









回归分析
最小二乘法和极大似然估计 :思路不同推出同一个公式
最小二次法是均方误差最小化进行模型求解,极大似然估计则是利用了联合分布及似然函数 得到公式
$ E_{(w,b)}= $
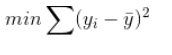
利用最优化的思路当$ E_{(w,b)}= $最小时w,b的值
求解方法包括梯度下降法,根据推到公式直接解
损失函数:逐点计算平方损失误差,然后求平均数
导数: 西瓜书上 公式3.30,
这几个方法都没有用牛顿法,海森矩阵计算比较复杂,梯度下降法基本上就是乘了一个学习率,如果用海森矩阵不需要用学习率,相当于一个渐变步长的学习率,下降速度更快。
数据载入
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
X,y = datasets.load_iris(return_X_y=True)
X= X[:,0]
X.shape
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
一元回归
直接解
def formula_calculate(X,y):
m=len(X)
X_mean=np.mean(X)
y_mean=np.mean(y)
w=np.sum(np.multiply(y,X-X_mean)/(np.sum(np.multiply(X,X))-np.sum(X)*np.sum(X)/m))
b=y_mean-w*X_mean
return w,b
formula_calculate(X_train,y_train)
plt.scatter(X_train,y_train)
# plt.plot(X_test,0.76*X_test-3.47)
plt.plot(X_test,0.37*X_test-1.15)
梯度下降法
损失函数是系数的函数,另外还要传入数据的x,y
参考链接
def compute_cost(w, b, points):
total_cost = 0
M = len(points)
# 逐点计算平方损失误差,然后求平均数
for i in range(M):
x = points[i, 0]
y = points[i, 1]
total_cost += ( y - w * x - b ) ** 2
return total_cost/M
def grad_desc(points, initial_w, initial_b, alpha, num_iter,cost_limi):
w = initial_w
b = initial_b
# 定义一个list保存所有的损失函数值,用来显示下降的过程
cost_list = []
for i in range(num_iter):
cost = compute_cost(w, b, points)
cost_list.append( cost )
w, b = step_grad_desc( w, b, alpha, points )
if cost<=cost_limi:
break
return [w, b, cost_list]
def step_grad_desc( current_w, current_b, alpha, points ):
sum_grad_w = 0
sum_grad_b = 0
M = len(points)
# 对每个点,代入公式求和
for i in range(M):
x = points[i, 0]
y = points[i, 1]
# w 和b 的导数
sum_grad_w += ( current_w * x + current_b - y ) * x
sum_grad_b += current_w * x + current_b - y
# 用公式求当前梯度
grad_w = 2/M * sum_grad_w
grad_b = 2/M * sum_grad_b
# 梯度下降,更新当前的w和b
updated_w = current_w - alpha * grad_w
updated_b = current_b - alpha * grad_b
return updated_w, updated_b
initial_w=0
initial_b=0
alpha=0.01
num_iter=10000
points = np.array([X_train,y_train]).T
cost_limi=0.1
li_x=grad_desc(points, initial_w, initial_b, alpha, num_iter,cost_limi)
多元回归
多元直接解
X,y = datasets.load_iris(return_X_y=True)
def Multi_calculate(X,y):
num_feature=X.shape[1]
beta = np.ones((num_feature+1))
X = np.c_[X,np.ones(len(X))]
beta=np.dot(np.dot(np.linalg.pinv(np.dot(X.T,X)),X.T),y)
return beta
Multi_calculate(X_train,y_train)
梯度下降法
参考链接
def compute_cost(beta,X,Y):
'''计算当前损失函数值 ,平方损失误差的平均
input: X:
beta : w 和 b
Y: 实际值 label
output: err/m(float): 错误率
'''
X = np.c_[X,np.ones(len(X))]
total_cost= np.mean(np.power( Y - np.dot(X,beta),2 ))
return total_cost
def grad_desc(X,Y, alpha, num_iter,cost_limi=0):
'''梯度下降
input: X,Y
alpha:学习率
num_iter: 最大迭代次数
cost_limi:最小损失值
output: list,list[1]:更新后的beta,损失函数的list
'''
num_feature=X.shape[1]
beta = np.ones((num_feature+1))
X = np.array(X)
Y = np.array(Y)
# 定义一个list保存所有的损失函数值,用来显示下降的过程
cost_list = []
for i in range(num_iter):
cost = compute_cost(beta ,X,Y )
if i==0:
cost_between=cost_limi+1
else:
cost_between=np.abs(cost_list[-1]-cost)
cost_list.append(cost)
beta = step_grad_desc( beta, alpha, X,Y )
if cost_between<=cost_limi:
break
return [beta, cost_list]
def step_grad_desc( current_beta, alpha, X,Y ):
'''梯度更新
input: X,Y
current_beta :现在的 w 和 b
alpha:学习率
output: updated_beta: 更新后的 w 和 b'''
# 求导数,南瓜书14页
M = len(X)
X = np.c_[X,np.ones(len(X))]
# /M 是因为用M个样本更新的参数,要得到的是每个样本的参数,所以需要除以样本数
# 可以不除以M但是相对学习率需要下降几个数量级否则可能不收敛
grad_beta= 2*np.dot(X.T,np.dot(X,current_beta)-Y)/M
# print(grad_beta)
# 梯度下降,更新当前的w和b
updated_beta = current_beta - alpha * grad_beta
return updated_beta
initial_w=0
initial_b=0
alpha=0.01
num_iter=40000
X=X_train
Y=y_train
cost_limi=0
li_x=grad_desc(X,Y, alpha, num_iter,cost_limi)
sklearn
# from sklearn.model_selection import train_test_split
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
from sklearn.linear_model import LinearRegression
regressor = LinearRegression() # 创建回归器
regressor.fit(X_train, y_train) # 用训练集去拟合回归器
# Predicting the Test set results
y_pred = regressor.predict(X_test) #获得预测结果
迭代次数增加之后结果基本没差别
| 公式直接解 | 梯度下降 | sklearn |
|---|---|---|
| array([-0.10627533, -0.0397204 , 0.22894234, 0.61123074, 0.16149541]) | array([-0.10646638, -0.03981776, 0.22896909, 0.61130829, 0.16272824]) | [array([-0.10627533, -0.0397204 , 0.22894234, 0.61123074]), 0.16149541375178667] |
梯度下降明显不如直接解公式和sklearn 的运行速度快
逻辑回归
逻辑回归西瓜树上有详细的公式可以参考这里不再列出
二分类
梯度下降
# 非线性可以用梯度下降,二分类问题
# https://blog.csdn.net/Weary_PJ/article/details/107380387
# 公式可以参考 :https://blog.csdn.net/Weary_PJ/article/details/107589709
def sigmoid(x):
''' Sigmoid函数
input: x(mat): feature * w
output: sigmoid(x)(mat): Sigmoid值
'''
return 1/(1+np.exp(-x))
def gradient_descent_batch(current_w, alpha,h, X,Y):
'''梯度更新和损失值
input: X,Y
current_w :现在的 w 和 b
alpha:学习率
output: updated_beta: 更新后的 w 和 b
err: 错误率'''
h = sigmoid(np.dot(X,current_w))
# 损失函数
cost= -np.mean(label_data*np.log(h) +\
(1 - label_data) * np.log(1 - h))
error = Y - h
w = current_w + alpha *np.dot(X.T,error) # 权值修正 batch gradient descent
return w,cost
def optimal_model_batch(feature_data, label_data,cost_limi, epoch, alpha):
'''利用梯度下降法训练LR模型
input: feature_data(mat)样例数据
label_data(mat)标签数据
epoch(int)训练的轮数
alpha(float)学习率
output: w(mat):权重
'''
X = np.c_[feature_data,np.ones(len(feature_data))]
y = label_data
n = np.shape(feature_data)[1] # 特征个数
w = np.ones((n+1)) # 初始化权重
i = 0
li_cost=[]
while i <= epoch:
i += 1
# sigma函数
w,cost = gradient_descent_batch(w, alpha,h, X,y) #梯度更新
if i==1:
cost_between=cost_limi+1
else:
cost_between= np.abs(li_cost[-1]-cost)
li_cost.append(cost)
if i % 100 == 0:
print("\t-----iter = " + str(i) + \
", train error rate = " + str(errorl))
elif cost_between<=cost_limi:
print("\t-----iter = " + str(i) + \
", train error rate = " + str(errorl))
break
return w,li_cost
y1 = y_train[(y_train==1)|(y_train==0)]
X1= X_train[(y_train==1)|(y_train==0),:]
alpha=0.01
num_iter=40000
X=X1
Y=y1
cost_limi=0.0001
li_x=lr_train_bgd(X,Y,cost_limi, num_iter, alpha)
plt.plot(li_x[1][:150])
sklearn
# sklearn
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(penalty='none',solver="sag",tol=cost_limi)
clf.fit(X,Y)
[clf.coef_,clf.intercept_]
结果相差比较大,主要是逻辑回归方法太多了找不到针对的方法
多元多分类
损失函数
J ( W ) = − 1 m [ ∑ i = 1 m ∑ j = 1 k I { y ( i ) = j } log e W j T X ( i ) ∑ l = 1 k e W l T X ( i ) ] J(W) = -\frac{1}{m} \left [\sum_{i=1}^{m} \sum_{j=1}^{k} I \{ y^{(i)}=j \} \log \frac{e^{W_j^TX^{(i)}}}{\sum _{l=1}^{k}e^{W_l^TX^{(i)}}} \right ] J(W)=−m1[i=1∑mj=1∑kI{y(i)=j}log∑l=1keWlTX(i)eWjTX(i)]
导数 求的是 θ j \theta _j θj的偏导
∂
J
(
θ
)
∂
θ
j
=
−
1
m
[
∑
i
=
1
m
▽
θ
j
{
∑
j
=
1
k
I
(
y
(
i
)
=
j
)
log
e
θ
j
T
X
(
i
)
∑
l
=
1
k
e
θ
l
T
X
(
i
)
}
]
\frac{\partial J(\theta )}{\partial \theta _j} = -\frac{1}{m}\left [ \sum_{i=1}^{m}\triangledown _{\theta_j}\left \{ \sum_{j=1}^{k}I(y^{(i)}=j) \log\frac{e^{\theta_j^TX^{(i)}}}{\sum _{l=1}^{k}e^{\theta_l^TX^{(i)}}} \right \} \right ]
∂θj∂J(θ)=−m1[i=1∑m▽θj{j=1∑kI(y(i)=j)log∑l=1keθlTX(i)eθjTX(i)}]
如果
y
(
i
)
=
j
y^{(i)}=j
y(i)=j
∂
J
(
θ
)
∂
θ
j
=
−
1
m
∑
i
=
1
m
[
(
1
−
e
θ
j
T
X
(
i
)
∑
l
=
1
k
e
θ
l
T
X
(
i
)
)
X
(
i
)
]
\frac{\partial J(\theta )}{\partial \theta _j} = -\frac{1}{m}\sum_{i=1}^{m}\left [\left ( 1-\frac{e^{\theta_j^TX^{(i)}}}{\sum _{l=1}^{k}e^{\theta_l^TX^{(i)}}} \right )X^{(i)} \right ]
∂θj∂J(θ)=−m1i=1∑m[(1−∑l=1keθlTX(i)eθjTX(i))X(i)]
如果
y
(
i
)
≠
j
y^{(i)}\neq j
y(i)=j
∂
J
(
θ
)
∂
θ
j
=
−
1
m
∑
i
=
1
m
[
(
−
e
θ
j
T
X
(
i
)
∑
l
=
1
k
e
θ
l
T
X
(
i
)
)
X
(
i
)
]
\frac{\partial J(\theta )}{\partial \theta _j} = -\frac{1}{m}\sum_{i=1}^{m}\left [\left ( -\frac{e^{\theta_j^TX^{(i)}}}{\sum _{l=1}^{k}e^{\theta_l^TX^{(i)}}} \right )X^{(i)} \right ]
∂θj∂J(θ)=−m1i=1∑m[(−∑l=1keθlTX(i)eθjTX(i))X(i)]
参考链接1,链接2
def softmax(a,k):
c = np.max(a,axis=1)
exp_a = np.exp(a - (np.ones([k,1])*c).T) # 防止溢出的对策
sum_exp_a = np.sum(exp_a,axis=1)
y = exp_a / (np.ones([k,1])*sum_exp_a).T
return y
def gradient_descent_batch(current_w, alpha,k, X,Y):
'''梯度更新和损失值
input: X,Y
current_w :现在的 w 和 b
alpha:学习率
output: updated_beta: 更新后的 w 和 b
err: 错误率'''
h = softmax(np.dot(X,current_w),k)
# 损失函数
cost= -np.mean(np.eye(k)[Y]*np.log(h))
error = np.eye(k)[Y] - h
w = current_w + (alpha/len(X))*np.dot(X.T,error) # 权值修正 batch gradient descent
return w,cost
def optimal_model_batch(feature_data, label_data,cost_limi, epoch, alpha):
'''利用梯度下降法训练LR模型
input: feature_data(mat)样例数据
label_data(mat)标签数据
epoch(int)训练的轮数
alpha(float)学习率
output: w(mat):权重
'''
k=np.unique(label_data).shape[0]
X = np.c_[feature_data,np.ones(len(feature_data))]
y = label_data
n = np.shape(feature_data)[1] # 特征个数
w = np.ones([n+1,k]) # 初始化权重
i = 0
li_cost=[]
while i <= epoch:
i += 1
# sigma函数
w,cost = gradient_descent_batch(w, alpha,k, X,y) #梯度更新
if i==1:
cost_between=cost_limi+1
else:
cost_between= np.abs(li_cost[-1]-cost)
li_cost.append(cost)
if i % 100 == 0:
print("\t-----iter = " + str(i) + \
", train error rate = " + str(cost))
elif cost_between<=cost_limi:
print("\t-----iter = " + str(i) + \
", train error rate = " + str(cost))
break
return w,li_cost
X,y = datasets.load_iris(return_X_y=True)
alpha=0.1
num_iter=40000
X=X_train
Y=y_train
cost_limi=0.000001
li_x=optimal_model_batch(X,Y,cost_limi, num_iter, alpha)
sklearn
# sklearn
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(penalty='none',solver="sag",multi_class="multinomial",tol=cost_limi)
clf.fit(X,Y)
[clf.coef_,clf.intercept_]
LDA 线性判别
其实线性判别和PCA有很大的相似之处,尤其都是针对某一个矩阵求解方程,但是在线性判别分析中特征向量有明确的意义是针对d维数据的d’投影,尤其是使类与类之间差别最大的结果,所以是一种监督降维的方法
对于多分类问题LDA:
W是
S
w
−
1
S
b
S_{w}^{-1}S_{b}
Sw−1Sb的d’个最大非零广义特征值多对应的特征向量组成的矩阵 d’<=N-1
引用链接 基本没有改动
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
def LDA_dimensionality(X, y, k):
'''
X为数据集,y为label,k为目标维数
'''
label_ = list(set(y))
X_classify = {}
# 每一类对应的样本
for label in label_:
Xi = np.array([X[i] for i in range(len(X)) if y[i] == label])
X_classify[label] = Xi
mju = np.mean(X, axis=0)
mju_classify = {}
# 每一类的mju
for label in label_:
mjui = np.mean(X_classify[label], axis=0)
mju_classify[label] = mjui
# 计算类内散度矩阵
# Sw = np.dot((X - mju).T, X - mju)
Sw = np.zeros((len(mju), len(mju)))
for i in label_:
Sw += np.dot((X_classify[i] - mju_classify[i]).T,
X_classify[i] - mju_classify[i])
# 计算类间散度矩阵
# Sb=St-Sw
Sb = np.zeros((len(mju), len(mju)))
for i in label_:
Sb += len(X_classify[i]) * np.dot((mju_classify[i] - mju).reshape(
(len(mju), 1)), (mju_classify[i] - mju).reshape((1, len(mju))))
eig_vals, eig_vecs = np.linalg.eig(
np.linalg.inv(Sw).dot(Sb)) # 计算Sw-1*Sb的特征值和特征矩阵
# 按从小到大排序,输出排序指示值
sorted_indices = np.argsort(eig_vals)
# 反转
sorted_indices = sorted_indices[::-1]
# 提取前k个特征向量
topk_eig_vecs = eig_vecs[:, sorted_indices[0:k:1]]
"""https://blog.csdn.net/qq_41973536/article/details/82690242
s[i:j:k],i起始位置,j终止位置,k表示步长,默认为1
s[::-1]是从最后一个元素到第一个元素复制一遍(反向)
"""
"""也可使用如下方法"""
# # 按从小到大排序,输出排序指示值
# sorted_indices = np.argsort(eig_vals)
# # 提取前k个特征向量
# topk_eig_vecs = eig_vecs[:, sorted_indices[:-k - 1:-1]]
return topk_eig_vecs
if '__main__' == __name__:
iris = load_iris()
X = iris.data
y = iris.target
W = LDA_dimensionality(X, y, 2)
X_new = np.dot((X), W) # 估计值
plt.figure(1)
plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y)
plt.title("LDA reducing dimension - our method")
plt.xlabel("x1")
plt.ylabel("x2")
# 与sklearn中的LDA函数对比
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X, y)
X_new = lda.transform(X)
X_new = - X_new # 为了对比方便,取个相反数,并不影响分类结果
print(X_new)
plt.figure(2)
plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y)
plt.title("LDA reducing dimension - sklearn method")
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









