






Copula二维最全代码,包括边缘分布的拟合寻优,联合分布的拟合寻优及蒙特卡洛数据模拟代码
案例包括4部分:
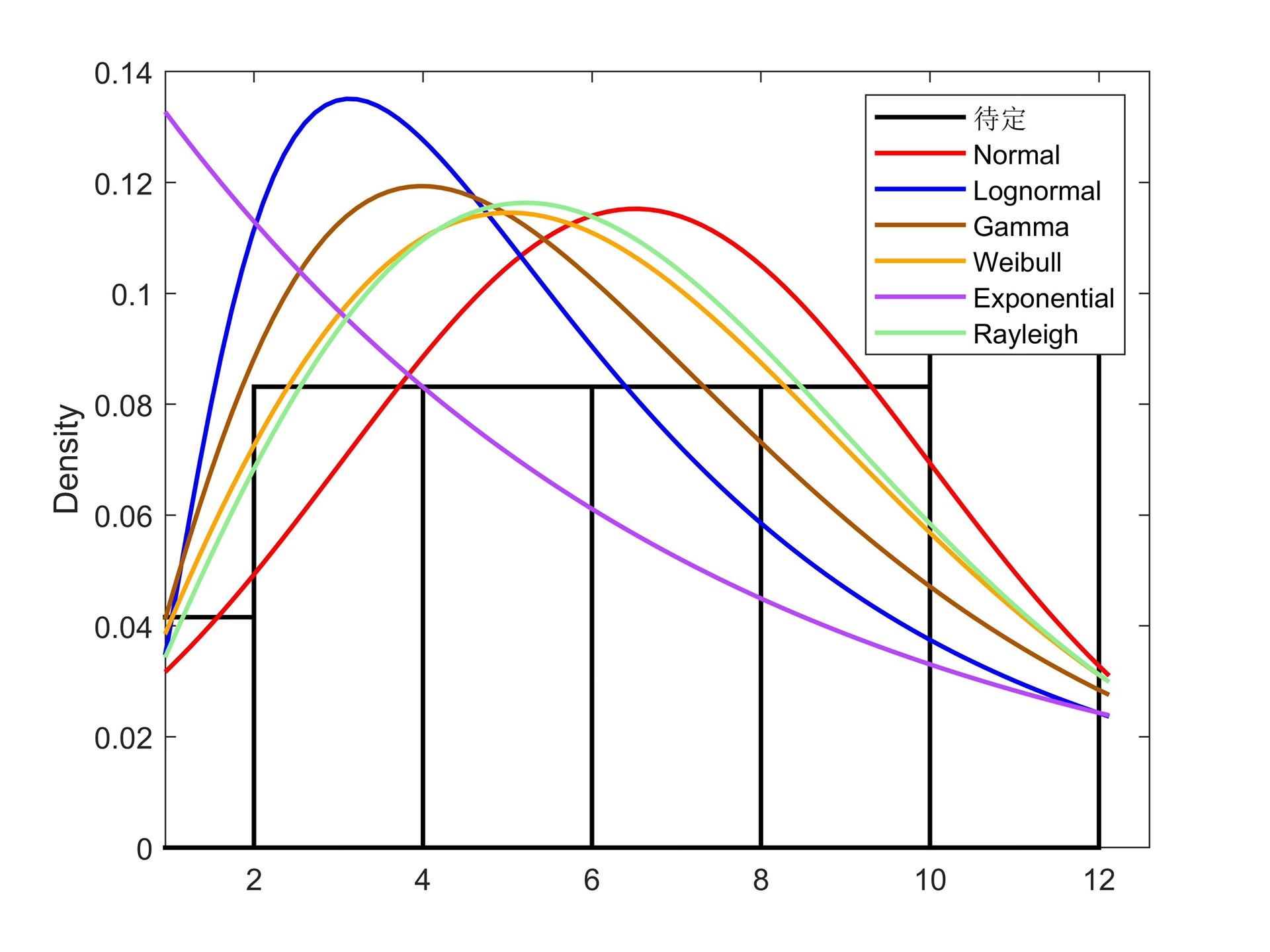
1-变量x1的边缘部分拟合,提供了正态分布、对数正态分布、伽马分布、威布尔分布、指数分布、瑞利分布等6种常见边缘分布(仅支持正数),6种分布的ks检验及寻优确定x1的最优边缘分布
2-变量x2的边缘部分拟合,其他同1
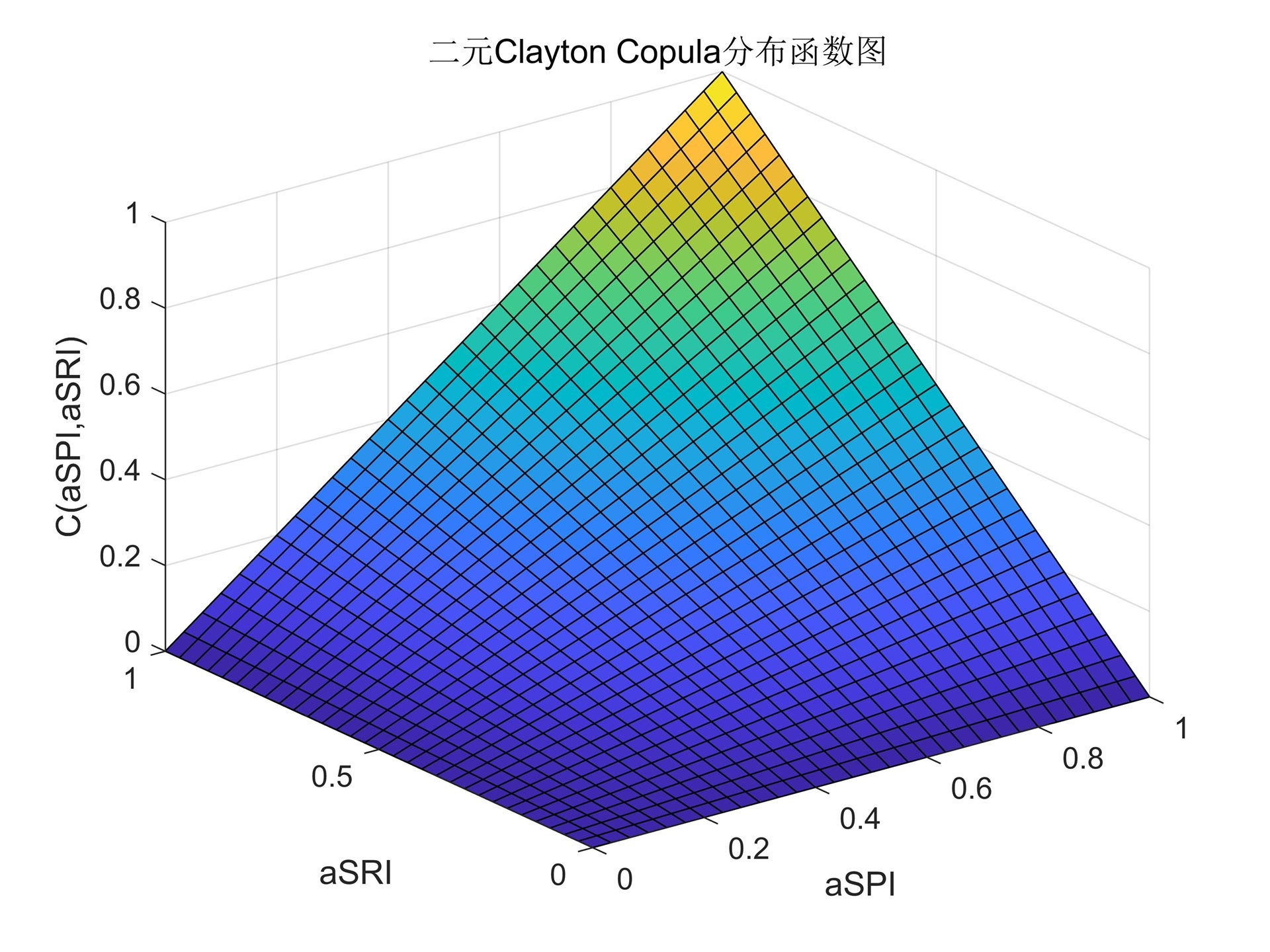
3-copula的拟合寻优,具体包括Gaussian、t、Frank、Gumbel、Clayton等5种常用copula函数,计算内容包括偏度、峰度,copula参数的拟合,5种copula的上下尾部相关系数,5种copula的AIC和BIC值,Kendall秩相关系数和Spearman秩相关系数,Copula的密度函数和分布函数图,根据平方欧氏距离求取最优copula
4-根据前3步得到的结果,进行蒙特卡洛模拟及等概率转换得到实际尺度下的数据结果
matlab代码,笔者根据大量顾客的各种需求总结而成,备注非常详细,根据自己需要修改案例数据即可
温馨提示:此单为最全2维copula代码,代码可以正常运行
YID:92200704867972966
Matlab编程

Copula二维最全代码是一款功能强大的工具,能够提供包括边缘分布的拟合寻优、联合分布的拟合寻优以及蒙特卡洛数据模拟等功能。该代码主要包括四个部分,分别是变量x1的边缘部分拟合、变量x2的边缘部分拟合、Copula的拟合寻优以及蒙特卡洛模拟及等概率转换。
首先,在变量x1的边缘部分拟合方面,代码提供了正态分布、对数正态分布、伽马分布、威布尔分布、指数分布和瑞利分布等六种常见的边缘分布,这些分布仅支持正数。此外,还提供了这六种分布的ks检验和寻优功能,可以确定x1的最优边缘分布。通过对数据进行拟合和优化,能够得到更准确的分布模型。
其次,在变量x2的边缘部分拟合方面,代码与变量x1的处理方式相同,同样提供了六种常见的边缘分布的拟合和优化功能,以确定x2的最优边缘分布。通过对两个变量的边缘分布的拟合,能够更好地了解数据的特征和规律。
第三部分是Copula的拟合寻优,代码提供了Gaussian、t、Frank、Gumbel和Clayton等五种常用的Copula函数。在拟合过程中,可以计算偏度、峰度、Copula参数的拟合等指标,并提供了五种Copula的上下尾部相关系数、AIC和BIC值,以及Kendall秩相关系数和Spearman秩相关系数等数据。此外,还可以绘制Copula的密度函数和分布函数图,通过平方欧氏距离求取最优Copula。
在第四部分,根据前面三个部分得到的结果,进行蒙特卡洛模拟及等概率转换,从而得到实际尺度下的数据结果。通过蒙特卡洛模拟,可以模拟出大量符合特定分布和相关性的数据,为进一步的数据分析提供了有力的支持。
总结来说,Copula二维最全代码是一款功能强大、操作简便的工具,能够帮助用户完成复杂的数据分析任务。通过边缘分布的拟合寻优、Copula的拟合寻优和蒙特卡洛模拟,可以得到准确、可靠的数据结果,为用户提供了更多的分析和决策依据。该代码基于Matlab开发,针对不同用户的需求提供了详细的备注和修改案例数据的功能,非常灵活和实用。
最后,温馨提示:该代码为最全的二维Copula代码,能够正常运行。无论是在学术研究还是实际应用中,都具有很高的实用价值,希望能够为广大用户提供便利和帮助。
【相关代码,程序地址】:http://fansik.cn/704867972966.html


















 2112
2112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









