







 本文详细介绍了xgboost算法,它是一种基于GBDT的优化版提升树模型,适用于分类和回归任务。xgboost通过二阶泰勒展开优化目标函数,控制树的复杂度,使用动态的候选分裂点选择策略,以及处理稀疏数据的能力,使其在速度和效果上表现出色。文章还探讨了xgboost的参数调整,如objective和eval_metric等。
本文详细介绍了xgboost算法,它是一种基于GBDT的优化版提升树模型,适用于分类和回归任务。xgboost通过二阶泰勒展开优化目标函数,控制树的复杂度,使用动态的候选分裂点选择策略,以及处理稀疏数据的能力,使其在速度和效果上表现出色。文章还探讨了xgboost的参数调整,如objective和eval_metric等。
1、xgboost是什么
全称:eXtreme Gradient Boosting
基础:GBDT
所属:boosting迭代型、树类算法。
适用范围:分类、回归
优点:速度快、效果好、能处理大规模数据、支持多种语言、支 持自定义损失函数等等。
缺点:发布时间短(2014),工业领域应用较少,待检验
2、基础知识,GBDT
xgboost是在GBDT的基础上对boosting算法进行的改进,内部决策树使用的是回归树,简单回顾GBDT如下:
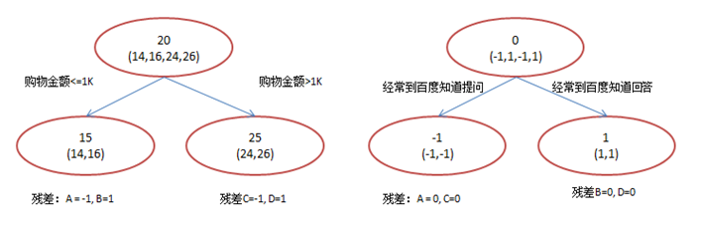
回归树的分裂结点对于平方损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,选取划分点。
最后预测的结果是每棵树的预测结果相加。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









