







MUST-GAN(用于自驱动人物图像生成的多级统计数 文献总结)
本文提出一种新的多级统计传输模型,该模型从人物图像中分离和传输多级外观特征,并将其与姿势特征合并,从而重建源人物图像本身。即源图像作为自我驱动的人物图像生产的监督。
具体来说,我们模型从外观编码器中提取多级特征,并通过注意机制和属性统计学习最佳外观表示。然后我们将它们转移到一个姿势引导生成器中,用于重新融合外观和姿势。
1.介绍
该论文提出的自驱动的人的图像生成方法,在训练中不使用任何成对的源目标图像。具体而言,该论文中提出了一种新的多层统计传输模型,该模型可以分离和传输人物图像的多层外观特征。
首先,使用外观编码器和姿势编码器分别从人物图像和姿势图像中提取特征。然后,引入MUST模块,从外观编码器中获得多级统计信息,并使用通道注意机制学习多级特征映射中每个通道的权重。然后,计算特征映射的统计量,并在将统计量传递到生成器分支时,应用多层全连通网络来学习对应关系。此外,我们还提出了一种用于姿势引导生成器的多级统计匹配网络,该网络由AdaIN中残差块的统计匹配和可学习的跳跃连接组成。该生成模块能够匹配多级统计的尺度和通道数,生成逼真的人物图像。
2.方法

为了实现只使用源人物图像和相应的姿势来实现自驱动的人物图像生成。本文提出了一个多级统计传输模型,它包含四个基本部分:两个分别用于人的外观和姿势的路径编码器,一个多级统计传输网络(MUST)和一个多级统计匹配生成器网络。
2.1姿势编码器
本文中采用经过训练的人姿势估计方法来获得人体姿势关节估计,将关节构造成为18通道热图Pa。再引入一个姿势连接图Pa_con,包含躯干和四肢,它与沿着通道维度的关节热图拼接,以帮助模型生成更精确的人体结构。对于姿势编码网络,使用下采样卷积神经网络和实例归一化,将关节热图和姿势连接图编码到高维空间,以引导生成网络。
2.2外观编码器
首先使用人物解析来获得输入人物图像的语义分割图Sa.然后,我们将语义映射合并为8个类,并在元素方面将它们与人物图像相乘,以获得Ia_parts。它将复杂的人的外观分割成几个部分,以便以后的特征提取和网络传输。外观编码器的目的:在不同的层次上提取丰富而健壮的特征,为后面的模块服务。本文中采用了COCO数据集中训练的VGG模型作为外观编码器
2.3多级统计传输

如上图所示,我们从外观编码器中选择从浅到深四个层次提取的特征。首先,利用通道注意力层学习每一层特征的自适应权重,然后通过卷积将特征映射的通道数减少到适合生成网络的大小。然后,提取每一个特征映射的统计信息(均值和方差)。
MUST可以简单地表示为:
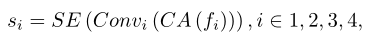
注:fi是特征映射,CA是通道注意层,SE是统计信息提取操作。
之后,利用一个多层全连接网络来转换提取的属性统计信息,以便网络在生成器中学习统计信息的映射。因此,完整的MUST的网络表示为:
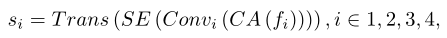
注:Trans代表多层完全连接网络的特征转换。
2.4多级统计匹配生成器
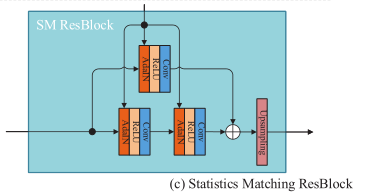
因为需要将统计信息映射到姿势引导的生成器,并在每个级别正确匹配特征的大小和通道,故提出了一个多级统计匹配生成器,它由四个统计匹配剩余块组成。如上图所示,首先,通过AdaIN将MUST获得的属性统计参数应用到生成器中,AdaIN规范化网络特征,并根据输入的统计参数调整特征映射的分布。其次,我们使用多级剩余块网络作为生成器的主干。最后利用1*1卷积层对人体图像进行重构,该卷积层融合了每个通道的特征。
2.5鉴别器
使用两个鉴别器:DI,DP,两种鉴别器都使用剩余块和下采样卷积层。
DI:人物图像
Dp:姿势图像,添加了一个姿势连接贴图输入Pa_con,它提供了姿势关节的相互关系,以生成更精确的人物图像姿势。















 1713
1713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









