







机器学习|决策树:数学原理及代码解析
决策树是一种常用的监督学习算法,适用于解决分类和回归问题。在本文中,我们将深入探讨决策树的数学原理,并提供 Python 示例代码帮助读者更好地理解和实现该算法。
决策树数学原理
决策树根据特征的取值对数据进行递归地划分,直到达到预定义的停止条件。每个节点代表一个特征,每个分支代表一个特征值,叶子节点表示一个类别或预测值。
决策树的构建依赖于两个主要的指标:信息熵和信息增益。信息熵衡量了数据集的纯度,信息增益衡量了使用某个特征进行划分后的纯度提升程度。
决策树示例代码
下面是使用 Python 编写的一个简单的决策树示例代码:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 构建决策树模型
clf = DecisionTreeClassifier()
clf.fit(X, y)
# 绘制决策树图形
plt.figure(figsize=(10, 6))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=list(iris.target_names))
plt.show()
在示例代码中,我们首先通过 load_iris() 函数加载了鸢尾花数据集,并将特征保存在 X 中,类别保存在 y 中。然后,我们使用 DecisionTreeClassifier() 构建了一个决策树分类器,并通过调用 fit() 方法训练该模型。
最后,我们使用 plot_tree() 函数绘制了决策树的图形,并通过 plt.show() 方法显示出来。
该程序输出的图表
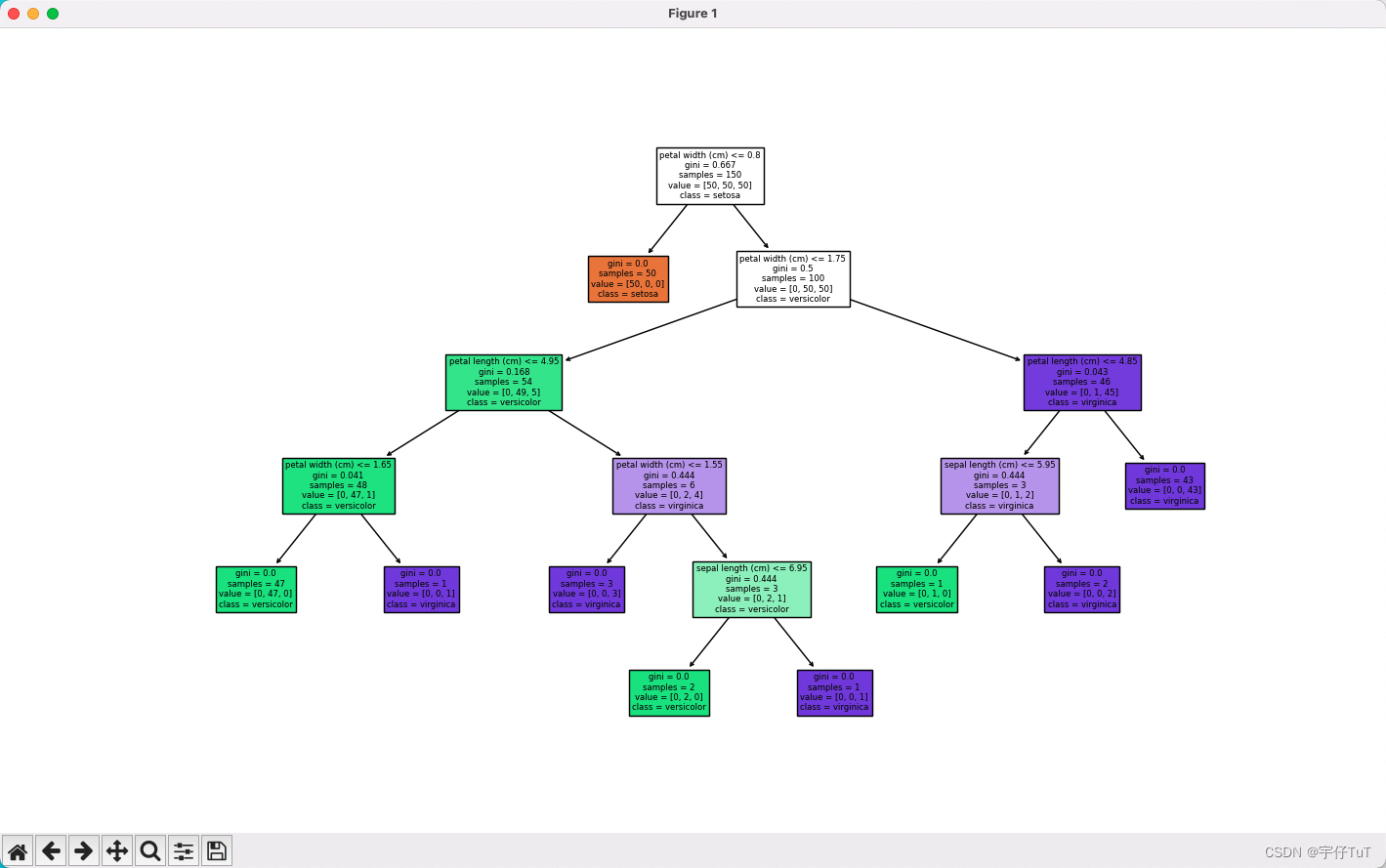
结语
通过本文,我们详细讲解了决策树的数学原理,并提供了一个简单的 Python 示例代码展示了如何实现和可视化决策树算法。希望本文能够帮助读者更好地理解决策树,并能够应用到实际问题中。
如果你对决策树或其他机器学习算法有任何疑问或想法,请在评论区留言,期待与大家的交流讨论!














 2071
2071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









