







Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(ANN)本身就是具有层次结构的系统,如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入I的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
具体过程简单的说明如下:
1)给定无标签数据,用非监督学习学习特征:
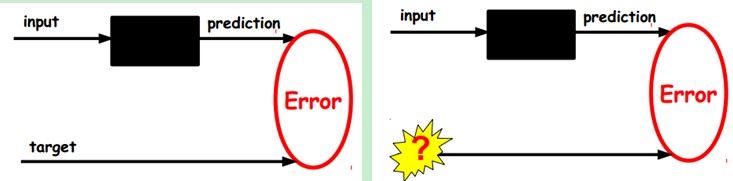
在我们之前的神经网络中,如第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target(label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?
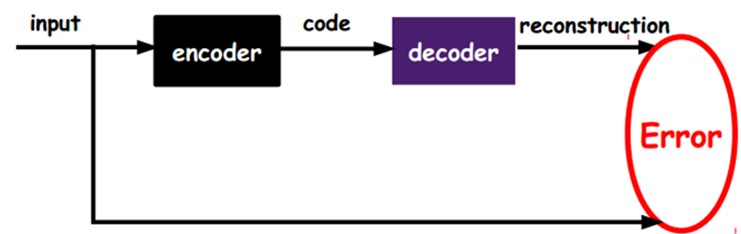
如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。
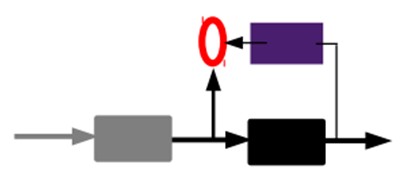
2)通过编码器产生特征,然后训练下一层。这样逐层训练:
那上面我们就得到第一层的code,我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的(表达不一样,反映的是一个东西)。那第二层和第一层的训练方式就没有差别了,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了(训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。
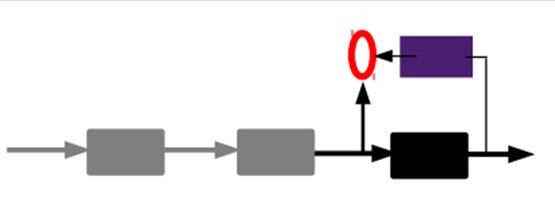
3)有监督微调:
经过上面的方法,我们就可以得到很多层了。至于需要多少层(或者深度需要多少,这个目前本身就没有一个科学的评价方法)需要自己试验调了。每一层都会得到原始输入的不同的表达。当然了,我们觉得它是越抽象越好了,就像人的视觉系统一样。
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。
也就是说,这时候,我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种,一个是只调整分类器(黑色部分):
另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)
一旦监督训练完成,这个网络就可以用来分类了。神经网络的最顶层可以作为一个线性分类器,然后我们可以用一个更好性能的分类器去取代它。
在研究中可以发现,如果在原有的特征中加入这些自动学习得到的特征可以大大提高精确度,甚至在分类问题中比目前最好的分类算法效果还要好!
一、稀疏编码器
Sparse AutoEncoder稀疏自动编码器:
当然,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
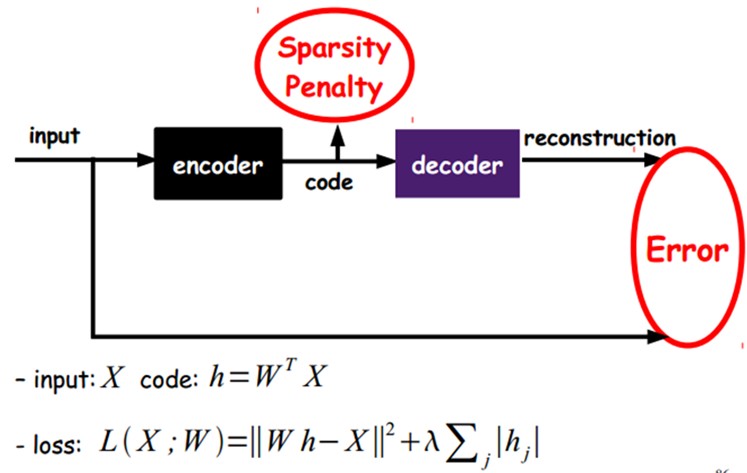
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
Sparse autoencoder的一个网络结构图如下所示:

损失函数的求法:
无稀疏约束时网络的损失函数表达式如下:

稀疏编码是对网络的隐含层的输出有了约束,即隐含层节点输出的平均值应尽量为0,这样的话,大部分的隐含层节点都处于非activite状态。因此,此时的sparse autoencoder损失函数表达式为:

后面那项为KL距离,其表达式如下:

隐含层节点输出平均值求法如下:

其中的参数一般取很小,比如说0.05,也就是小概率发生事件的概率。这说明要求隐含层的每一个节点的输出均值接近0.05(其实就是接近0,因为网络中activite函数为sigmoid函数),这样就达到稀疏的目的了。KL距离在这里表示的是两个向量之间的差异值。从约束函数表达式中可以看出,差异越大则”惩罚越大”,因此最终的隐含层节点的输出会接近0.05。
损失函数的偏导数的求法:
如果不加入稀疏规则,则正常情况下由损失函数求损失函数偏导数的过程如下:

而加入了稀疏性后,神经元节点的误差表达式由公式:

变成公式:

梯度下降法求解:
有了损失函数及其偏导数后就可以采用梯度下降法来求网络最优化的参数了,整个流程如下所示:

从上面的公式可以看出,损失函数的偏导其实是个累加过程,每来一个样本数据就累加一次。这是因为损失函数本身就是由每个训练样本的损失叠加而成的,而按照加法的求导法则,损失函数的偏导也应该是由各个训练样本所损失的偏导叠加而成。从这里可以看出,训练样本输入网络的顺序并不重要,因为每个训练样本所进行的操作是等价的,后面样本的输入所产生的结果并不依靠前一次输入结果(只是简单的累加而已,而这里的累加是顺序无关的)。
二、降噪编码器
当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),由Bengio在08年提出,见其文章Extracting and composing robust features with denoising autoencoders.使用dAE时,可以用被破坏的输入数据重构出原始的数据(指没被破坏的数据),所以它训练出来的特征会更鲁棒。本篇博文主要是根据Benigio的那篇文章简单介绍下dAE,然后通过2个简单的实验来说明实际编程中该怎样应用dAE。这2个实验都是网络上现成的工具稍加改变而成,其中一个就是matlab的Deep Learning toolbox,见https://github.com/rasmusbergpalm/DeepLearnToolbox,另一个是与python相关的theano,参考:http://deeplearning.net/tutorial/dA.html.
基础知识:
首先来看看Bengio论文中关于dAE的示意图,如下:

由上图可知,样本x按照qD分布加入随机噪声后变为 ,按照文章的意思,这里并不是加入高斯噪声,而是以一定概率使输入层节点的值清为0,这点与上篇博文介绍的dropout(Deep learning:四十一(Dropout简单理解))很类似,只不过dropout作用在隐含层。此时输入到可视层的数据变为,隐含层输出为y,然后由y重构x的输出z,注意此时这里不是重构 ,而是x.
Bengio对dAE的直观解释为:1.dAE有点类似人体的感官系统,比如人眼看物体时,如果物体某一小部分被遮住了,人依然能够将其识别出来,2.多模态信息输入人体时(比如声音,图像等),少了其中某些模态的信息有时影响也不大。3.普通的autoencoder的本质是学习一个相等函数,即输入和重构后的输出相等,这种相等函数的表示有个缺点就是当测试样本和训练样本不符合同一分布,即相差较大时,效果不好,明显,dAE在这方面的处理有所进步。
当然作者也从数学上给出了一定的解释。
1. 流形学习的观点。一般情况下,高维的数据都处于一个较低维的流形曲面上,而使用dAE得到的特征就基本处于这个曲面上,如下图所示。而普通的autoencoder,即使是加入了稀疏约束,其提取出的特征也不是都在这个低维曲面上(虽然这样也能提取出原始数据的主要信息)。

2.自顶向下的生成模型观点的解释。3.信息论观点的解释。4.随机法观点的解释。这几个观点的解释数学有一部分数学公式,大家具体去仔细看他的paper。
当在训练深度网络时,且采用了无监督方法预训练权值,通常,Dropout和Denoise Autoencoder在使用时有一个小地方不同:Dropout在分层预训练权值的过程中是不参与的,只是后面的微调部分引入;而Denoise Autoencoder是在每层预训练的过程中作为输入层被引入,在进行微调时不参与。另外,一般的重构误差可以采用均方误差的形式,但是如果输入和输出的向量元素都是位变量,则一般采用交叉熵来表示两者的差异。
三、收缩自动编码器
Contractive autoencoder是autoencoder的一个变种,其实就是在autoencoder上加入了一个规则项,它简称CAE(对应中文翻译为?)。通常情况下,对权值进行惩罚后的autoencoder数学表达形式为:

这是直接对W的值进行惩罚的,而今天要讲的CAE其数学表达式同样非常简单,如下:

其中的![]() 是隐含层输出值关于权重的雅克比矩阵,而
是隐含层输出值关于权重的雅克比矩阵,而 ![]() 表示的是该雅克比矩阵的F范数的平方,即雅克比矩阵中每个元素求平方
表示的是该雅克比矩阵的F范数的平方,即雅克比矩阵中每个元素求平方

然后求和,更具体的数学表达式为:

关于雅克比矩阵的介绍可参考雅克比矩阵&行列式——单纯的矩阵和算子,关于F范数可参考我前面的博文Sparse coding中关于矩阵的范数求导中的内容。
有了loss函数的表达式,采用常见的mini-batch随机梯度下降法训练即可。
关于为什么contrative autoencoder效果这么好?paper中作者解释了好几页,好吧,我真没完全明白,希望懂的朋友能简单通俗的介绍下。下面是读完文章中的一些理解:
好的特征表示大致有2个衡量标准:1. 可以很好的重构出输入数据; 2.对输入数据一定程度下的扰动具有不变形。普通的autoencoder和sparse autoencoder主要是符合第一个标准。而deniose autoencoder和contractive autoencoder则主要体现在第二个。而作为分类任务来说,第二个标准显得更重要。
雅克比矩阵包含数据在各种方向上的信息,可以对雅克比矩阵进行奇异值分解,同时画出奇异值数目和奇异值的曲线图,大的奇异值对应着学习到的局部方向可允许的变化量,并且曲线越抖越好(这个图没看明白,所以这里的解释基本上是直接翻译原文中某些观点)。
另一个曲线图是contractive ratio图,contractive ratio定义为:原空间中2个样本直接的距离比上特征空间(指映射后的空间)中对应2个样本点之间的距离。某个点x处局部映射的contraction值是指该点处雅克比矩阵的F范数。按照作者的观点,contractive ration曲线呈上升趋势的话更好(why?),而CAE刚好符合。
总之Contractive autoencoder主要是抑制训练样本(处在低维流形曲面上)在所有方向上的扰动。
四、栈式自动编码器
单自动编码器,充其量也就是个强化补丁版PCA,只用一次好不过瘾。
于是Bengio等人在2007年的 Greedy Layer-Wise Training of Deep Networks 中,
仿照stacked RBM构成的DBN,提出Stacked AutoEncoder,为非监督学习在深度网络的应用又添了猛将。
这里就不得不提 “逐层初始化”(Layer-wise Pre-training),目的是通过逐层非监督学习的预训练,
来初始化深度网络的参数,替代传统的随机小值方法。预训练完毕后,利用训练参数,再进行监督学习训练。

非监督学习网络训练方式和监督学习网络的方式是相反的。
在监督学习网络当中,各个Layer的参数W受制于输出层的误差函数,因而Layeri参数的梯度依赖于Layeri+1的梯度,形成了"一次迭代-更新全网络"反向传播。
但是在非监督学习中,各个Encoder的参数W只受制于当前层的输入,因而可以训练完Encoderi,把参数转给Layeri,利用优势参数传播到Layeri+1,再开始训练。
形成"全部迭代-更新单层"的新训练方式。这样,Layeri+1效益非常高,因为它吸收的是Layeri完全训练奉献出的精华Input。















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









