






并行计算提高R语言速度
今天与大家分享的是R语言中的并行计算的内容,将探讨如何使用parallel和foreach包在R中进行并行计算,以及在不同情况下提高计算效率的方法。
目标:让计算等待时间缩短!
1. 什么是并行计算?
并行计算是计算机科学中的一个概念,它涉及到同时执行多个计算任务以加速整体的处理速度,这是通过在多个处理器或多个计算节点上同时执行代码来实现的。

2. 为什么需要并行计算?
随着数据规模的增长,我们需要更快地处理数据。单线程的程序只能在一个CPU核心上运行,而并行计算可以同时利用多个核心,从而大大提高计算速度。
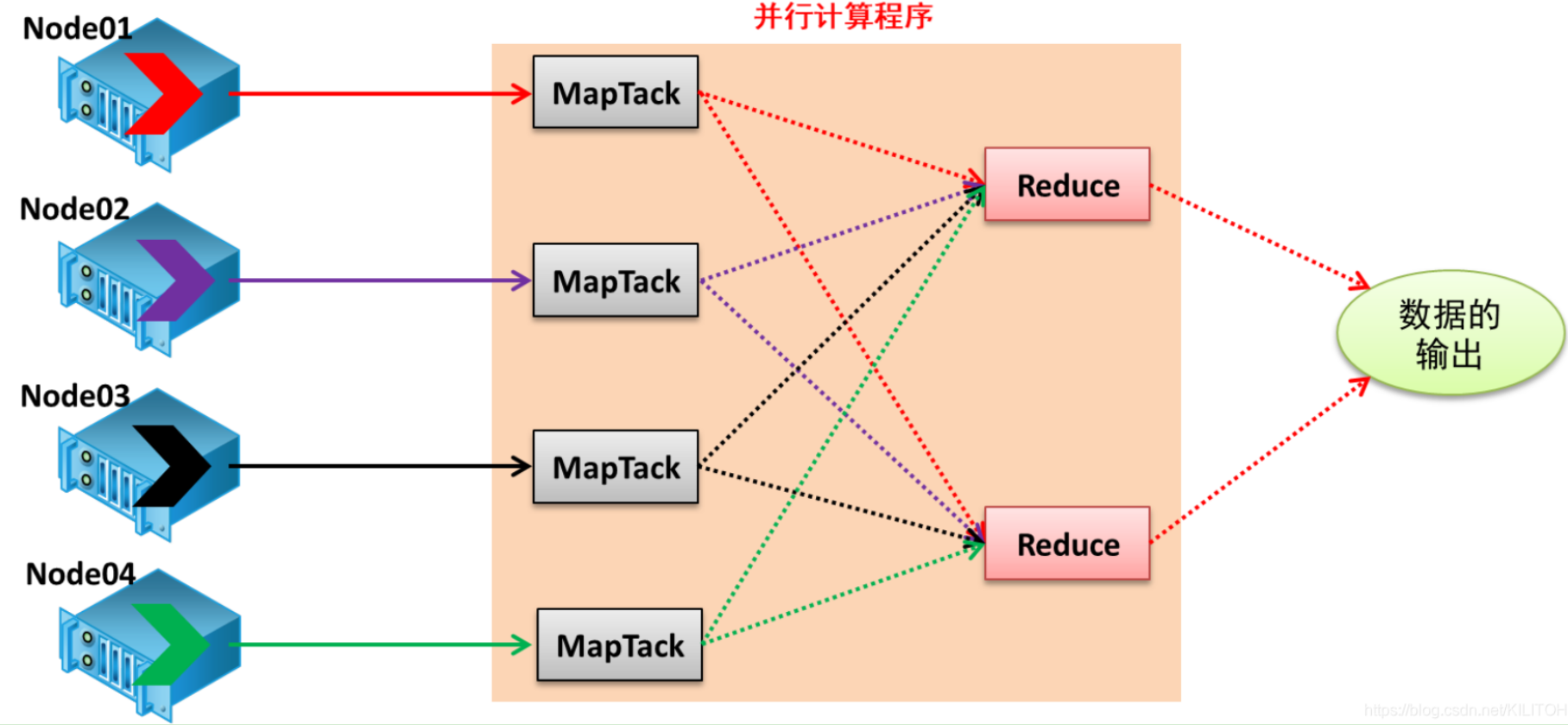
3. CPU多线程基础
多线程是一种允许单个程序或应用执行多个任务(线程)的技术。每个线程都运行在其自己的CPU核心上,这使得多线程程序可以更高效地使用多核CPU。
4. R语言中的并行计算
R语言提供了多种并行计算的方法,其中最常用的是parallel和foreach包。

4.1 parallel包
使用parallel包的mclapply函数,可以轻松地实现并行计算。
library(parallel)
定义一个简单的函数来模拟计算任务
f <- function(x) {
Sys.sleep(1) # 模拟耗时1秒的任务
return(x^2)
}
使用mclapply函数并行处理数据
result <- mclapply(1:4, f, mc.cores = 2)
print(result)
4.2 foreach包

foreach包提供了一个更加灵活的并行框架。与传统的for循环相比,它的语法更加简洁。
library(foreach)
library(doParallel)
注册并行后端
cl <- makeCluster(2)
registerDoParallel(cl)
使用foreach函数并行处理数据
result <- foreach(i=1:4) %dopar% {
Sys.sleep(1) # 模拟耗时1秒的任务
return(i^2)
}
print(result)
停止并行后端
stopCluster(cl)
5. 性能比较
为了对比普通for循环、mclapply和foreach的性能,我们将使用上面定义的函数f模拟计算任务。
-
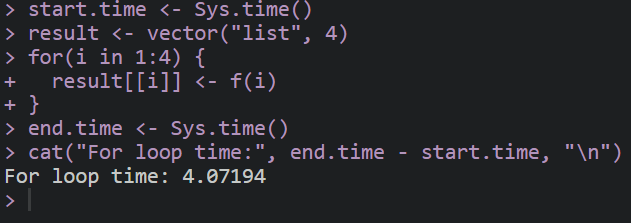
普通for循环
start.time <- Sys.time()
result <- vector("list", 4)
for(i in 1:4) {
result[[i]] <- f(i)
}
end.time <- Sys.time()
cat("For loop time:", end.time - start.time, "\n")
-
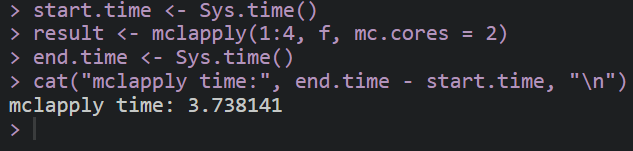
使用mclapply
start.time <- Sys.time()
result <- mclapply(1:4, f, mc.cores = 2)
end.time <- Sys.time()
cat("mclapply time:", end.time - start.time, "\n")
-
使用foreach
cl <- makeCluster(2)
registerDoParallel(cl)
start.time <- Sys.time()
result <- foreach(i=1:4) %dopar% f(i)
end.time <- Sys.time()
cat("foreach time:", end.time - start.time, "\n")
stopCluster(cl)
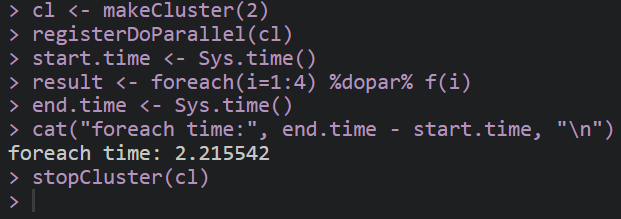
从上述代码的输出中,我们可以看到mclapply和foreach的执行时间都明显短于传统的for循环。(此处演示设置的线程数是2,实际上一般生信计算服务器可以达到一百多个线程,计算速度还可以明显提高)
如何使用并行计算模式?
在R中尽量避免使用for循环,在R中使用for循环速度很慢,在写代码的时候,应该尽可能的避免使用for循环。
查看电脑的可用线程数量
detectCores(logical = F)#查看电脑的物理核数
install.packages("future")
library(future)
availableCores()#查看电脑可用的线程数
foreach初级用法
使用foreach()+%do%代替for循环,计算速度和for循环差不多。但函数foreach返回了一个列表(list)。使用foreach的优势在于%do%后的花括号{}之间可以像for循环那样写多条语句。
x1 <- list()
foreach(i = 1:30000) %do% {
x1[[i]] <- mean(rnorm(1e5))
}
# 上述代码等同于以下for结构
for (i in 1:30000){
x1[i] <- mean(rnorm(1e5))
}
foreach高级用法
使用foreach进行并行计算,需要将上面的%do%替换为%dopar%来启动并行计算,在使用并行计算之前,首先需要加载doParallel包,创建一个集群并注册。
library(foreach)
library(doParallel)
# 创建一个集群并注册
cl <- makeCluster(128) # 128是设置的线程数
registerDoParallel(cl)
# 启动并行计算
x2 <- foreach(i = 1:3e4, .combine = c) %dopar% {
mean(rnorm(1e5))
}
# 在计算结束后别忘记关闭集群
stopImplicitCluster()
stopCluster(cl)
特别注意:foreach默认的返回值数据类型为list,可以使用".combine"参数来指定输出数据的类型为向量。
foreach函数中也可以使用rbind或者cbind等函数以矩阵形式输出结果。
下面是一个原始的for循环代码,对一个矩阵进行循环计算,运行耗时大约6分钟。
x <- matrix(0,nrow=3e4,ncol=6)
for (i in 1:30000) {
x[i,] <- summary(rnorm(1e5))
}
对其进行重构优化,采用dopar的方式并行计算,将返回的结果按行合并(rbind),计算实际耗时1分钟。
# 创建一个集群并注册
cl <- makeCluster(36)
registerDoParallel(cl)
# 启动并行计算
x <- foreach(i = 1:3e4, .combine = rbind) %dopar% {
summary(rnorm(1e5))
}
# 结束任务
stopImplicitCluster()
stopCluster(cl)
foreach函数使用技巧
cl <- makeCluster(20)
registerDoParallel(cl)
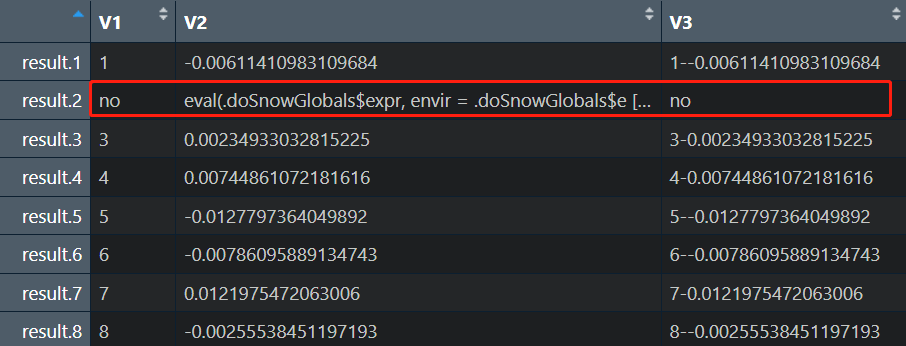
out <- foreach(i = 1:100,
.combine = rbind,
.packages = "tidyverse",
.errorhandling = "pass") %dopar% {
a <- i
b <- mean(rnorm(10000))
c <- str_c(a,"-",b)
d <- c(a,b,c)
if (i == 2){
stop("no")
}
return(d)
}
stopCluster(cl)
.package
写在%dopar%后的代码经常会用到第三方R包,这些包必须在.package中指定,也就是说一旦函数主体内出现了引用其他包的函数,就要在此指定。比如上面的tidyverse包中“str_c”函数。
.errorhandling
处理循环中出现错误时的应对方法,默认为stop,即出现错误就停止,但是这样会导致已经计算的内容全部失效,还得重新算。另外还有两种方式,remove选项可以在遇到错误时自动移除错误项,pass可以在出现错误时跳过该项,后者的区别是会记录出现错误的位置。
变量作用域
函数内部的局部变量具有自身的作用域,在离开运行环境时将会失效,因此在并行计算过程中也要考虑到该问题。
一个R语言函数有自己的运行环境,通常顶层环境就是全局变量,在任意位置都可以调用,而函数内部变量无法在顶层环境使用。
如果在dopar结构在函数中,则不会主动加载全局环境中的变量。
x1 <- 1
x2 <- 2
f <- function(x1) {
foreach(i = 1:100, .combine = c) %dopar% {
x1 + x2 + i
}
}
比如,上面这个会报错x2无法找到,因为foreach只识别了f函数环境的变量,而不会识别全局环境的变量。修改方法是将x2作为f函数的参数,或者.export参数。
# 方法一
f <- function(x1, x2) {
foreach(i = 1:3, .combine = c) %dopar% {
x1 + x2 + i
}
}
# 方法二
f <- function(x1) {
foreach(i = 1:3, .combine = c, .export = 'x2') %dopar% {
x1 + x2 + i
}
}
如何提前下班?
数据分析除了写代码,还离不开复杂的计算过程,有时候一个步骤的执行耗时好久,不得不加班!那么如何才能加速计算时间,每天早点下班呢?
CPU和内存的权衡
R语言并行计算的内存消耗量很大,因为R语言计算时都需要将数据全部加载到内存中进行操作。

适当的选择核心数量和内存大小,防治任务意外卡死。主要的解决方法是提高配置(钞能力)或者将一个大任务切分成若干小任务。
超线程不要太压榨
现在的处理器基本都实现了超线程的功能,在运行并行任务时不要一次性设置全部线程,不然速度不增反降。

对于支持超线程的CPU,并行计算时建议选择物理核心数量的1.5倍为上限,可以用detectCores(logical = F)命令查看自己电脑的物理核心数量
结论
并行计算为我们提供了一种有效地利用多核CPU的方法,从而加速数据处理速度。在R中,我们可以使用parallel和foreach包轻松实现并行计算,当处理大量数据时,建议尝试并行计算以提高效率。
最后,希望这篇文章能帮助大家更好地理解R语言中的并行计算技术。如果有任何建议,请后台留言或私信,感谢大家的阅读,欢迎分享和点赞!
参考资料
https://blog.csdn.net/u011375991/article/details/131272023

本文由 mdnice 多平台发布
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











