






KNN分类预测
可以选取80%的数据训练,20%测试(可自定义百分比)
Matlab代码备注清晰,易于使用
ID:8430704839576254
Matlab编程
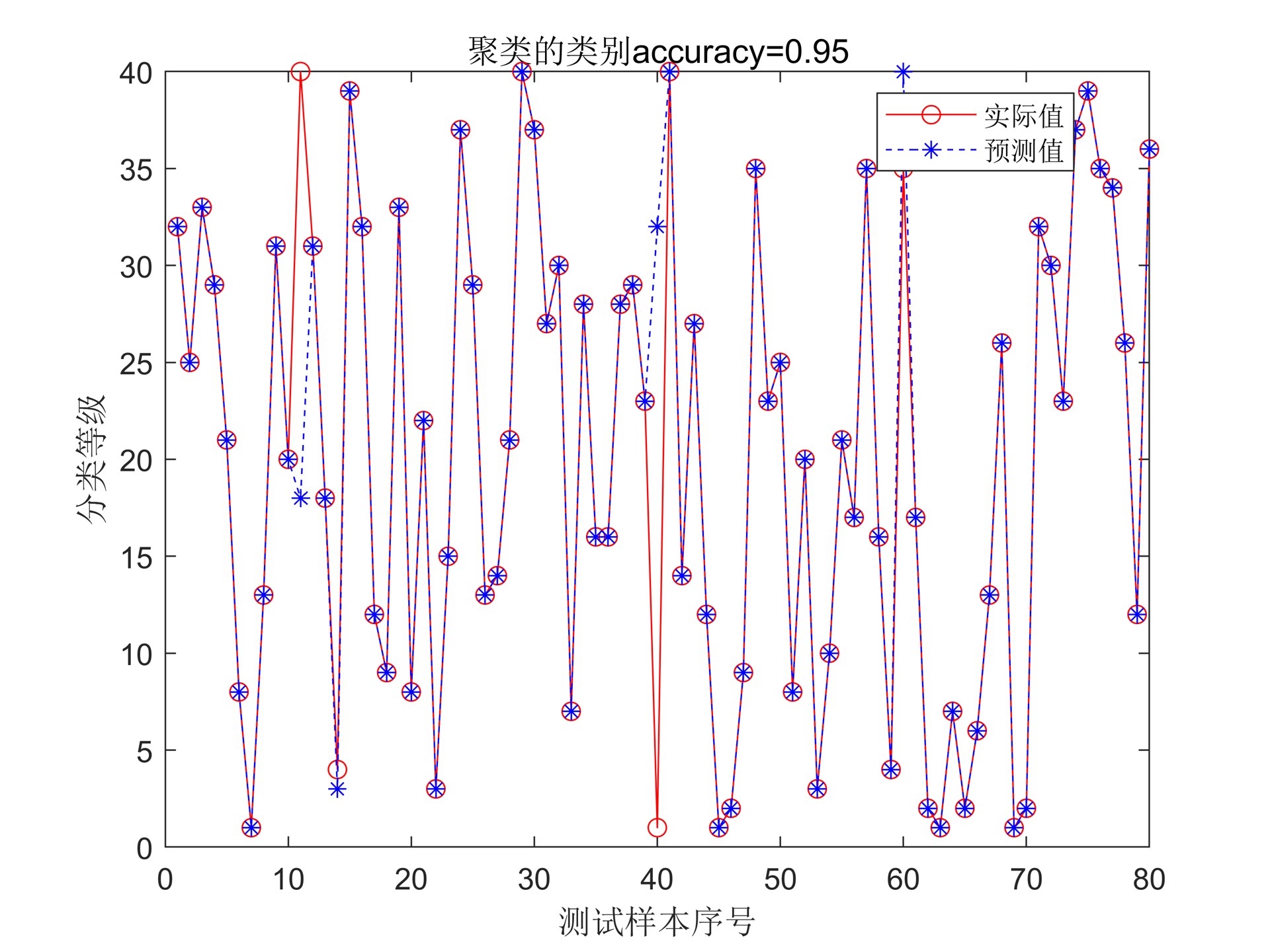
KNN(K-Nearest Neighbors)分类预测是一种常用的机器学习算法,可用于分析和预测数据样本所属的类别。在这个算法中,我们可以通过选取适当的训练数据集,并利用KNN算法来进行分类预测。
KNN分类预测的第一步是将数据集划分为训练集和测试集。在这里,我们可以选择将80%的数据作为训练集,剩下的20%作为测试集。这个比例可以根据需求自定义,以满足不同的实验和分析要求。
在使用KNN算法进行分类预测之前,我们需要准备好合适的数据,并对其进行相应的预处理。这包括数据的清洗、标准化和特征选取等。数据的清洗可以帮助我们去除异常值和噪声,保证数据的质量。标准化可以将数据转化为统一的尺度,避免不同特征之间的量纲问题。特征选取则是选择最相关的特征,从而提高分类预测的准确性和效率。
接下来,我们可以使用Matlab编写KNN分类预测的代码。在编写代码时,我们需要确保代码的清晰和易于使用。为了达到这个目的,我们可以添加相应的注释和文档说明,让用户能够理解和使用代码。注释可以解释每一步的操作和参数的含义,文档说明可以提供使用方法和示例。
在进行KNN分类预测时,我们需要选择合适的K值。K值代表着所选取的最近邻居的个数。在选择K值时,我们可以通过交叉验证的方法来进行选择。通过比较不同K值下的分类准确率,我们可以选择最优的K值。同时,我们还可以使用不同的距离度量方法,如欧式距离、曼哈顿距离等,来比较其性能差异。
KNN分类预测的结果可以通过各种评估指标来进行评估。这些评估指标可以包括准确率、召回率、F1-score等。通过这些指标,我们可以了解分类预测的准确性和可靠性。同时,我们还可以使用混淆矩阵来可视化分类结果,进一步分析分类的效果。
总结来说,KNN分类预测是一种简单而有效的机器学习算法。通过选取合适的训练数据集和测试数据集,编写清晰易用的Matlab代码,并进行适当的数据预处理和特征选取,我们可以实现准确的分类预测。同时,通过选择合适的K值和距离度量方法,并使用评估指标和混淆矩阵进行分析,我们可以进一步了解算法的性能和效果。在实际应用中,KNN分类预测可以用于各种领域的数据分析和预测任务,如医疗诊断、金融风险评估等。因此,掌握KNN算法的使用方法和技巧,对于数据科学家和工程师来说具有重要意义。
【相关代码,程序地址】:http://fansik.cn/704839576254.html
















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









