为什么要内插?
-
高低频对长短距离影响为什么不一样?
-
为什么位置编码的衰减性会震荡?
-
震荡如何产生,如何减弱?
-
如何结合
NTK-RoPE和PI的优势? -
主流模型如何训练拓展长文本能力?
-
如何将文本长度推到200k?
-
为什么当前位置编码普遍使用
NTK类的RoPE? -
绝对位置编码和相对位置编码从注意力分数计算中有什么区别?
TL;DR
熟悉Attention和RoPE 可以直接跳到 Part.3
-
实验,按照高低维切分位置编码,并计算相对位置分数,分析长短距离衰减表现。
-
短距离,高频衰减显著,高频外推,NTK衰减较理想
-
长距离,低频衰减理想,低频内插,PI衰减较理想
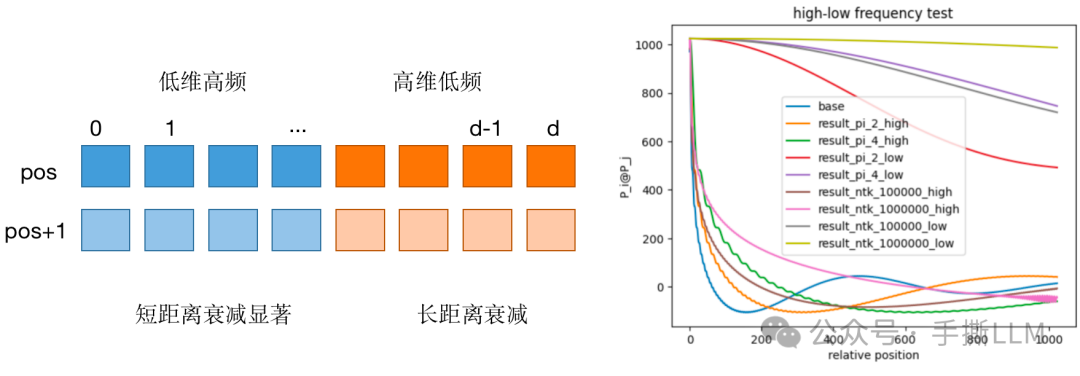
1. 位置编码衰减性
在Transformers模型架构里,一个明显的优势在于Attention机制能够捕捉长距离的文本的特征表达。
文本是离散时序数据,我们通常会假设文字之间距离越近相关性越强,这也是Word2Vec建模的前提,当前词汇窗口内都为相关性的正样本,从而可以在海量样本中学习出词的特征。语言建模就是从词汇序列中学习出语义.
1.1 注意力机制
Attention Is All You Need
1.1.1 注意力机制的本质
假设我们在token输入时,仅有embedding,没有嵌入位置编码
在注意力中,我们通常有一个Query和多个Key,Value,通过scaled-dot-prodct-attention计算出注意力特征。
我们假设有一个位置0对应token的向量Query 和一组Key和Value ,, 那么我们可以计算出注意力输出
其中 所计算结果为标量值,单个query多个key可以得到一组注意力分数,经由可以评估出不同词的权重系数,最终与value进行加权特征组合。
观察到 是描述相关性的权重,如果没有任何外置的相对位置距离信息的描述,在 算子作用下,那么以下两个句子的注意力输出是一样的。
-
Q:我, K:我吃蜂蜜
-
Q:我, K:蜜蜂吃我
以下调换位置后,注意力输出
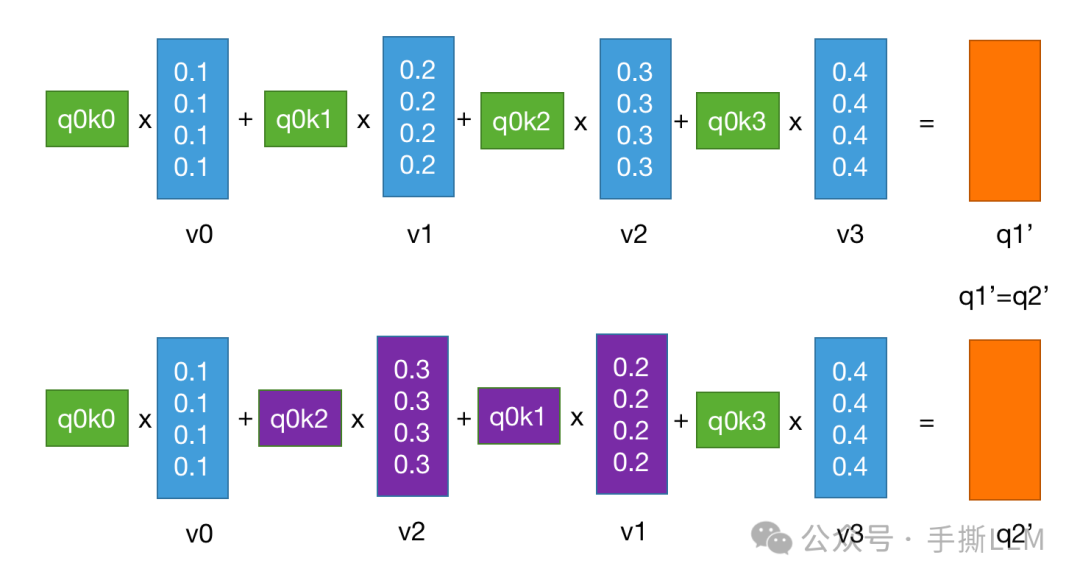
我们使用代码来更加直观:两个不同语义的建模注意力输出是一样的
import torch import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt torch.manual_seed(42) d = 4 l = 4 q = torch.randn(1,d) # 我 k = torch.randn(l,d) # 我吃蜂蜜 v = torch.randn(l,d)
计算注意力输出
# 不带相对位置注意力计算 # ignore scaled q_attn = F.softmax(q@k.transpose(1,0),dim=1)@v print('original order:',q_attn) # 调转位置 shift = [3,2,1,0] k_shift = k[shift,:] # 蜜蜂吃我 v_shift = v[shift,:] # 蜜蜂吃我 q_attn = F.softmax(q@k_shift.transpose(1,0),dim=1)@v_shift print('shift order:',q_attn)
输出为
original order: tensor([[ 0.7919, -0.5901, -0.7274, 0.7564]]) shift order: tensor([[ 0.7919, -0.5901, -0.7274, 0.7564]])
该例子中,没有位置序列信息的情况下,改变词语顺序的句子注意力输出是一样的,但实际语义是一样的,导致没有位置信息输入下,将无法准确的做语言建模
1.1.2 预期带位置关系的注意力分数
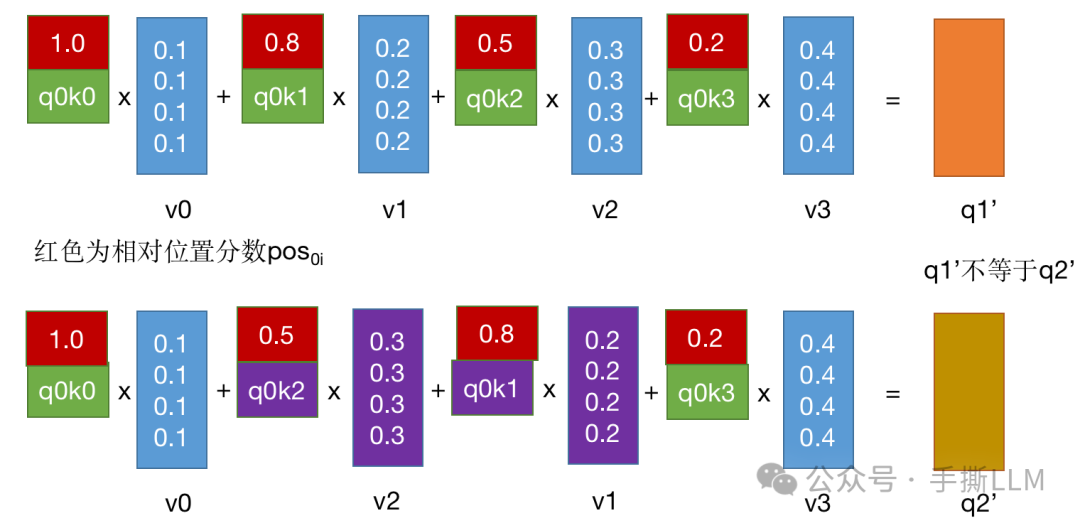
在上述例子中,我们期望的注意力分数带上距离,那么可列下式:
其中代表第i 号位置和第0号位置向量之间额外的相对距离权重,相对距离权重是与维度相关的分数向量,越近的距离那么 就越大,我们可以有
理想的位置编码,应当是随相对位置距离增大而减少,并且是单调衰减关系。
那么以下两个句子就有不同的注意力输出,模型能识别到词在句子中的位置距离,从而刻画出在词汇在上下文中的语义
-
Q:我, K:我吃蜂蜜
-
Q:我, K:蜜蜂吃我
图解在注意力计算里如果包含相对位置关系,那么调换顺序k2v2 和k1v1,会得出不同的注意力输出。
s = 1.0 / torch.tensor([range(1,1+d)]) #p_00, p_10, p_20, p_30 print(s) shift = [3,2,1,0] # 我吃蜂蜜->蜜蜂吃我 # 带相对位置注意力计算 q_attn = F.softmax(s * q @ k.transpose(1,0), dim=1) @ v print('original order with score:', q_attn) # 调换句子词汇顺序后 k_shift = k[shift,:] v_shift = v[shift,:] s_shift = s[:,shift] q_attn = F.softmax(s_shift * q @ k_shift.transpose(1,0), dim=1) @ v_shift print('shift order with score:', q_attn)
输出:
original order with score: tensor([[ 0.5765, -0.8185, -0.5783, 0.5994]]) shift order with score: tensor([[ 0.7374, -0.6995, -0.7031, 0.7216]])
1.2 绝对位置编码
在1.1.2中我们介绍了注意力建模中嵌入相对位置关系的方式,一种最原始的实现来自Transformers原文的绝对位置编码,位置编码向量如下:
这里的 为base, 为词向量维度, 为位置
存在位置向量 , 此时一个词向量的输入为:
将上述输入计算注意力分数,可得
我们如果忽略学习参数,则为定值
以上推导发现,在输入词向量中嵌入绝对位置编码后,在计算注意力分数时,会将相对的距离嵌入进去。这里的注意力计算中的一项里数值计算等同1.1.2中的
那么按照近距离相关性越强假设,我们期望的是
1.3 衰减性实验
至此我们可以编程实现相对位置的分数,以确保建模过程中满足”近距离相关性越强“的假设
定义绝对位置编码
class PositionalEncoding(nn.Module): def __init__(self, d_model=512, max_len=1024, base=10000.0, pi=1.0, device='cpu'): super(PositionalEncoding, self).__init__() self.encoding = torch.zeros(max_len, d_model, device=device) self.encoding.requires_grad = False pos = torch.arange(0, max_len, device=device) pos = pos.float().unsqueeze(dim=1) _2k = torch.arange(0, d_model, step=2, device=device).float() self.theta = torch.sin(pos / (pi * (base ** (_2k / d_model)))) self.encoding[:, 0::2] = torch.sin(pos / (pi * (base ** (_2k / d_model)))) self.encoding[:, 1::2] = torch.cos(pos / (pi * (base ** (_2k / d_model)))) def forward(self, x): batch_size, seq_len = x.size() return self.encoding[:seq_len, :]
计算相对位置距离分数, 即位置0处与[:64000]位置处计算对应分数
# 绝对位置衰减实验 d_model = 512 max_len = 1024 # 64000 x1 = range(max_len) pe = PositionalEncoding(d_model, max_len).encoding result = pe[1,:] @ pe.transpose(1,0) result_1024 = result.tolist()
绘制图像为
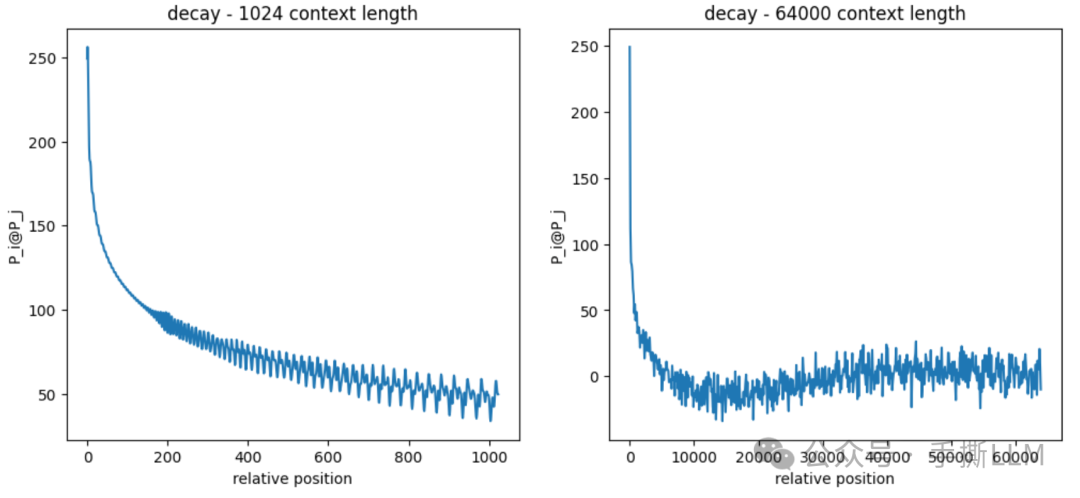
实验结果展示在1024长度和64K长度向量之间的位置编码
-
实验结果表明:在
1024长度下,约在150位置前满足相对位置分数满足衰减规律,而后存在震荡 -
64K长距离下,相对位置距离计算已经不满足衰减了
1.4 期望的位置编码性质
我们希望的衰减性曲线为:
-
可以在无限长度下保持单调衰减
-
衰减曲线是非线性的,近距离衰减变化迅速, 远距离衰减平缓
-
在衰减过程中,尽可能少震荡,我们将在Part.4探究衰减性震荡
-
在
1024长度下,一种简单的方式为增大位置编码的特征维度,dim=4096时呈现较好的衰减性,dim=512时过早出现震荡
1.5 小结
在本章节中,我们从Attention机制出发,为什么需要有位置编码。一个本质的问题是,不同相对距离的特征对注意力特征的贡献是不一样的。
我们在这里从衰减性视角观察,好的位置编码应该是单调非线性衰减。接下来将进一步讨论以RoPE为代表的位置编码改进及分析。
错误的建模将导致PPL爆炸,如下为YaRN的长文本建模实验结果。
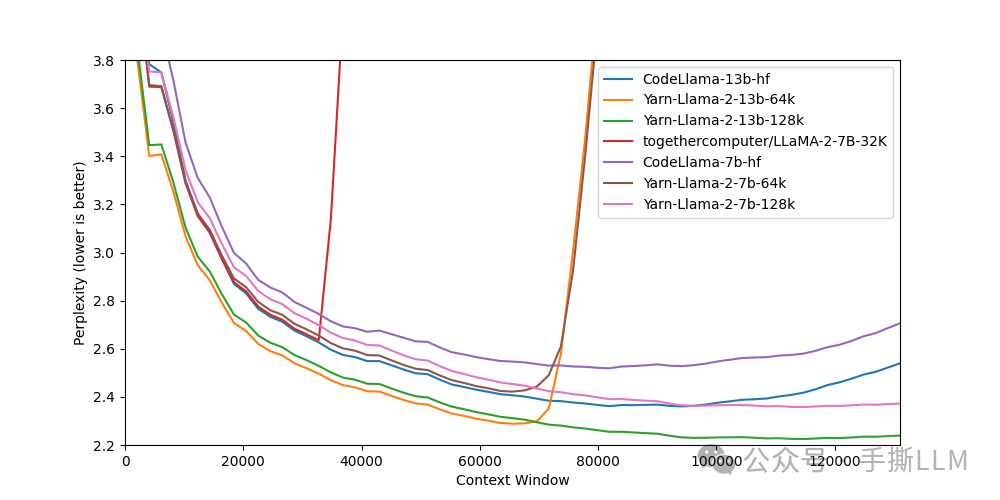
注意:这里仅直觉联系位置编码衰减性与PPL对应关系,未完备说明衰减性好等同于PPL能收敛
2. RoPE扩展方案
2.1 RoPE 位置编码形式及衰减性
RoFormer: Enhanced Transformer with Rotary Position Embedding
目前LLMs主流的位置编码都是RoPE,位置编码不在输入时候与embedding相加, 而是在计算注意力分数之前,对和 做一次旋转变换, 为:
我们仅取2个维度的旋转位置编码,那么我们可以参照1.2推导,得出RoPE相对位置编码分数
其中
假设对
使用RoPE变换后,其score计算方式如下
则
可见在旋转位置编码形式下, 计算注意力分数时,就能将相对位置信息嵌入。
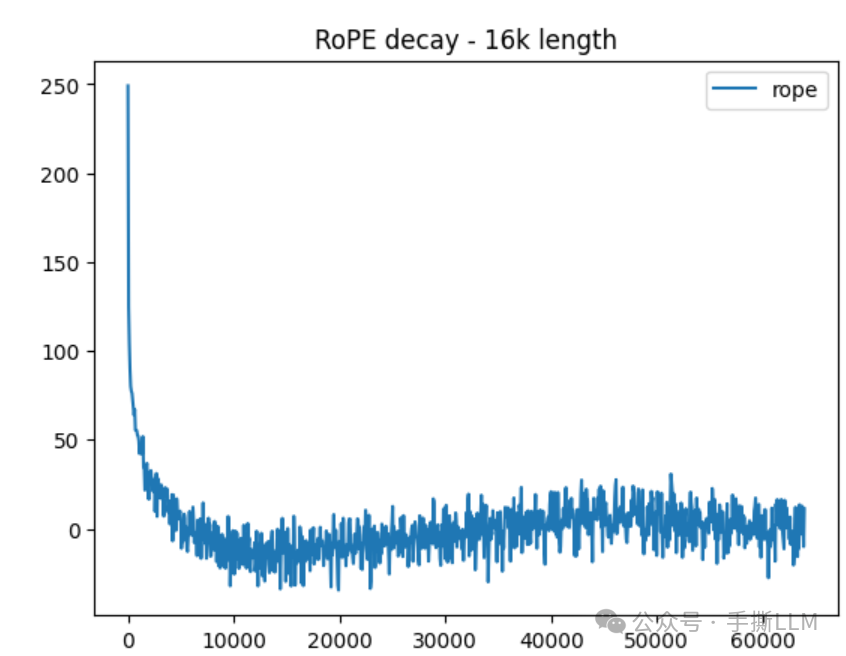
同样我们假设,,那么同样可以进行衰减性实验:
使用Transformers库实现的的Llama位置编码进行实验
from transformers.models.llama.modeling_llama import LlamaRotaryEmbedding from transformers.models.llama.modeling_llama import rotate_half, apply_rotary_pos_emb d_model = 4096 max_len = 64000 Q = torch.ones(1,1,max_len, d_model) K = torch.ones(1,1,max_len, d_model) position_ids = torch.tensor([range(max_len)], dtype=torch.long) rotary_emb = LlamaRotaryEmbedding( d_model, max_position_embeddings=max_len, base=10000.0, ) def call_rope_result(Q, K, position_ids, fn_rope_emb): cos, sin = fn_rope_emb(Q, position_ids) Q_rope, K_rope = apply_rotary_pos_emb(Q, K, cos, sin) result_rope = Q_rope[0,0,[0]] @ K_rope[0,0,:,:].transpose(1,0) #计算相对注意力分数 result_rope = result_rope[0].tolist() return result_rope result_rope_base = call_rope_result(Q, position_ids, rotary_emb)
我们可见RoPE的衰减性保持区间约在16K,之后出现大范围震荡了
2.2 位置内插Position Interplation
2.2.1 PI 算法原理
Extending Context Window of Large Language Models via Positional Interpolation
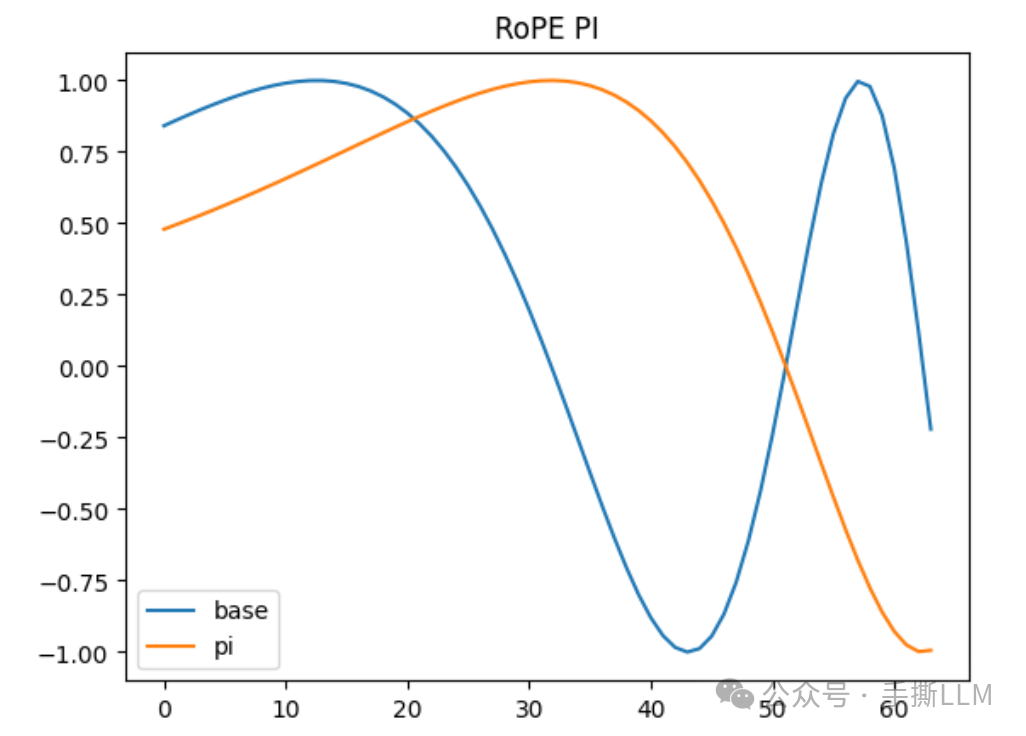
在论文中提出一种内插RoPE的方法,内插形式如下:
其中s为内插的scale,取值s>1
PI的本质是将所有角度同等减少倍数,对应的周期增加,频率降低,带来的影响是高频被抹平
d = 256 x = range(d) x_t = 10000.0**(-torch.tensor(x)/d) y = torch.sin(1/x_t).tolist() y_pi = torch.sin(1/(2*x_t)).tolist()
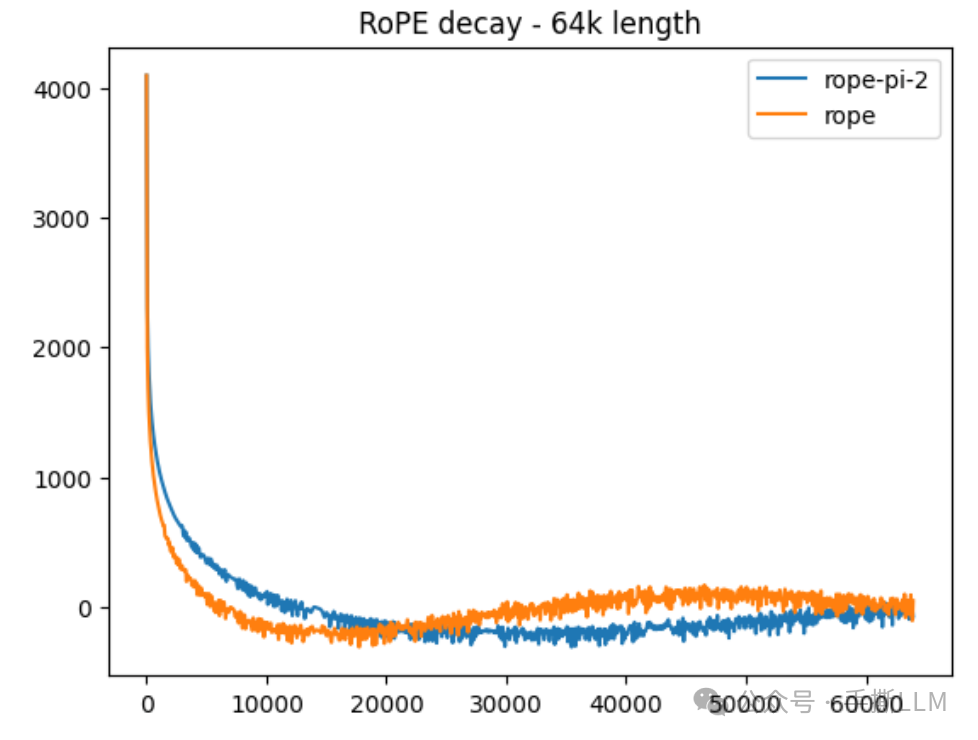
2.2.2 PI衰减性分析
我们以内插形式的RoPE计算衰减性,可见较原始RoPE更好
-
16K前 橙色RoPE衰减更有区分度 -
16K~32K之间,PI仍保持衰减性
2.3 NTK-RoPE
2.3.1 NTK-RoPE推导
NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation
在link里基于NTK理论,描述深度学习关键要学习高频信息,我们可以见到在PI下,高频的信息将会被抹掉。
在NTK-RoPE里通过增大base大小,从而优化RoPE。我们对比base修改前后的RoPE, 取一组sin-cos的RoPE
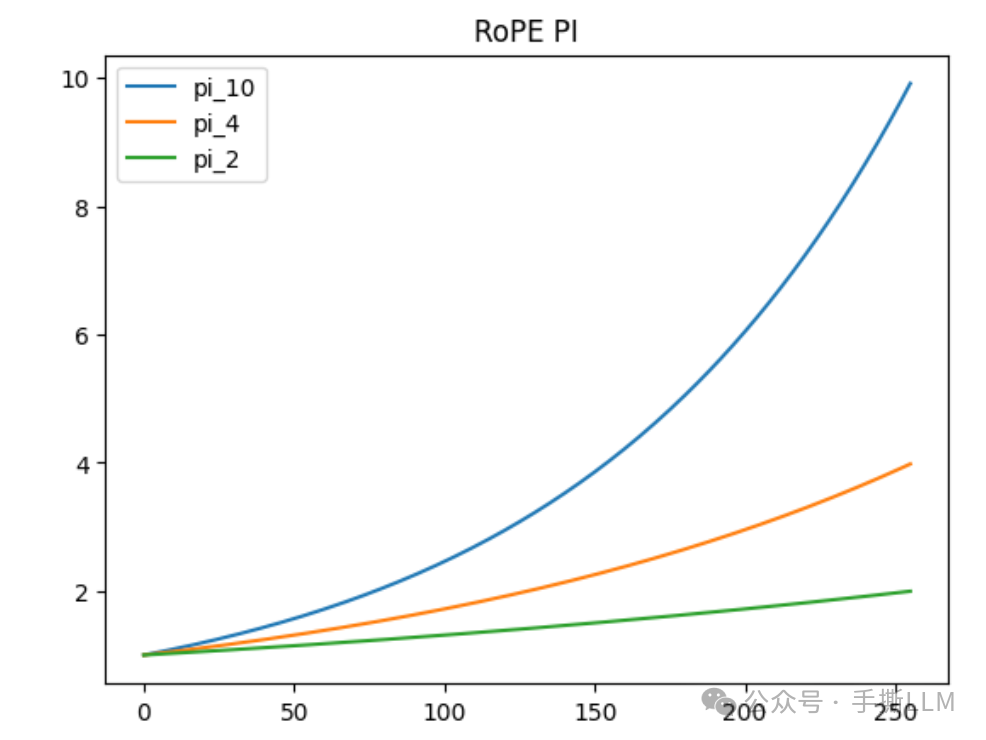
我们增大base,, 我们将取, 那么
可见低维增大base不会有较大的影响, 高维的数据将接近内插形式, 即原本的
我们可以对比和 在不同维度下前后变化, 观测scale数可以发现,随着维度增加,整体角度变化会减小,对应的 scale数越大,低频内插强度更大。
d = 256 # pi_scale = 10.0 x = range(d) x_t_10 = 10.0**(torch.tensor(x)/d) x_t_4 = 4.0**(torch.tensor(x)/d) x_t_2 = 2.0**(torch.tensor(x)/d)
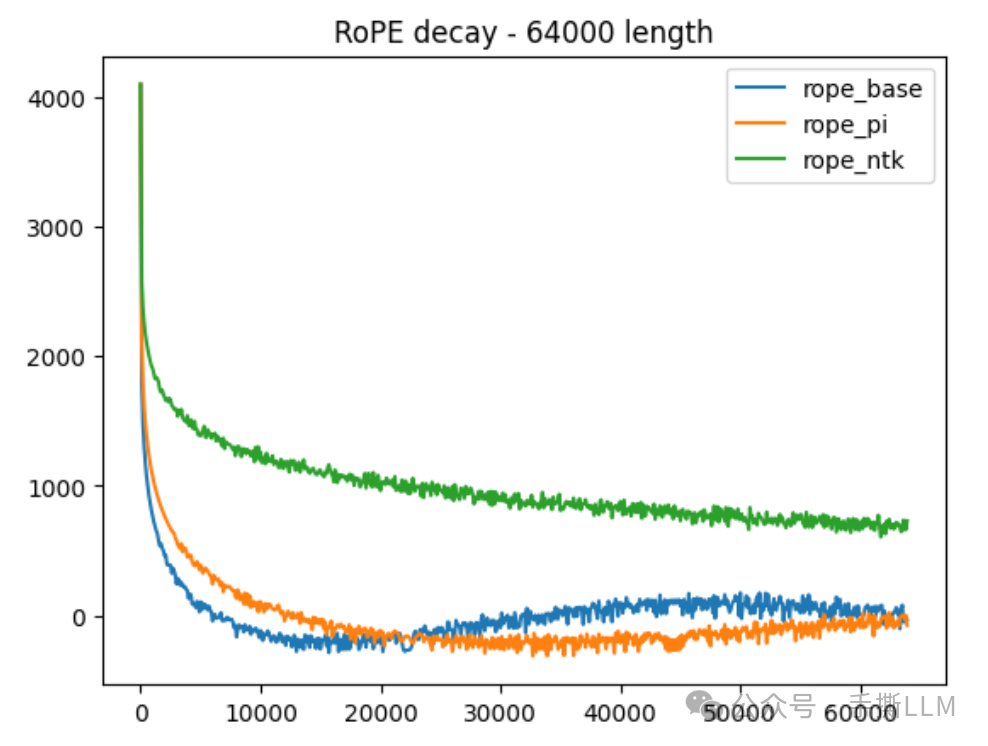
2.3.2 对比不同RoPE优化衰减性
我们同时对比三种RoPE明显发现绿色NTK-RoPE呈现较好的衰减性,轻松外推到64k
2.3.3 NTK-RoPE 解析
Transformer升级之路:10、RoPE是一种β进制编码
在上述博客里已经较直观解析NTK-RoPE 了,RoPE是一种 位置编码
2.3.4 NTK-RoPE 实现
class LlamaDynamicNTKScalingRotaryEmbedding(LlamaRotaryEmbedding): """LlamaRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla""" def forward(self, x, position_ids): # difference to the original RoPE: inv_freq is recomputed when the sequence length > original length seq_len = torch.max(position_ids) + 1 if seq_len > self.max_position_embeddings: # 当模型拓展长度后,才进行NTK-ROPE base = self.base * ( (self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1) ) ** (self.dim / (self.dim - 2)) inv_freq = 1.0 / ( base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(x.device) / self.dim) ) self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: this may break with compilation cos, sin = super().forward(x, position_ids) return cos, sin
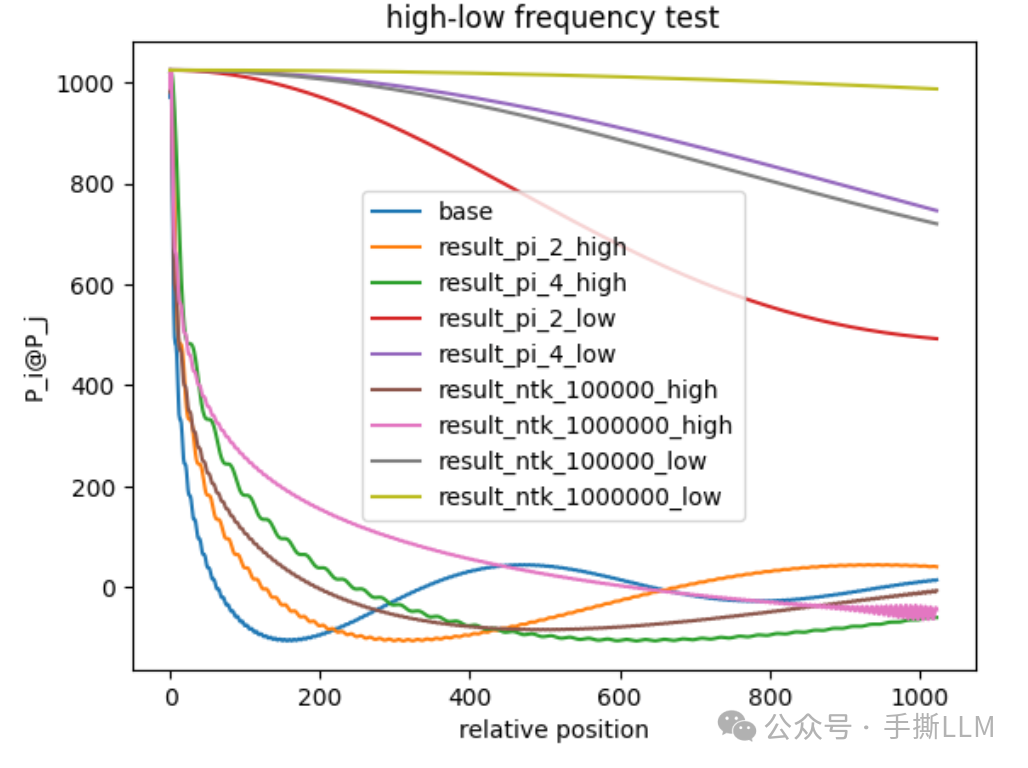
3. 高频外推和低频内插
该章节为本文重点实验,即可窥见不同RoPE方案的高低频编码的衰减表现
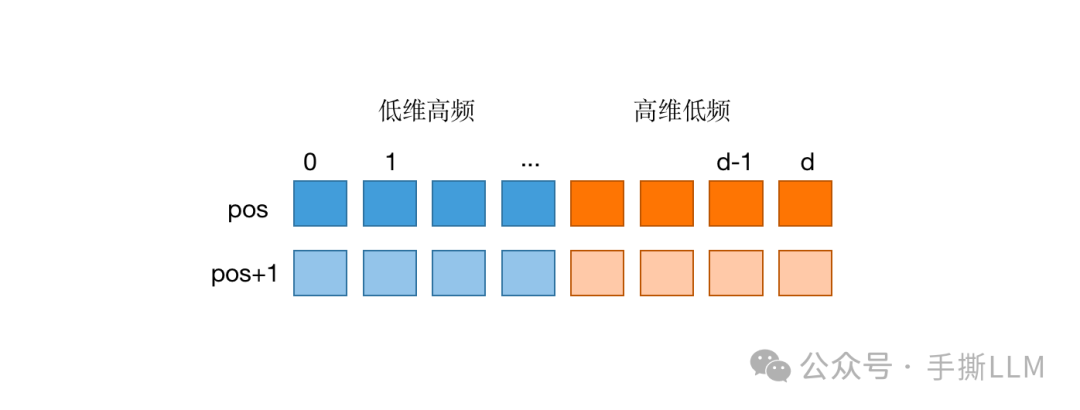
3.1 位置编码高低频定义
首先定义频率,在周期函数中,如 , 越大,频率越大。
在位置编码中,随维度增加,减小,频率越低
那么我们可得:位置编码的低维对应高频,高维对应低频。那么新的问题来了,相对距离衰减到底是由高频影响还是低频?
3.2 高低频衰减性分析
我们将在2.4基础上,将按照高低维分组,分成两组分别计算相对距离分数,观察衰减性。
d_model = 4096 max_len = 1024 d_tmp = int(d_model/2.0) # 从维度切分成两组 x = range(max_len) pe = PositionalEncoding(d_model, max_len).encoding pe = pe[:, :d_tmp] result = pe[1,:] @ pe.transpose(1,0) result_base = result.tolist() # PI scale2 pe = PositionalEncoding(d_model, max_len, pi=2.0).encoding pe = pe[:, :d_tmp] # PI高频率 result = pe[1,:] @ pe.transpose(1,0) result_pi_2_high = result.tolist() pe = PositionalEncoding(d_model, max_len, pi=2.0).encoding pe = pe[:, d_tmp:] # PI低频 result = pe[1,:] @ pe.transpose(1,0) result_pi_2_low = result.tolist() 其他同理 # PI scale4 # NTK ROPE base 100000 # NTK ROPE base 1000000
绘制高低频结果, 以下high:高频, low:低频,实验表明
-
短距离:高频的位置编码衰减区分度高,但距离增大后衰减性变化率变小,高频
NTK-base-100000表现稳定衰减下降,高频PI-scale-2/4都不满足衰减,那么在高频位置内插将影响近距离建模(橙色pi-scale-2) -
长距离:高频的位置编码衰减区分度低,但距离增大后衰减性符合预期,其中
pi-scale-2表现最佳, 即是长距离边线上,我们需要低维度进行内插,NTK-RoPE表现也不错(NTK-RoPE的操作就是在低维做内插) -
综合来看
NTK-RoPE即在高频中较好捕捉段距离特征,远距离中满足较好的衰减性 -
我们可以得出经典结论“短距离高频外推,长距离低频内插 ”, 这里的外推指对编码不做更多的改变,即可拓展长度
-
更进一步,高频在远距离上衰减将收敛到一定范围,此时能推到多远,就得看低频的衰减能力
4. 衰减性震荡
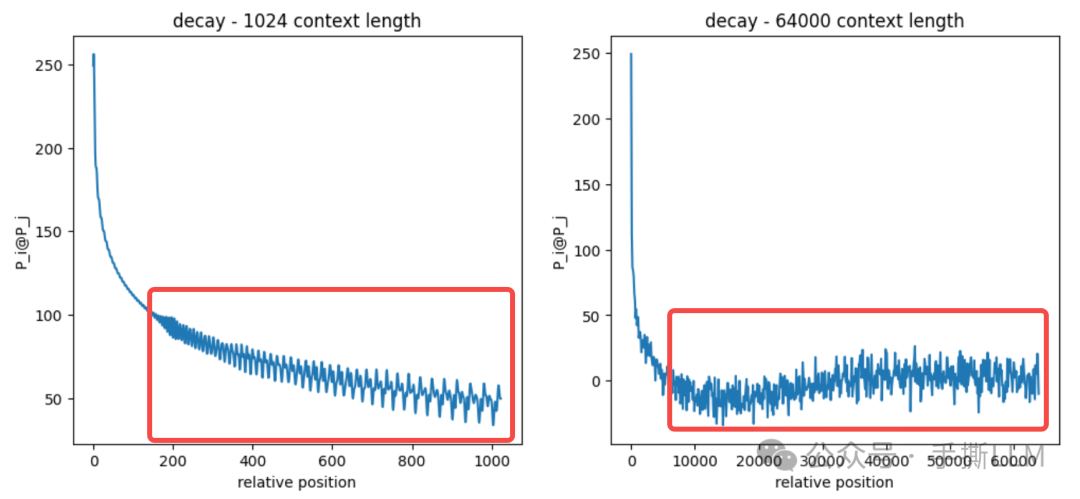
4.1 震荡现象
在长距离下,衰减性并非预期单调下降。该震荡将会放大建模误差,这也是其中一个长文本难训的原因
我们所观察到的衰减性震荡主要有两种
-
左:局部窗口内的震荡,本部分讲解
-
右:随距离收敛到一定波动范围
4.2 高频影响
一旦出现震荡影响,我们回到1.2中的例子,那我们对于以下句子建模就是失败的
给定token序列
我今天买彩票中了5,000,000元
如果出现衰减性震荡, 那么以下这句话相对位置距离分数为
我今天买彩票中了5,000,000元 # s(我,5)=0.0001 s(我,000)=0.0002 # 该形式建模形式与短距离是冲突的:按照以上分数,实际模型建模为 # 我今天买彩票中了000,5,000元
在短距离中, 由于衰减性显著,不存在错误衰减,能够合理建模
我中了5,000,000元 # s(我,5)=0.2 s(我,000)=0.1
我们在观察震荡产生前,可以通过减小位置编码维度更快的产生局部震荡现象。
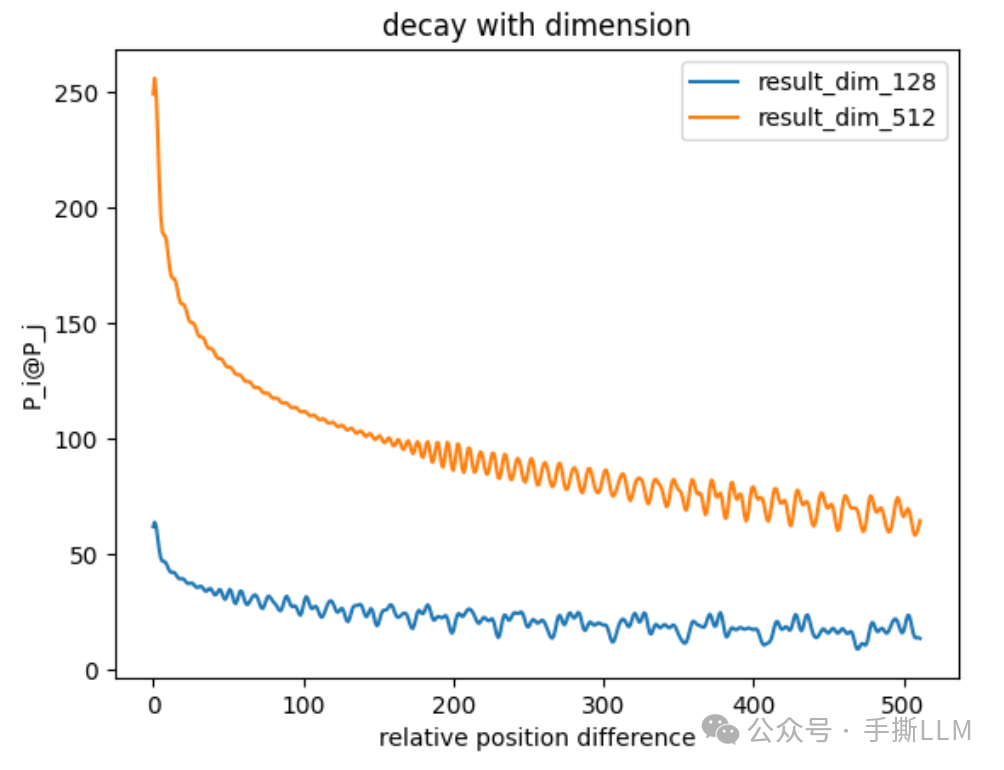
-
随着维度增加,衰减曲线里震荡变的平缓
-
实验可以发现随着位置增加,高频的碰撞概率将大幅增加,低频下变化平缓。
-
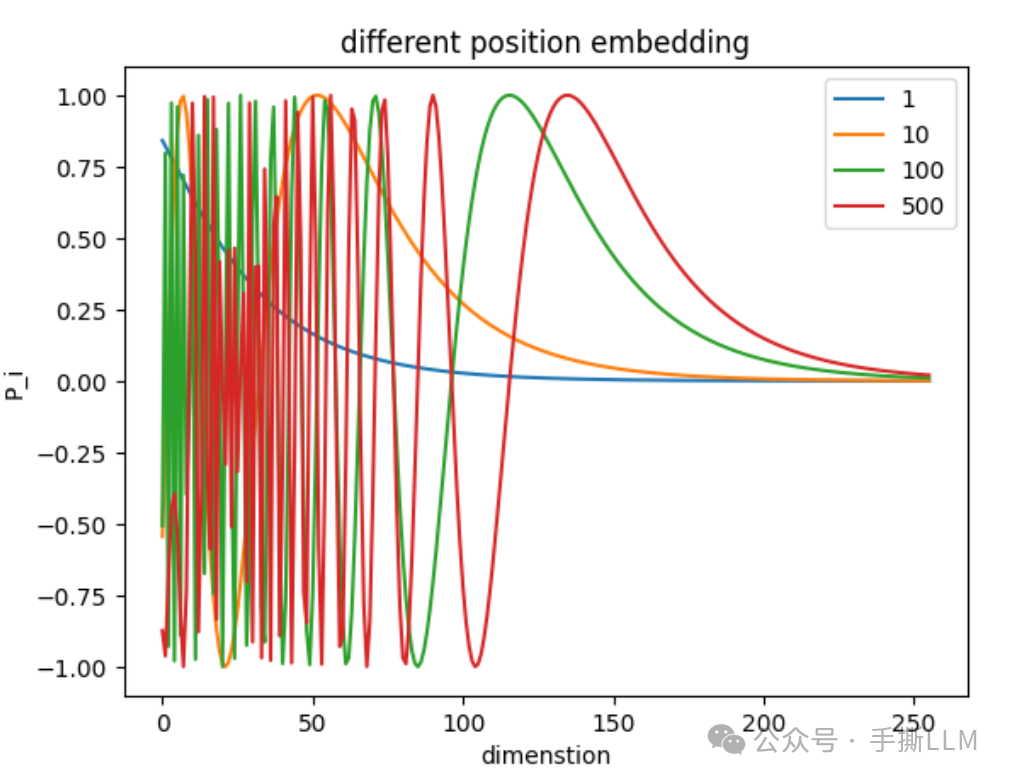
横坐标在200位置,第0-100位置和0-500位置的角度相差是单调的。
pe = PositionalEncoding(512, max_len).encoding result = pe[1,:] @ pe.transpose(1,0) result_512 = result.tolist() pe_a = pe[1,0::2].tolist() pe_b = pe[10,0::2].tolist() pe_c = pe[100,0::2].tolist() pe_d = pe[200,0::2].tolist() # x_d = x[0::2] x_d = range(len(pe_a)) print(len(pe_a)) print(pe.shape) print(len(x_d)) plt.plot(x_d, pe_a, label = '1' ) plt.plot(x_d, pe_b, label = '10') plt.plot(x_d, pe_c, label = '100' ) plt.plot(x_d, pe_d, label = '500')
4.3 缓解方案
针对以上分析,一个建议是拓展维度。
实验1:小的维度下,相对位置分数震荡明显,其中 PI 震荡更轻,内插能减轻震荡
实验2: 在 PE 增大维度后,可见震荡现象有明显减轻
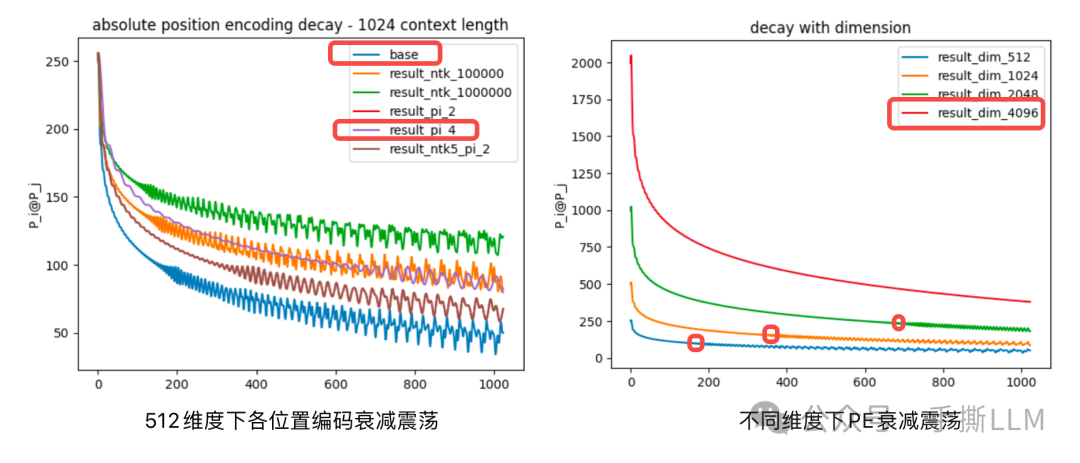
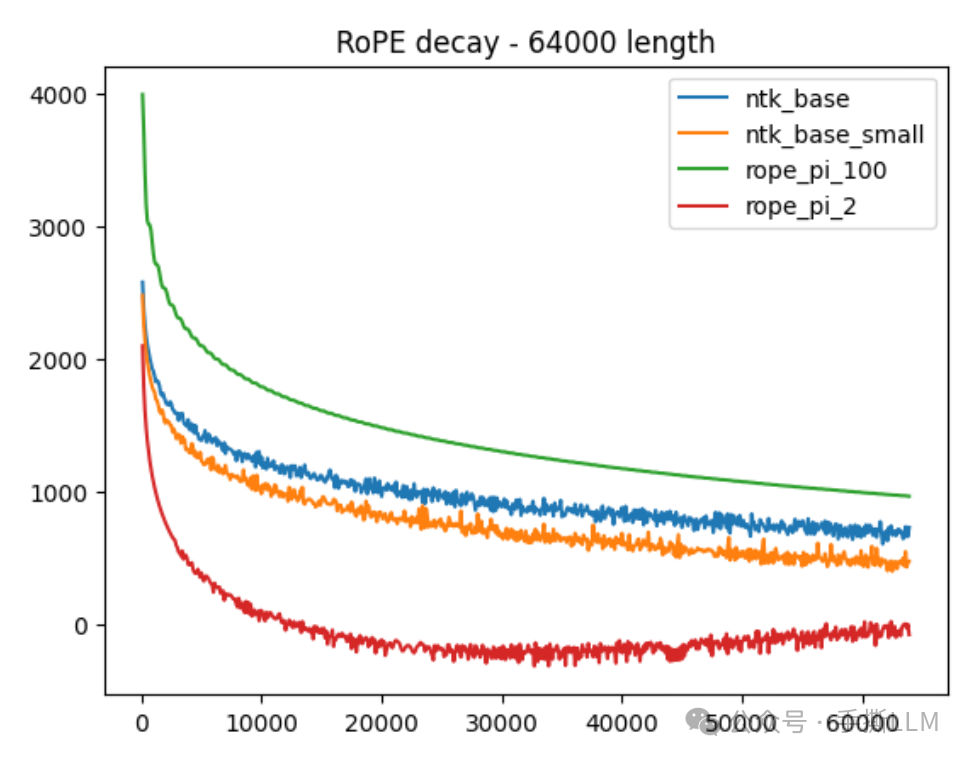
实验3: 在不改变维度下,我们使用不同scale{2,100}内插后,震荡现象明显减弱。那么这也进一步说明内插对长文本建模是至关重要的。
5. 其他
5.1 位置编码区别
5.1.1 绝对位置编码
以下可以理解为, 注意力计算中,除了红色项表达了相对信息,蓝色将各自的绝对信息嵌入到了注意力分数的计算中
5.1.2 旋转相对位置编码
而RoPE是纯相对位置编码:
对与两段文本来说
text1: 小冬瓜爱吃蜂蜜 text2:爱吃蜂蜜
-
在
RoPE中,”爱吃蜂蜜“ 四个词与前缀后缀文本无关, 旋转位置编码只在乎相对位置关系 -
在绝对位置编码中, 按照5.1.1中的蓝色项可以看出, text1与text2的 ”爱吃蜂蜜“ 所计算的注意力分数会有区别的。
5.1.3 ALIBI
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
以ALIBI为主的位置编码可以描述为以下形式:
其中为缩放因子, 为位置与 的相对线性位置分数,而该式子较RoPE来说,是维度无感的.
这里的 是标量, 而RoPE中 是向量,猜想ALIBI的位置感知学习无法分散到各个维度上,导致表达能力不如RoPE,
5.2 迈向超长文本
在搞清楚位置编码的衰减因素后,我们可以猜想我们需要的位置编码是怎么样的
-
按照NTK思想高频需要保留,而我们要扩展长文本,我们可以在高低频分别做不同的优化,那么可以阅读
NTK-Part RoPETransformer升级之路:11、将β进制位置进行到底
-
更进一步可以阅读
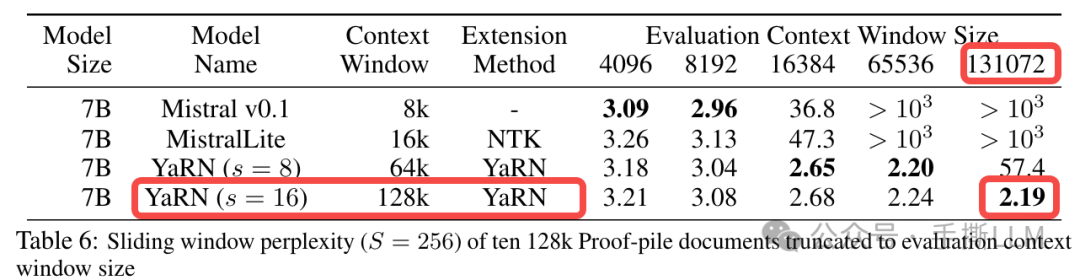
YaRN方案, 号称可以推到200k,图示推到128kYaRN: Efficient Context Window Extension of Large Language Models
5.3 长文本训练策略
-
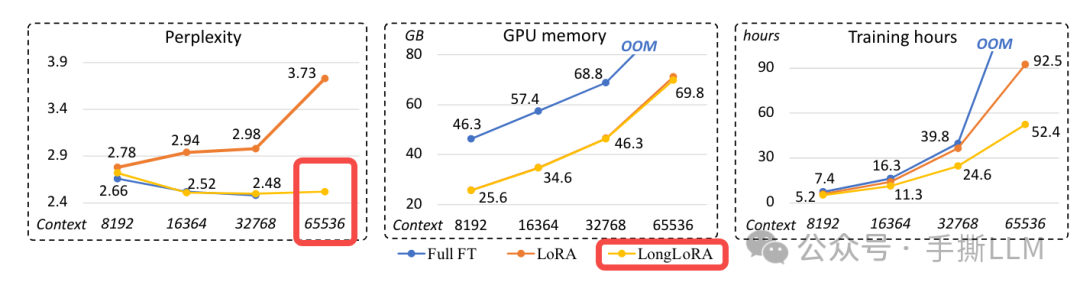
在Llama-3所释放的文本长度为8192,在社区已经有足够多的讨论如何拓展长文本能力。以下为ICML 24通过LongLoRA微调模型提升长文本能力
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
-
该博客Transformer升级之路:18、RoPE的底数设计原则介绍一个更加general的扩展长度的方式,先短后长
我们知道,在RoPE中频率的计算公式为𝜃𝑖=𝑏−2𝑖/𝑑,底数b𝑏默认值为10000。目前Long Context的主流做法之一是,先在𝑏=10000上用短文本预训练,然后调大𝑏并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的𝑏再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大𝑏完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大𝑏了?
6. 总结
-
本文从语言建模假设出发,阐述距离衰减性对序列关系的影响,如不满足衰减性,将对模型造成破坏性影响。
-
并从衰减性视角统一观察不同位置编码的衰减表现,实验直观表明
NTK-RoPE下增大base即可扩展到长文本建模能力 -
本文切分高低维来计算衰减性,分析出“短距离高频外推,长距离低频内插”,在
RoPE范式下的位置编码均可按照该套路优化设计。
REFERENCE
Attention Is All You Need
RoFormer: Enhanced Transformer with Rotary Position Embedding
Extending Context Window of Large Language Models via Positional Interpolation
NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation
Transformer升级之路:10、RoPE是一种β进制编码
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
YaRN: Efficient Context Window Extension of Large Language Models
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Base of RoPE Bounds Context Length
Transformer升级之路:18、RoPE的底数设计原则
Transformer升级之路:11、将β进制位置进行到底
图解RoPE旋转位置编码及其特性
Word2Vec Tutorial - The Skip-Gram Model
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









