






作为一个热爱编程和数据的程序员,数据分析这块内容也经常围绕在我的工作周围。今天就为大家分享3款,Python技术下数据分析经常会使用到的三个库。(非Pandas|Numpy)
一、聊聊Parquet文件格式(pyarrow)
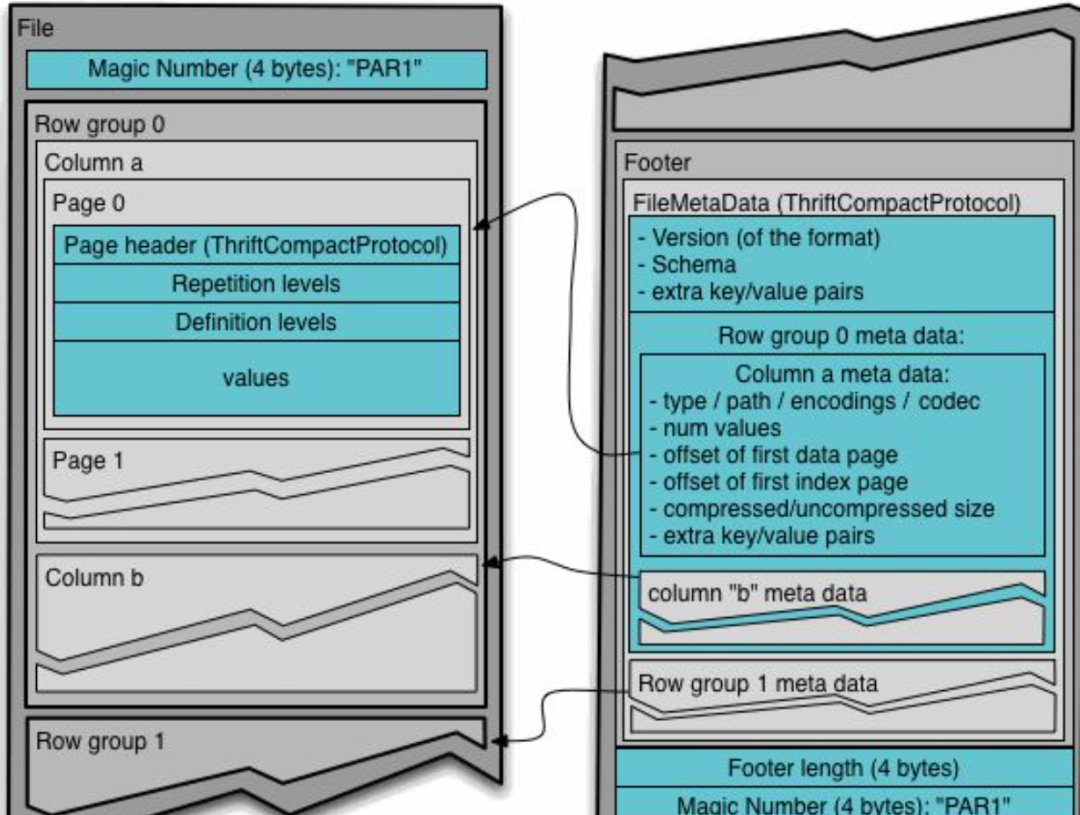
在此之前为大家介绍普及下,除了传统数据存储格式(媒介)外,当下被公认的数据存储格式Parquet。Parquet文件格式优势
-
数据压缩:通过应用各种编码和压缩算法,Parquet 文件可减少内存消耗,减少存储数据的体积。
-
列式存储:快速数据读取操作在数据分析工作负载中至关重要,列式存储是快速读取的关键要求。
-
与语言无关:开发人员可以使用不同的编程语言来操作 Parquet 文件中的数据。
-
开源格式:这意味着您不会被特定供应商锁定
-
支持复杂数据类型
这个高效的列式存储格式简直是大数据时代的宝藏。它让我们在处理海量数据时,既能节省存储空间,又能快速读取数据。
打个比喻来说,Parquet就像一个精致的收纳箱,把杂乱的数据整齐地归类好,方便我们随时取用。
还记得第一次接触Parquet的时候,那种兴奋感就像是打开了一个神秘的宝箱。每一列数据都整齐划一,读取速度更是让人惊叹。有了它,处理大规模数据再也不是难题。
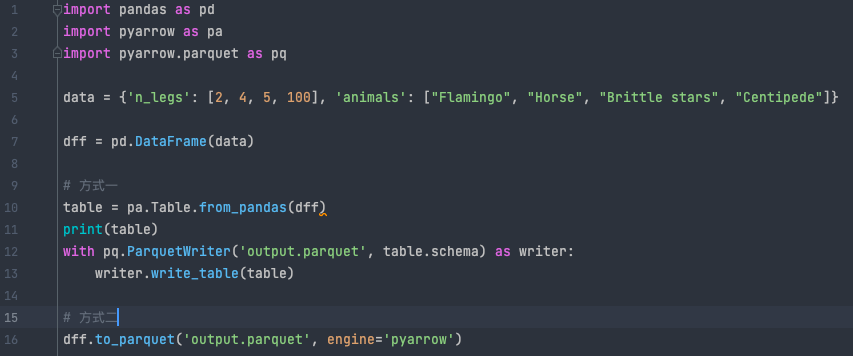
如果想要通过Python保存数据为parquet格式,我们需要额外安装一个Python库:pyarrow,除此之外还要结合Pandas使用,有两种方式进行保存。
以前使用pandas的时候,只关注了csv、xls等格式,现在再回头看其实Pandas一直支持parquet格式。读取parquet文件同样使用pandas即可。
二、NetworkX:用Python探索图的奥秘
NetworkX,一个用于创建和操作图结构的强大工具。你可能会问,图结构到底有什么用?简单来说,图结构能帮助我们理解数据之间的关系。比如在社交网络中,每个用户就是一个节点,用户之间的互动就是边。有了NetworkX,我们可以轻松地构建和分析这些关系网。
说实话,刚开始用NetworkX的时候,我还是有点小忐忑的。毕竟,图结构听起来有点高深。但当我看到一行行代码变成一个个漂亮的网络图时,那种成就感简直难以言喻。
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
# 读取Parquet文件
df = pd.read_parquet('output.parquet')
# 创建空图
G = nx.Graph()
# 添加节点和边
for index, row in df.iterrows():
G.add_edge(row['n_legs'], row['animals'])# 添加边
nx.draw(G, with_labels=True) # 绘制图,并显示节点标签
plt.show() # 显示图形
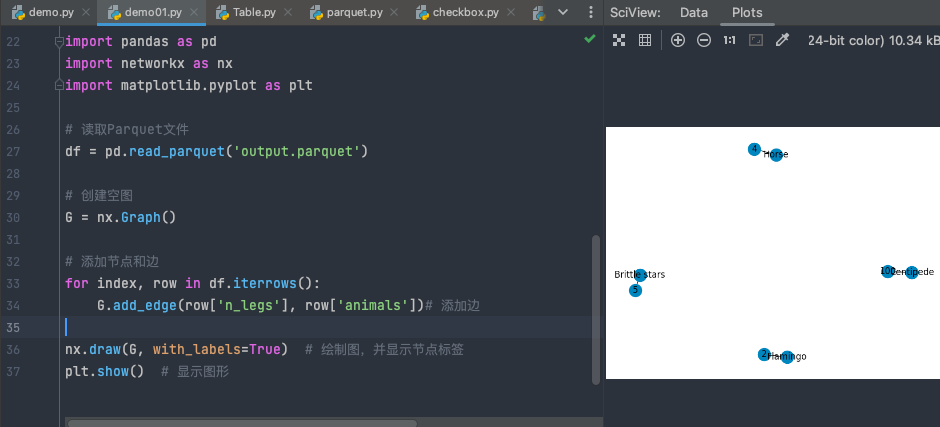
看到这段代码,你会发现,用NetworkX构建图结构其实没那么难。我们把Parquet数据读入Pandas DataFrame,然后逐行添加节点和边,几行代码就搞定了一个基本的社交网络图。
三、Plotly:3D可视化的魔法师
我们做数据分析,有时候的目标可能不仅仅是2D图,而是更炫酷的3D图谱。这就需要Plotly来助阵了。Plotly是一个强大的绘图库,能创建交互式、动态的图表。结合NetworkX,我们可以将2D图轻松转化为3D图形。
import pandas as pd
import networkx as nx
import plotly.graph_objects as go
# 读取Parquet文件
df = pd.DataFrame({
'user1': [1, 1, 2, 3, 4],
'user2': [2, 3, 3, 4, 5]
})
# 假设我们已经将DataFrame保存为Parquet格式
# df.to_parquet('social_network.parquet')
# 从Parquet文件中读取数据
# df = pd.read_parquet('social_network.parquet')
# 创建空图
G = nx.Graph()
# 添加节点和边
for index, row in df.iterrows():
G.add_edge(row['user1'], row['user2'])
# 获取节点和边的坐标
pos = nx.spring_layout(G, dim=3)
x_nodes = [pos[node][0] for node in G.nodes]
y_nodes = [pos[node][1] for node in G.nodes]
z_nodes = [pos[node][2] for node in G.nodes]
# 创建3D节点图
node_trace = go.Scatter3d(
x=x_nodes, y=y_nodes, z=z_nodes,
mode='markers',
marker=dict(size=10, color='blue', opacity=0.8)
)
# 创建3D边图
edge_trace = []
for edge in G.edges:
x0, y0, z0 = pos[edge[0]]
x1, y1, z1 = pos[edge[1]]
edge_trace.append(
go.Scatter3d(
x=[x0, x1], y=[y0, y1], z=[z0, z1],
mode='lines',
line=dict(width=2, color='grey'),
opacity=0.8
)
)
# 合并图形
fig = go.Figure(data=[node_trace] + edge_trace)
fig.update_layout(scene=dict(
xaxis_title='X Axis',
yaxis_title='Y Axis',
zaxis_title='Z Axis'
))
fig.show()
这段代码将我们的社交网络数据从2D平面带入了3D空间。通过旋转、缩放等操作,我们可以从不同角度观察数据之间的关系,感觉就像是戴上了VR眼镜,进入了一个数据的奇幻世界。代码运行后,Plotly会自动在本地开启一个端口为52586的网页服务,自动打开网页如下:
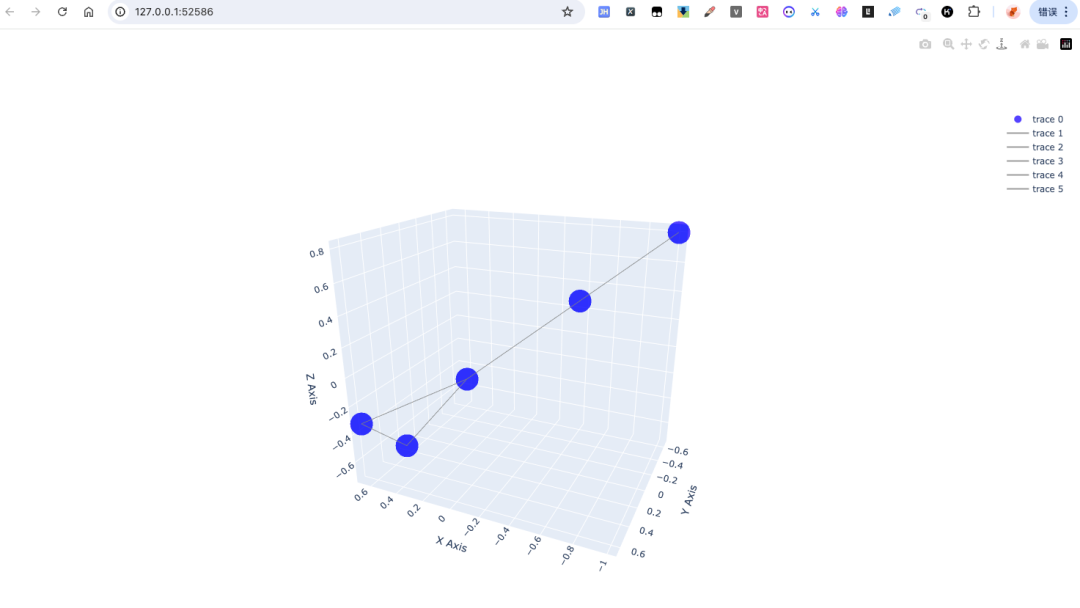
从Parquet数据到3D知识图谱的构建过程中,如果数据量过大时,直接加载到内存中可能会导致性能问题。这时候,我们可以考虑分批次加载数据,或者使用分布式计算框架如Dask来处理。
复杂的图结构在3D空间中会显得非常混乱,节点和边的密集程度可能会影响可视化效果。可以尝试不同的图布局算法,如层次布局、力导向布局等,以优化图的展示效果。
此外,3D可视化虽然炫酷,但用户在浏览图谱时的交互体验也是关键。通过优化Plotly的交互功能,如添加滑块、按钮等,可以提升用户体验。
作为一名程序员,我深知数据的价值不仅在于存储和处理,更在于如何有效地呈现和应用。希望这篇文章能够激发你对数据可视化的兴趣!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











