







《 游戏引擎架构》笔记
文章目录
C++11
auto
自动类型推导。
// c++03
float f = 3.141592f;
_m128 acc =_mm_setzero_ps();
std::map<std::string, std::int32_t>::const_iterator it = myMap.begin();
// c++11
auto f = 3.141592f;
auto acc = _mm_setzero_ps();
auto it = myMap.begin();
nullptr
空指针。它是类型std::nullptr_t的实例。
foreach
for (const auto& pair : myMap)
{
print("%s\n",pair.first.c_str());
// 注:cout比print满的多。如果注意性能的话,建议使用print。
}
override和final
override指定符表示该函数会覆盖一个积累现有的虚函数,而final指定符表示该虚函数不能再被子类覆盖。
强类型的enum
指明枚举类型。
enum class Color : std::int8_t {Red, Green, Blue, White, Black };
Color c= Color::Red;
智能指针
ps: 这里书上讲的不够仔细,没理解。添加新的参考资料:详解C++11智能指针 - WindSun - 博客园 https://www.cnblogs.com/WindSun/p/11444429.html
C++里面的四个智能指针: auto_ptr, unique_ptr,shared_ptr, weak_ptr 其中后三个是C++11支持,并且第一个已经被C++11弃用。
智能指针主要用于管理在堆上分配的内存,它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。C++ 11中最常用的智能指针类型为shared_ptr,它采用引用计数的方法,记录当前内存资源被多少个智能指针引用。该引用计数的内存在堆上分配。当新增一个时引用计数加1,当过期时引用计数减一。只有引用计数为0时,智能指针才会自动释放引用的内存资源。对shared_ptr进行初始化时不能将一个普通指针直接赋值给智能指针,因为一个是指针,一个是类。可以通过make_shared函数或者通过构造函数传入普通指针。并可以通过get函数获得普通指针。
- unique_ptr:
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。 - shared_ptr:
shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。 - weak_ptr:
share_ptr虽然已经很好用了,但是有一点share_ptr智能指针还是有内存泄露的情况,当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏。
lambda
auto pos = std::find_if(std::begin(v),std::end(v),[](int){return (n % 2 == 1); });
移动语义与右值引用
c++11之前,避免不必要的拷贝:
void MultiplyAllValues(std::vector<float>& output,const std::vectro<float>& input,float multiplier)
{
output.resize(0);
output.reserver(input.size());
// Copy input to output.
}
c++11以后。。。没搞懂
左值:在计算机寄存器或内存中的实际存储位置。
右值:临时数据对象。
IEEE
有限精度和机器的epsilon的概念对游戏软件有实质影响。游戏持续运行,加上1/30秒以后,游戏的绝对时间维持不变为12.9日。
SIMD类型
矢量处理器提供一种并行处理方式,名为单指令多数据。单个SIMD指令可以并行地对多个数据进行运算。
字节序
小端处理器:将多个字节值的最低有效字节存储于较低的内存位置。
大端处理器:将多个字节值的最高有效字节储存于较低的内存位置。
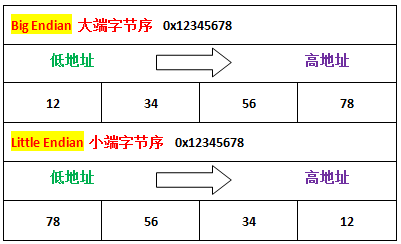
- Windos(x86,x64)和Linux(x86,x64)都是Little Endian操作系统
- 在ARM上,我见到的都是用Little Endian方式存储数据。
- C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的。
- JAVA编写的程序则唯一采用Big Endian方式来存储数据。
- 所有网络协议也都是采用Big Endian的方式来传输数据的。所以有时我们也会把Big Endian方式称之为网络字节序。
参考:https://blog.csdn.net/humanking7/article/details/51155778
为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
参考:https://www.ruanyifeng.com/blog/2016/11/byte-order.html
字节序转换
inline U16 swapU16(U16 value)
{
return ((value & 0x00FF) << 8 ) | ((value & 0xFF00) >> 8);
}
inline U32 swapU32(U32 value)
{
return ((value & 0x000000FF) << 24)
| ((value & 0x0000FF00) << 8)
| ((value & 0x00FF0000) >> 8)
| ((value & 0xFF000000) >> 24);
}
// 浮点字节序转换,简便的方法就是使用union
union U32F32
{
U32 m_asU32;
F32 m_asF32;
};
inline F32 swapF32(F32 value)
{
U32F32 u;
u.m_asF32 = value;
// 使用整数方式来转换字节序
u.m_asU32 = swapU32(u.m_asU32);
return u.m_asF32;
}
链接
若内联函数要提供多于一个翻译文件使用, 则该内联函数必须置于头文件。
static关键字可以把定义改为内部链接。
// foo.cpp
// 外部链接
U32 gExternalVariable;
// 内部链接
static U32 gInternalVariable;
C/C++内存布局
- 代码段:可自行机器码。
- 数据段:初始化的全局以及静态变量。
- BSS端:未初始化全局变量和静态变量。
- 只读数据段:又称为rodata端,包含程序中定义的只读(常量全局变量。注意:编译器通常吧整数常量视为明示常量,并且直接把明示常量插入机器码中(代码段的存储空间)。
全局变量按照是否被初始化来决定储存在数据段还是BSS段。(被初始化的储存在数据段)函数静态变量和文件域静态变量一样。















 1778
1778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









